正则表达式:如果想搜索/etc/passwd文件中以root开头的行,对与人来说很容易理解,但是对与计算机来说就无法理解,这个时候就需要使用正则表达式来表达过滤条件了,让用户实现对文本的智能搜索。正则表达式就是由元字符及正常字符所书写的模式,其中的元字符不表示字符本身的意义,而是用于表达控制或通配等功能。
正则表达式的特点是:
1. 灵活性、逻辑性和功能性非常的强;
2. 可以迅速地用极简单的方式达到字符串的复杂控制。
grep:支持正则表达式,是一个文本搜索工具,根据用户指定的文本模式(正则表达式元字符以及正常字符组合而成),对目标文件进行逐行搜索,显示能匹配到的行。
egrep:支持扩展正则表达式,扩展正则表达式使用的元字符比基本正则表达式支持的元字符多一些,功能也要更强一些
fgrep:不支持正则表达式,但是搜索速度更快。
[root@localhost ~]# cat /etc/redhat-release
CentOS release 6.6 (Final)
[root@localhost ~]# uname -rm
2.6.32-504.el6.x86_64 x86_64
grep语法:[OPTIONS] PATTERN [FILE...]
设置grep搜索显示颜色:
[root@localhost ~]# alias grep="grep--color"
注意:这种方法只是临时有效,重启后会丢失,把别名设置到开机启动文件中,重启系统之后依旧有效。
grep参数:
-v:表示取反
-i:不区分字符的大小写
-E:支持扩展正则表达式
-A:-A 2 显示指定行和指定行的后两行 中间使用两个横线分割
-B:显示匹配到前面的指定行数
-C:表示匹配到的内容的上下的指定行数
-o:只输出匹配内容
-n:在行首显示行号
演示说明:
-i 参数演示说明:在/etc/passwd中搜索ROOT, 不区分大小写,第一次搜索的是ROOT但是没有搜索到,添加-i参数之后就匹配到了root,说明搜索不区分大小写了。

-C 参数演示说明:搜索/etc/passwd中redhat参数和匹配内容的上下各一行。

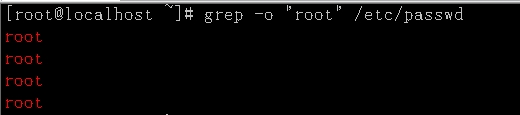
-o 参数演示说明:搜索/etc/passwd中root参数,非root内容不予显示。
-n 参数演示说明:输出匹配结果的行号。注意:这个行号不是按照匹配到的内容显示行号的,而是按照匹配行在文本中的所在行显示。

.:匹配任意单个字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
[abc] 匹配字符集合内任意一个字符[a-z]
[:space:]:空白字符
[:punct:]:标点符号
[:lower:]:小写字母
[:upper:]: 大写字母
[:alpha:]: 大小写字母
[:digit:]: 数字
[:alnum:]: 数字和大小写字母
实例:
".":实例演示说明:显示/etc/passwd文件中,r开头t结尾,中间跟两个任意字符。

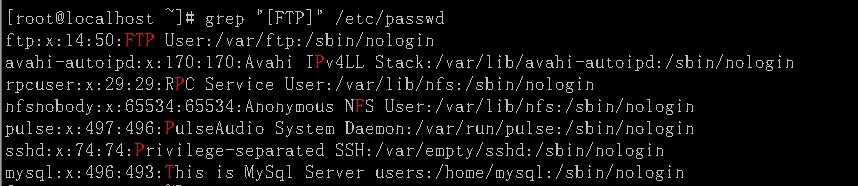
[]:实例演示说明:显示/etc/passwd文件中包含FTP字符的行。
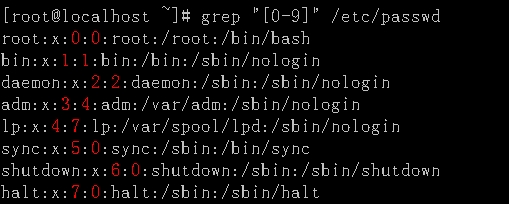
显示/etc/passwd文件中包含数字的行。
* :重复0个或多个前面的一个字符,匹配其前面字符任意次
.*:匹配所有字符。^.*任意多个字符开头
工作与贪婪模式,尽可能长的匹配。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。
\?:0次或1次;表示其左侧字符可有可无
\+:1次或多次
\{m\}: m次;表示其左侧字符精确出现m次
\{m,n\}:至少m次,至多n次;
演示:
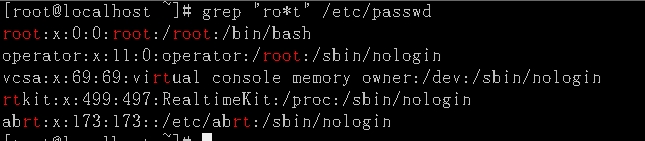
*:演示说明:显示/etc/passwd文件中r开头t结尾,中间要么出现包含o的内容,要么什么都不出现。
.*:演示说明:显示/etc/passwd文件中r0开头t结尾,中间出现任意长度的任意字符。

