标签:
背景:实验室大数据分析需要得到社交网站的数据,首选当然是新浪。数据包括指定关键词、话题、位置的微博的内容。字段包括:图片、时间、用户、位置信息。
思路分析:要爬新浪的数据主要有2种方法:
1.微博开发者平台提供的微博API,资源包括微博内容、评论、用户、关系、话题等信息。同时,你也可以申请高级接口、商业接口获得更多权限,你要去注册申请成为开发者获得OAuth2授权以及这个使用参考,审核大约要1周。也可以直接使用别人分享的APPKEY。
优点是简单,有专门的问答社区,代码更新方便,可以获得real time的数据,对热门话题比较开放,返回的文档主要是json有很多现成的库类可以解析。 缺点是,数据受API规定,没有关键词检索,对不嗯呢该有访问次数限制,毕竟人家主要是服务微博的第三方应用,这个缺陷可以用更换上面的appkey来解决。
2.传统html爬虫,即发送http请求返回html源文件,再解析,提取里面的下级URL或者其他我们要的数据。C#.JAVA python都有相关的网页工具,c#主要是WebClient,或者HttpRequest/HttpResponse,也可以使用WebBrowser/page/htmldocument模拟浏览器操作,Java可以使用htmluint包。python对web处理的强大支持,使得网上的很多爬虫都是用python写的。
实现方法
由于实验室要采集的量比较大,就先选择第二种试试看。首先分析一下微博的网页。首先是按关键字搜索微博,可以使用高级搜索进行过滤,选着原创和含图片选项,过滤掉转发的重复内容和不含图片的微博。问题是改版后的微博搜索只能显示第一页,后面内容需要登陆才能看的。所以我们的爬虫程序首要通过登陆这一关。微博的验证码可以手动取消,位置如下图:
(42.png)
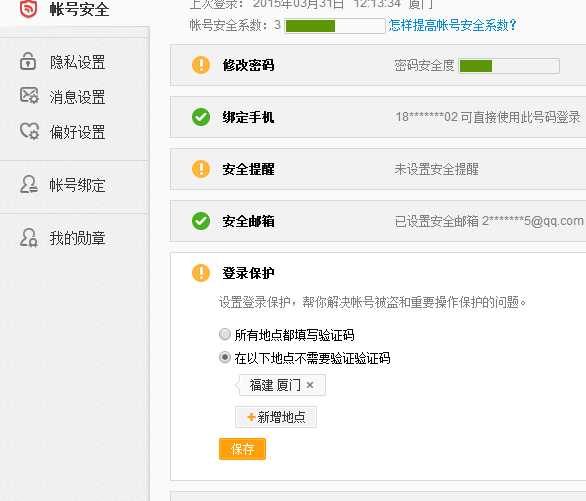
1.登陆
我知道的登陆的方法有3种。
1,模拟登陆过程。C#地webBrowser封装了操控浏览器的方法,根据ID获取HTML上的控件填充表单,点击登陆等,非常的人性化操作,但是需要识别验证码的代码。
2,模拟登陆POST,要用到抓包工具,比如burpsuite。这可能需要了解JS加密方法,以及验证码,具体网上找找。
3。第三种比较简单,模拟登陆后状态。到浏览器找与s.weibo.com连接的heards,提取COOKIE字段加入到代码作为heard一起发送request。具体是打开网站-》F12-》NetWor选项卡-》Documents / Scripts-》点个文件看看-》heards的Hosst是不是s.weibo.com,是的话把里面的cookie复制下来。注意cookie阁段时间会变化。由于只要登陆一次就能取数据,为了节省时间我就用了第三种方法。
2.获得html源文件
要获得源文件首先要向服务器发送访问请求。新浪微博搜索的URL是:http://s.weibo.com/wb/xiada&xsort=time 。仔细看会发现是像php命令风格的url:
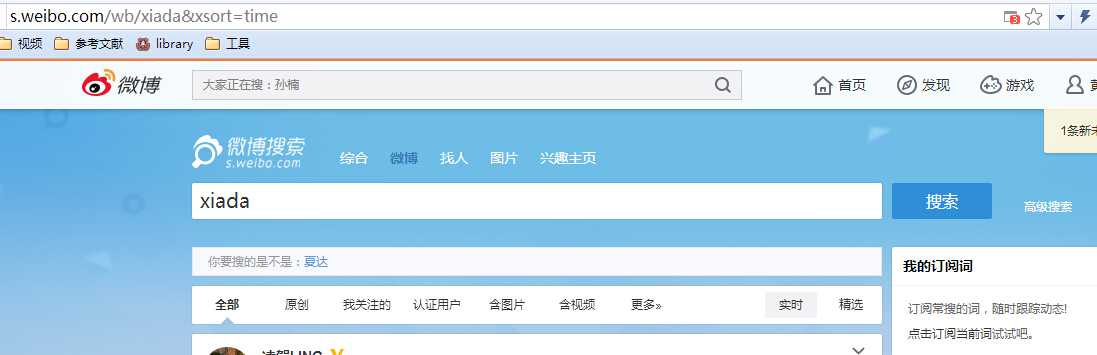
1.其中s.weibo.com是Host。 /wb/是指搜微博,综合搜索的话是/weibo/,找人的话是/user/,图片是/pic/。注意这里的搜的据我观察好像是用户使用发微博功能现拍的单图内容,所以内容少很多。
2.接着xiada就是搜索的关键词了,如果是中文关键词,这个字段就是经URLEncode编码的字符串。
3.Xsort=time 是搜索结果按时间排序,
4.page=2,就是页数了,没有写就是第一页啦。可以通过更换page=多少来实现翻页。
5.还有一些其他命令就不列举了,这些命令的可选值 都可以按"高级搜索" 选择你要的筛选条件再看看URL是什么样的就知道啦。
你可以做个界面让用户(也就是自己。。)来设置要搜什么样的微博。用HttpRequest 加上cookie 访问你通过上面命令生成的url,返回的就是网页源代码了。
3.解析html获取数据
最关键的步骤就是怎么提取你的文档,假如你用c#的WebBrowser 那么恭喜你可以直接用Document类把html装进去,通过getItemById()之类的方法,根据标签头,直接提取标签内容,非常之方便。我是用正则表达式去源代码字符串里匹配我要的数据(图片链接,下层链接)。正则表达式C#参考这个,总结的够清楚。
分析完这一样还要找下一页的超链接,在网页源码里搜"next",会发现只有一个,page next前面的herf="..."就是下一页的链接,可以根据这个来判断是不是最后一页。更快的方法是直接修改上面的命令page=n. 得到next page的url之后重复步骤2,3直到完成。
需要注意的是微博的反爬虫机制,如果你短时间内请求30次左右,不管你登陆与否,会被警告然后让你输入验证。解决方法要么推送到软件上手动输入,要么用浏览器手动输入,要么加个验证码识别模块。自动验证码识别这个可以用htmlunit实现,我还在研究中。
4.源码
这个程序适合入门学习,很多特性(存储策略,网络优化,性能)都没考虑进去,我这里贴出主要代码。主要部分实现细节可以参考http://www.cnblogs.com/Jiajun/archive/2012/06/16/2552103.html 这篇博客,思路大致一样,注释很详细,就是有点繁杂了,我借鉴了一点,非常之感谢。
另外有更多需求的同学可以去研究一下这个项目,在gihub有很多watch and fork,有API让你使用,而且有很多在爬到的数据可以下载,值得深入学习一下源码。

1 namespace IMT.weiboSpider
2 {
3 class Spider
4 {
5 #region field
6 public List<WB_Feed> feedList { get; set; }
7 private readonly object _locker = new object();
8 private ThreadManager mThreadManager;//workManager.dowork_handler=
9 public delegate void ContentsSavedHandler(string name);
10 public delegate void DownloadFinishHandler(int count);
11 public event ContentsSavedHandler ContentsSaved = null;
