标签:
今天继续《高可用的Hadoop平台》系列,今天开始进行小规模的实战下,前面的准备工作完成后,基本用于统计数据的平台都拥有了,关于导出统计结果的文章留到后面赘述。今天要和大家分享的案例是一个基于电商网站的用户行为分析,这里分析的指标包含以下指标:
其他指标可以参考上述4个指标进行拓展,下面我们开始今天的分析之旅。
首先,在开发之前我们需要注意哪些问题?我们不能盲目的按照自己的意愿去开发项目,这样到头来得不到产品的认可,我们的工作又得返工。下面结合自身的工作,说说开发的具体流程:
在日志拉取过程,所欲问题和注意事项:如果日志量不大,我们可以直接使用python脚本或shell脚本直接将日志上传到HDFS,若是海量数据,那我们可以使用 flume 进行上传。具体选择那种上传方式取决于实际的业务,可按需选择。
注:若使用脚本上传,需考虑脚本的可读性和可维护性。
在日志预处理过程中需要注意事项:对字段进行翻译,反编译,解析等操作,以确保存入到 hive 表的是有效的有用的信息。
另外,在实际开发中,得和产品充分沟通过后,我们在开工;不然,到最后会引发一些不必要得麻烦。
开发流程图和之前介绍《网站日志统计案例分析与实现》得流程图类似,这里直接拿过来使用,如下图所示:
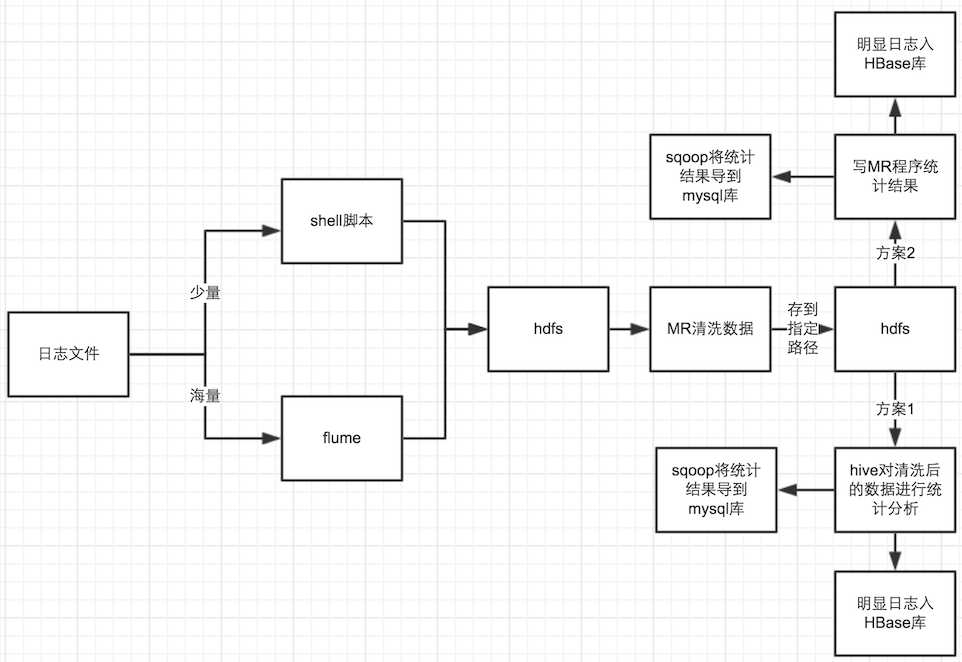
开发流程我们清楚来,需要统计得指标任务也明确了,接下来,我们开始进行编码阶段。首先,这里我赘述得是安装流程图得过程来的,若是在实际开发过程中,可根据实际情况来定,可以先独立的开发后面的模块,预留接口功能。不作限制,按需开发。
这里由于我本地只能连接到测试的集群上,而集群拉取的测试数据量很少,这里我就直接用 shell 脚本上传了。内容如下所示:
#! /bin/bash # get date param yesterday=$1 hadoop dfs -put /hdfs/logs/day/$1 /hdfs/logs/day/
然后上传脚本使用 crontab 来定时调度。
我们在确定 HDFS 存有数据后,对上传的日志进行清洗(或过滤),抽起对统计指标有用的数据源,并将数据源重定向到 HDFS 目录。,下面给出部分清洗代码,内容如下:
Map类:
/** * */ package cn.hdfs.mapreducer; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import cn.jpush.hdfs.utils.LogParserFactory; /** * @author dengjie * @date 2015年4月1日 * @description TODO */ public class LogMapper extends Mapper<LongWritable, Text, LongWritable, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { final String[] parsed = LogParserFactory.parse(value.toString()); // 过滤掉静态信息 if (parsed[2].startsWith("GET /static/") || parsed[2].startsWith("GET /uc_server")) { return; } // 过掉开头的特定格式字符串 if (parsed[2].startsWith("GET /")) { parsed[2] = parsed[2].substring("GET /".length()); } else if (parsed[2].startsWith("POST /")) { parsed[2] = parsed[2].substring("POST /".length()); } // 过滤结尾的特定格式字符串 if (parsed[2].endsWith(" HTTP/1.1")) { parsed[2] = parsed[2].substring(0, parsed[2].length() - " HTTP/1.1".length()); } String str = ""; for (int i = 0; i < parsed.length; i++) { if (i == (parsed.length - 1)) { str += parsed[i]; } else { str += parsed[i] + ","; } } context.write(key, new Text(str)); } }
Reduce类:
/** * */ package cn.hdfs.mapreducer; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * @author dengjie * @date 2015年4月1日 * @description TODO */ public class LogReducer extends Reducer<LongWritable, Text, Text, NullWritable> { @Override protected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text v : values) { context.write(v, NullWritable.get()); } } }
LogParserFactory类:
/** * */ package cn.hdfs.utils; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Locale; /** * @author dengjie * @date 2015年4月1日 * @description TODO */ public class LogParserFactory { public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); public static final SimpleDateFormat dateformat = new SimpleDateFormat("yyyyMMddHHmmss"); /** * 解析英文时间字符串 * * @param string * @return * @throws ParseException */ private static Date parseDateFormat(String string) { Date parse = null; try { parse = FORMAT.parse(string); } catch (Exception e) { e.printStackTrace(); } return parse; } /** * 解析日志的行记录 * * @param line * @return 数组含有5个元素,分别是ip、时间、url、状态、流量 */ public static String[] parse(String line) { String ip = parseIP(line); String time = parseTime(line); String url = parseURL(line); String status = parseStatus(line); String traffic = parseTraffic(line); return new String[] { ip, time, url, status, traffic }; } private static String parseTraffic(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1).trim(); String traffic = trim.split(" ")[1]; return traffic; } private static String parseStatus(String line) { final String trim = line.substring(line.lastIndexOf("\"") + 1).trim(); String status = trim.split(" ")[0]; return status; } private static String parseURL(String line) { final int first = line.indexOf("\""); final int last = line.lastIndexOf("\""); String url = line.substring(first + 1, last); return url; } private static String parseTime(String line) { final int first = line.indexOf("["); final int last = line.indexOf("+0800]"); String time = line.substring(first + 1, last).trim(); Date date = parseDateFormat(time); return dateformat.format(date); } private static String parseIP(String line) { String ip = line.split("- -")[0].trim(); return ip; } }
Main函数:
/** * */ package cn.hdfs.main; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import cn.jpush.hdfs.mapreducer.LogMapper; import cn.jpush.hdfs.mapreducer.LogReducer; import cn.jpush.hdfs.utils.ConfigUtils; /** * @author dengjie * @date 2015年4月1日 * @description 将清洗后的日志重新存放指定的hdfs上 */ public class LogCleanMR extends Configured implements Tool { @SuppressWarnings("deprecation") public int run(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://cluster1"); conf.set("dfs.nameservices", "cluster1"); conf.set("dfs.ha.namenodes.cluster1", "nna,nns"); conf.set("dfs.namenode.rpc-address.cluster1.nna", "10.211.55.26:9000"); conf.set("dfs.namenode.rpc-address.cluster1.nns", "10.211.55.27:9000"); conf.set("dfs.client.failover.proxy.provider.cluster1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"); final