标签:
安装环境:集群中包括3个节点,1个master,2个slave,节点之间通过局域网连接,可以相互ping通,并可以互相ssh免密码登陆。节点IP地址分布如下:
192.168.25.140 master
192.168.25.141 slave1
192.168.25.142 slave2
软件版本:
JDK版本:jdk-7u75-linux-i586.tar.gz
Hadoop版本:hadoop-2.6.0.tar.gz
Scala版本:scala-2.10.4.tgz
Spark版本:spark-1.3.0-bin-hadoop2.4.tgz
安装步骤:
一 解压文件
1 分别将JDK、Hadoop、Scala、Spark解压到/home/llh/hadoop目录下
2 在/etc/profile中追加以下内容:
export JAVA_HOME=/home/llh/hadoop/jdk1.7.0_75
export HADOOP_HOME=/home/llh/hadoop/hadoop-2.6.0
export SCALA_HOME=/home/llh/hadoop/scala-2.10.4
export SPARK_HOME=/home/llh/hadoop/spark-1.3.0-bin-hadoop2.4
export PATH=.:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
3 刷新配置文件使其生效
Source /etc/profile
二 配置Hadoop
1 配置hadoop-env.sh
export JAVA_HOME=/home/llh/hadoop/jdk1.7.0_75
2 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri‘s scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri‘s authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>
3 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/llh/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datannode.data.dir</name>
<value>/home/llh/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
</configuration>
5 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6 配置slaves
master
slave1
slave2
三 配置spark
1 配置spark-env.sh
export JAVA_HOME=/home/llh/hadoop/jdk1.7.0_75
export SCALA_HOME=/home/llh/hadoop/scala-2.10.4
export SPARK_MASTER_IP=192.168.25.140
export SPARK_WORKER_MEMORY=256M
export HADOOP_CONF_DIR=/home/llh/hadoop/hadoop-2.6.0/etc/hadoop
2 配置slaves
# A Spark Worker will be started on each of the machines listed below.
master
slave1
slave2
四 启动Hadoop
1 启动hdfs,执行sbin/start-dfs.sh
2 在浏览器中输入master:50070进入hdfs的web界面
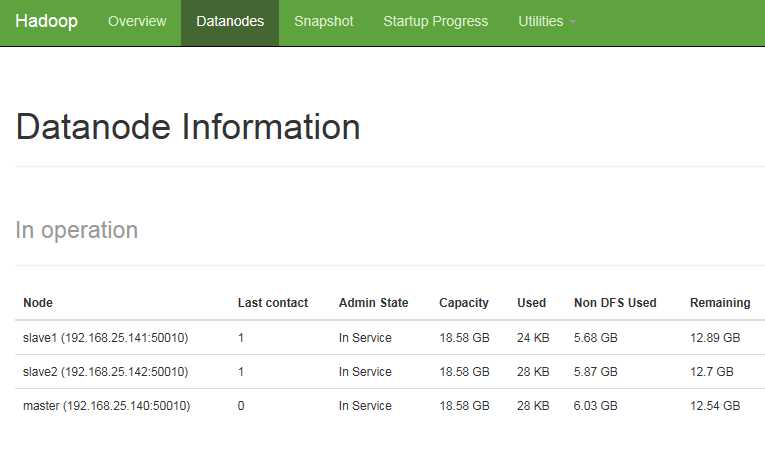
3 启动yarn,执行sbin/start-yarn.sh
4 在浏览器中输入master:8088进入yarn的web界面
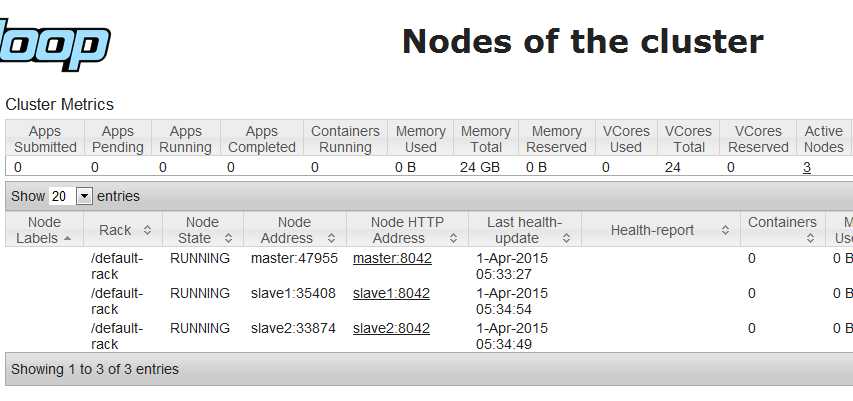
五 启动Spark
1 执行sbin/start-all.sh,启动的进程如下:
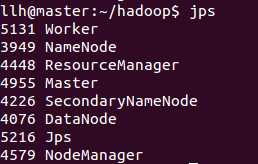
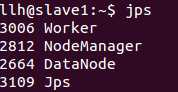
2 启动Spark Shell,执行bin/spark-shell
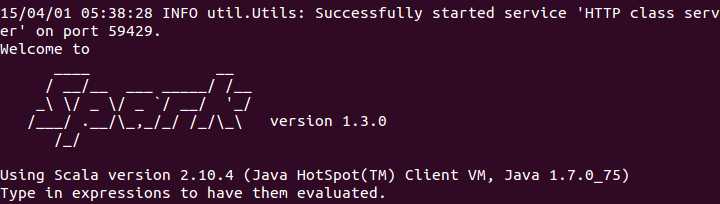
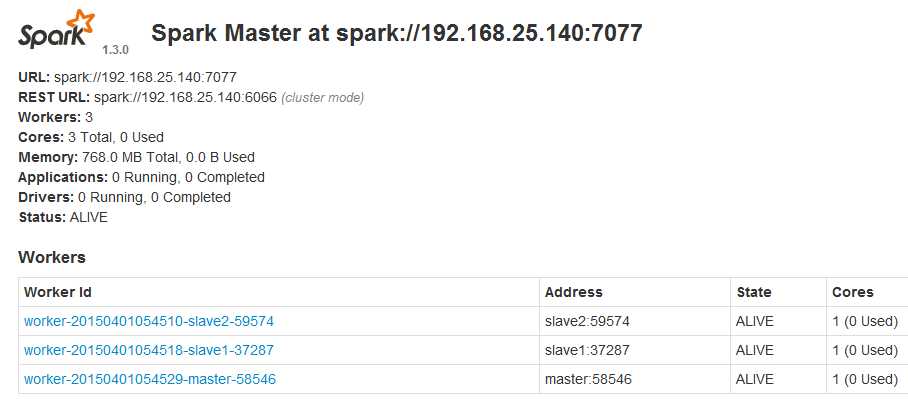
3在浏览器中输入master:8080进入Spark的web界面
标签:
原文地址:http://www.cnblogs.com/iceland/p/4386678.html