12 public event DownloadFinishHandler DownloadFinish = null;
13 public string _savePath;
14 public string _url;
15 public string _cookie;
16 public string _next_url;
17 public string _html;
18 public int _count_current_URL;
19 #endregion
20
21
22 /// <summary>
23 /// init
24 /// </summary>
25 public Spider()
26 {
27 feedList = new System.Collections.Generic.List<WB_Feed>();
28 mThreadManager = new ThreadManager(4);
29 mThreadManager.dowork_handler += new ThreadManager.Do_a_Work_Handler(GetIMGDownload);
30 }
31 /// <summary>
32 /// start working
33 /// </summary>
34 /// <param name="cookies"></param>
35 public void Start(string cookies)
36 {
37 _cookie = cookies;
38 Random rad=new Random();
39 _html=GetHtmlDownload(_url, _cookie);
40 _count_current_URL = GetHtmlPrased(_html);
41 _next_url = GetNextHtmlUrl(_html);
42 ContentsSaved.Invoke("url:[" + _url + "]IMG counts:" + _count_current_URL);
43 while (!string.IsNullOrEmpty(_next_url))
44 {
45 Thread.Sleep(rad.Next(1000,3000));
46 _html = GetHtmlDownload(_next_url, _cookie);
47 _count_current_URL = GetHtmlPrased(_html);
48 if (_count_current_URL < 2)
49 {
50 MessageBox.Show("需要手动刷新账号输入验证码,刷新后点再击确定");
51 continue;
52 }
53 ContentsSaved.Invoke("In The url:[" + _next_url + "]IMG counts:" + _count_current_URL);
54 _next_url = GetNextHtmlUrl(_html);
55
56 }
57
58
59 DialogResult dlresult = MessageBox.Show("fund image:" + feedList.Count, "ALL search result was prased and saveD in ./URLCollection.txt.\nContinue download?", MessageBoxButtons.YesNo);
60 switch (dlresult)
61 {
62 case DialogResult.Yes:
63 {
64 SaveURLBuffer(_savePath + "URLCollection.txt");
65 mThreadManager.DispatchWork();
66 break;
67 }
68 case DialogResult.No:
69 {
70 SaveURLBuffer(_savePath + "URLCollection.txt");
71 break;
72 }
73 }
74 //增加显示状态栏
75 }
76
77 /// <summary>
78 /// stop work
79 /// </summary>
80 public void Abort()
81 {
82 if (mThreadManager != null)
83 {
84 mThreadManager.StopWorking();
85 }
86 }
87
88 /// <summary>
89 /// save the imgages url to local
90 /// </summary>
91 /// <param name="filepath"></param>
92 public void SaveURLBuffer(string filepath)
93 {
94 FileStream fs = new FileStream(filepath, FileMode.Create, FileAccess.ReadWrite);
95 StreamWriter sw = new StreamWriter(fs);
96 foreach (var i in feedList)
97 sw.WriteLine(i.imgSrc);
98 sw.Flush();
99 sw.Close();
100 fs.Close();
101 }
102
103 #region 网页请求方法
104
105 /// <summary>
106 /// downloaad image in (index) work thread
107 /// </summary>
108 /// <param name="index"></param>
109 private void GetIMGDownload(int index)
110 {
111 string imgUrl = "";
112 try
113 {
114 lock (_locker)// lock feedlist access
115 {
116 if (feedList.Count <= 0)
117 {
118 mThreadManager.FinishWoking(index);
119 if (mThreadManager.IsAllFinished())
120 DownloadFinish(index);
121 return;
122 }
123 imgUrl = feedList.First().imgSrc;