\?:演示说明:显示/etc/passwd文件中包含ro开头t结尾,中间的o要是要么不出现,要么出现一次的行。
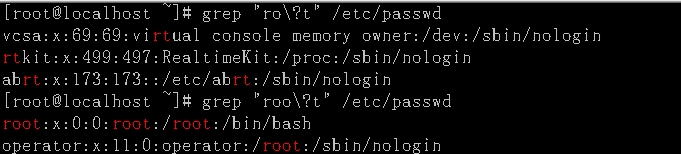
\+:演示说明:显示/etc/passwd文件中包含ro开头t结尾,中间的o出现过1次或多次的行。

\{m\}:演示说明:显示/etc/passwd文件中包含ro开头t结尾,中间的o出现两次的行。

^:行首
$:行尾
^$:匹配空白行
实例:
^:演示说明:显示/etc/passwd文件中以root开头的行

$:演示说明:显示/etc/passwd文件中以/bin/bash结尾的行
单词锚定:由非字符组成的连续的字符串
\<:锚定词首
\b:锚定词首
\>:锚定词尾,也可以用\b
\<PATTERN\>:匹配PATTERN能匹配到的单词
示例:
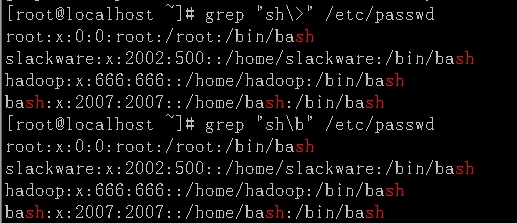
\<和\b:演示说明:显示/etc/passwd文件中以sh开头的单词

\>和\b: 演示说明:显示/etc/passwd文件中以sh结尾的单词
重复单个字符直接在字符后面加上限定符号即可,但是如果想重复多个字符就不是限定符号可以搞定的,这个时候就需要用到分组。
分组的模式:在某次的具体匹配过程中所匹配到的字符,可以被grep记忆(保存于内置的变量中,这些变量是\1,\2,……),因此,还可以被引用
实例说明:
把括号中的root当成一类字符,在加上*表示,roo要么显示一次,要么就不显示。
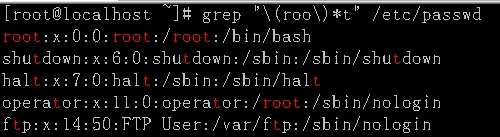
显示:r..t匹配到的字符在结尾在出现一次,也就是匹配以r..t开头,以r..t结尾的文件

找出/etc/passwd文件中的一位数或两位数;
# grep "\<[0-9]\{1,2\}\>" /etc/passwd
显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
# grep "^[[:space:]]\+" /boot/grub/grub.conf
显示/etc/rc.d/rc.sysinit文件中以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
# grep "^#[[:space:]]\+[^[:space:]]\+" /etc/rc.d/rc.sysinit
可以使用grep e或者egrep来使用
表示方法和grep一样,不在提供实例
.:匹配任意单个字符
[]:匹配指定范围内的任意单个字符
说明:扩展正则表达式的次数匹配前面不需要加转移字符。
*:任意次
?:0或1次
+:至少一次
{m}:精确匹配m次
{m,n}:至少m次,至多n次
{m,}:至少m次
{0,n}:至多次
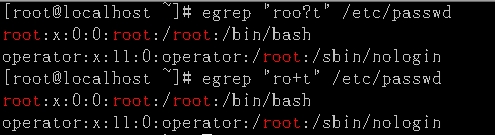
?和+:演示说明:和正则表达式的区别就在于没有加"\"
{}演示:同样也是没有加"\",使用起来方便了很多
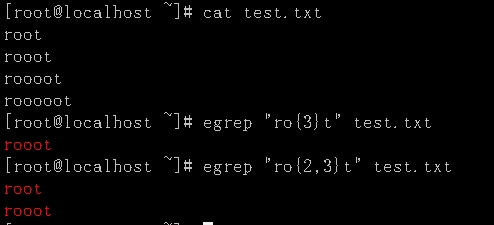
^:锚定行首
$:锚定行尾
\<,\b:锚定词首
\>,\b:锚定词尾
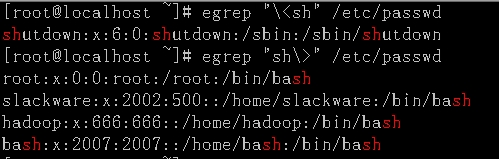
():不需要使用\转义
引用:
\1,\2,\3
显示/etc/passwd文件中root开头root结尾的行

这个是基本正则表达式所不具备的功能,意思是使用两个条件一起搜索,两个条件可以同时满足,也可以只满足其中一个,但是不能一个都无法满足。
a|b:a或者b
演示说明:显示/etc/passwd文件中的redhat和centos用户的信息。

显示/etc/passwd文件中redhat和fedora的信息,但是由于没有fedora的信息所以只显示了redhat用户的信息。

本文出自 “梅花香自苦寒来” 博客,请务必保留此出处http://ximenfeibing.blog.51cto.com/8809812/1627111
原文地址:http://ximenfeibing.blog.51cto.com/8809812/1627111