Job job = new Job(conf, LogCleanMR.class.getSimpleName()); job.setJarByClass(LogCleanMR.class); job.setMapperClass(LogMapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(LogReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, args[0]); FileOutputFormat.setOutputPath(job, new Path(args[1])); int status = job.waitForCompletion(true) ? 0 : 1; return status; } public static void main(String[] args) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy_MM_dd"); args = new String[] { ConfigUtils.HDFS.LOGDFS_PATH, String.format("/hdfs/logs/redirect/day/%s", sdf.format(new Date())) }; int res = ToolRunner.run(new Configuration(), new LogCleanMR(), args); System.exit(res); } }
清洗工作到这里就已经完成了,下面开始统计指标任务的开发。
在这里,由于 Java API 代码设计到实际的业务逻辑,我就直接使用 Hive SQL 来演示了统计结果了,若干有同学需要使用 Java API 来开发 Hive 应用,可参考《高可用Hadoop平台-集成Hive HAProxy》这篇博客,里面有讲到如何使用 Java API 来操作 Hive。下面我们使用 Hive SQL 来进行统计。内容如下:
建表:
CREATE EXTERNAL TABLE portal(ip string, atime string, url string,status int,traffic int)PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ LOCATION ‘/hdfs/logdfs/portal‘
创建分区:
ALTER TABLE portal ADD PARTITION(logdate=‘2015_01_02‘)
加载数据:
LOCATION ‘/hdfs/logdfs/portal/2015_01_02‘
注:LOCATION 关键字后面的路径是指定清洗后的的hdfs路径
下面创建临时统计表,各表如下所示:
创建每日PV表:
CREATE TABLE pv_2015_01_02 AS SELECT COUNT(1) AS PV FROM logdfs WHERE logdate=‘2015_01_02‘;
创建注册用户表:
CREATE TABLE reguser_2015_01_02 AS SELECT COUNT(1) AS REGUSER FROM logdfs WHERE logdate=‘2015_01_02‘ AND INSTR(url,‘signup‘)>0;
创建IP表:
CREATE TABLE ip_2015_01_02 AS SELECT COUNT(1) AS IP FROM (SELECT DISTINCT ip from logdfs WHERE logdate=‘2015_01_02‘) tmp
创建跳出用户表:
CREATE TABLE jumper_2015_01_02 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM logdfs WHERE logdate=‘2015_01_02‘ GROUP BY ip HAVING times=1) e;
最后我们将所有的结果汇总到一张 Hive 表,命令如下所示:
CREATE TABLE logdfs_2015_01_02 ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ AS SELECT ‘2015_01_02‘, a.pv, b.reguser, c.ip, d.jumper FROM pv_2015_01_02 a JOIN reguser_2015_01_02 b ON 1=1 JOIN ip_2015_01_02 c ON 1=1 JOIN jumper_2015_01_02 d ON 1=1 ;
关于 JOIN ... ON 用法不熟悉的同学,可以参考《Hive基本操作》这篇文章。
这样,我们对使用 Hive 基于 HDFS 平台进行数据分析统计的流程就完成了,这里也许会发现一个问题,操作 Hive SQL 命令出错率是很高的,后面带我将业务从 Java API 分离出来后,我会将操作 Hive 的 Java API 贴在这篇博客的后面。至于如何将统计的结果导出,后面会花一篇博客来赘述导出的流程。
这篇博客就和大家分享到这里,如果实际研究过程中有什么疑问,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4383839.html