124 feedList.RemoveAt(0);
125 }
126 string fileName = imgUrl.Substring(imgUrl.LastIndexOf("/") + 1);
127 WebClient wbc = new WebClient();
128 wbc.DownloadFileCompleted += new AsyncCompletedEventHandler(DownloadFileCallback);
129 wbc.DownloadFileAsync(new Uri(imgUrl), _savePath + fileName,fileName+"in task:"+index);
130 }
131 catch (WebException we)
132 {
133 System.Windows.Forms.MessageBox.Show("RequestImageFAIL" + we.Message + imgUrl + we.Status);
134 }
135 }
136
137 /// <summary>
138 /// call this when the img save finished
139 /// </summary>
140 /// <param name="sender"></param>
141 /// <param name="e"></param>
142 private void DownloadFileCallback(object sender, AsyncCompletedEventArgs e)
143 {
144 if (e.Error != null)
145 { //下载成功
146 // WebClient wbc=sender as WebClient;
147 // wbc.Dispose();
148 if(ContentsSaved!=null)
149 ContentsSaved((string)sender);
150 string msg=sender as string;
151 mThreadManager.FinishWoking((int)msg[msg.Length-1]);
152 mThreadManager.DispatchWork();
153 }
154 throw new NotImplementedException();//下载完成回调;
155 }
156
157 /// <summary>
158 /// get response html string
159 /// </summary>
160 /// <param name="wbUrl"></param>
161 /// <param name="heardCookie"></param>
162 /// <returns></returns>
163 public string GetHtmlDownload(string wbUrl, string heardCookie)
164 {
165 string url = wbUrl;
166 string Cookie = heardCookie;
167 string html = null;
168 WebClient client = new WebClient();
169 client.Encoding = System.Text.ASCIIEncoding.UTF8;
170 client.Headers.Add("Cookie", Cookie);
171
172 Stream data = client.OpenRead(url);
173
174 StreamReader reader = new StreamReader(data);
175 html = reader.ReadToEnd();
176 client.Dispose();
177 return html;
178 }
179
180 /// <summary>
181 /// prase html string return the picture url number in this page
182 /// </summary>
183 /// <param name="html"></param>
184 /// <returns></returns>
185 public int GetHtmlPrased(string html)
186 {
187 string _html = html;
188 string result;
189 int count=0;
190 Regex regex = new Regex(@"(?<=http)[^""]+(?=jpg)");
191 MatchCollection theMatches = regex.Matches(_html);
192 foreach (Match thematch in theMatches)
193 {
194 if (thematch.Length != 0)
195 {
196 result = "http" + thematch.Value.Replace("\\", "") + "jpg";
197
198 //TO DO : 定义匹配规则查找相同的微博。
199
200 feedList.Add(new WB_Feed(result));
201 count++;
202 }
203 }
204 return count;
205 }
206
207 /// <summary>
208 /// form the url commond to get next page
209 /// </summary>
210 /// <param name="url"></param>
211 /// <param name="num"></param>
212 /// <returns></returns>
213 public string GetNextHtmlUrlFromPageNUM(string url,int num)
214 {
215 string nextPage;
216 string preUrl = url;
217 int pageIdex = preUrl.IndexOf("page")+5;
218 nextPage=preUrl.Remove(pageIdex, 1);
219 nextPage = nextPage.Insert(pageIdex, "" + num);
220 return nextPage;
221 }
222 /// <summary>
223 /// prase html string to get the next page url
224 /// </summary>
225 /// <param name="html"></param>
226 /// <returns></returns>
227 public string GetNextHtmlUrl(string html)
228 {
229 string nextPage;
230 string s_domain;
231 string _html = html;
232
233 int nextIndex = _html.LastIndexOf("page next");//find last to be fast
234 if (nextIndex < 0)
235 {
236
237 MessageBox.Show("there is not nextpage");
238 return null;
239 }
240 //MessageBox.Show("find next in=" + nextIndex);
241 int herfIndex = _html.LastIndexOf("href=", nextIndex);
242 nextPage = _html.Substring(herfIndex + 5 + 2, nextIndex - herfIndex);
243 nextPage= nextPage.Substring(0, nextPage.IndexOf(@"""") - 1);
244 nextPage= nextPage.Replace("\\", "");
245 //$CONFIG[‘s_domain‘] = ‘http://s.weibo.com‘;
246 int domainIndex=html.IndexOf("‘s_domain‘");
247 domainIndex = html.IndexOf(‘=‘, domainIndex)+3;
248 int domainLength=html.IndexOf(";",domainIndex)-1-domainIndex;
249 s_domain = html.Substring(domainIndex, domainLength);
250
251 nextPage = s_domain + nextPage;
252 return nextPage;
253 }
254 #endregion
255
256
257
258 /// <summary>
259 /// work group manageer of downloading images with defult 4 work thread;
260 /// </summary>
261 private class ThreadManager
262 {
263 private bool[] _reqBusy = null; //每个元素代表一个工作实例是否正在工作
264 private int _reqCount = 4; //工作实例的数量
265 private bool _stop = true;
266 public delegate void Do_a_Work_Handler(int index);
267 public Do_a_Work_Handler dowork_handler;
268 public ThreadManager(int threadCount)
269 {
270 _reqCount = threadCount;
271 _reqBusy = new bool[threadCount];
272 for (int i=0;i<threadCount;i++)
273 {
274 _reqBusy[i] = false;
275 }
276 _stop = false;
277 }
278 public void StartWorking(int index)
279 {
280 _reqBusy[index] = true;
281 dowork_handler.Invoke(index);/////invoke requeset resource
282 }
283 public void FinishWoking(int index)
284 {
285 _reqBusy[index] = false;
286 }
287 public bool IsAllFinished()
288 {
289 bool done = true;
290 foreach (var i in _reqBusy)
291 done = i & done;
292 return done;
293 }
294 public void WaitALLFinished()
295 {
296 while (!IsAllFinished())
297 Thread.Sleep(1000);
298 }
299 public void StopWorking()
300 {
301 _stop = true;
302 for (int i = 0; i < _reqCount; i++)
303 _reqBusy[i] = false;
304 }
305 public void DispatchWork()
306 {
307 if (_stop)
308 return;
309 for (int i = 0; i < _reqCount; i++)////判断i编号的工作实例是否空闲
310 if (!_reqBusy[i])
311 StartWorking(i);
312 }
313 }
314 }
315
316 /// <summary>
317 /// the class of weibo data you can add more field for get more detail in codes
318 /// </summary>
319 public class WB_Feed
320 {
321 public WB_Feed(string img)
322 {
323 imgSrc = img;
324 }
325 public string imgSrc { get; set; }
326
327 }
328
329 }
标签:
原文地址:http://www.cnblogs.com/qingfengyiqu/p/4381623.html
