标签:

? ?

? ?

? ?

? ?

? ?

? ?

? ?
使用MapReduce
? ?

? ?

? ?

? ?
import java.io.IOException;
// 是hadoop针对流处理优化的类型
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
// 会继承这个基类
import org.apache.hadoop.mapred.MapReduceBase;
// 会实现这个接口
import org.apache.hadoop.mapred.Mapper;
// 处理后数据由它来收集
import org.apache.hadoop.mapred.OoutputCollector;
import org.apache.hadoop.mapred.Reporter;
? ?
// 虽然还没有开始系统学习java语法, 我猜测, extends是继承基类,
// implements 是实现接口, java把它们语法上分开了
public class MaxTemperatureMapper extends MapReduceBase
// Mapper是一个泛型接口
implements Mapper<LongWritable, Text, Text, IntWritable> {
? ?
? ?
Mapper是一个泛型接口:
? ?
Mapper<LongWritable, Text, Text, IntWritable>
它有4个形参类型, 分别是map函数的输入键, 输入值, 输出键和输出值的类型.
? ?
就目前来说, 输入键是长整数偏移量, 输入值是一行文本, 输出键是年份, 输出值是气温(整数).
? ?
Hadoop提供了一套可优化网络序列化传输的基本类型, 不直接使用java内嵌的类型. 在这里, LongWritable 相当于 Long, IntWritable 相当于 Int, Text 相当于 String.
? ?
map() 方法的输入是一个键和一个值.
? ?
map() 还提供了 OutputCollector 实例用于输出内容的写入.
? ?
? ?
? ?
reduce函数的输入键值对必须与map函数的输出键值对匹配.
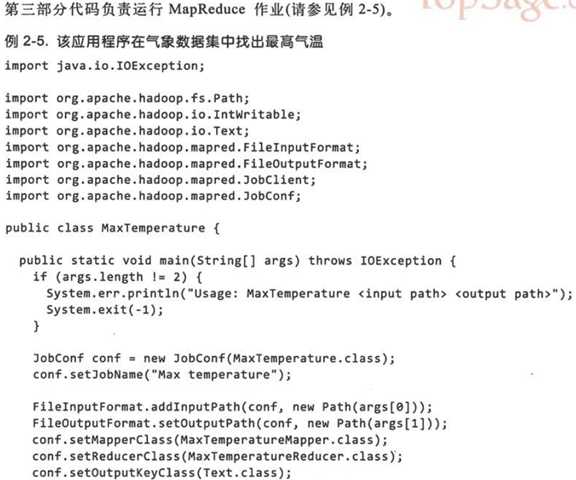
第三部分的代码为负责运行MapReduce的作业.
? ?
import java.io.IOException;
? ?
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
? ?
public class MaxTemperature {
? ?
public static void main(String[] args) throws IOException {
if(args.length !=2 ) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
? ?
JobConf conf = new JobConf(MaxTemperatuer.class);
conf.setJobName("Max temperature");
? ?
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(MaxTemperatuerMapper.class);
conf.setReducerClass(MaxTemperatuerReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
? ?
JobClient.runJob(conf);
}
}
? ?
? ?
JobConf 对象制定了作业的执行规范. 构造函数的参数为作业所在的类, Hadoop会通过该类来查找包含给类的JAR文件.
? ?
构造 JobConf 对象后, 制定输入和输出数据的路径. 这里是通过 FileInputFormat 的静态方法 addInputPath() 来定义输入数据的路径, 路径可以是单个文件, 也可以是目录(即目录下的所有文件)或符合特定模式的一组文件. 可以多次调用(从名称可以看出, addInputPath() ).
? ?
同理, FileOutputFormat.setOutputPath() 指定输出路径. 即写入目录. 运行作业前, 写入目录不应该存在, Hadoop会拒绝并报错. 这样设计, 主要是防止数据被覆盖, 数据丢失. 毕竟Hadoop运行的时间是很长的, 丢失了非常恼人.
? ?
FileOutputFormat.setOutputPath() 和 conf.setMapperClass() 指定map和reduce类型.
? ?
接着, setOutputKeyClass 和 setOutputValueClass 指定map和reduce函数的 输出 类型, 这两个函数的输出类型往往相同. 如果不同, map的输出函数类型通过 setMapOutputKeyClass 和 setMapOutputValueClass 指定.
? ?
输入的类型用 InputFormat 设置, 本例中没有指定, 使用的是默认的 TextInputFormat (文本输入格式);
? ?
最后, JobClient.runJob() 会提交作业并等待完成, 将结果写到控制台.
? ?

? ?

? ?

? ?
? ?
新增的java MapReduce API与旧API的区别:
? ?
新API倾向于使用基类而不是接口, 因为更容易扩展.
? ?
新API放在 org.apache.hadoop.mapreduce 包中, 旧的在 org.apache.hadoop.mapred 中.
? ?
新API充分使用context object, 使用户代码能与MapReduce系统进行通信. ex, MapContext基本具备了JobConf, OutputCollector和Reporter的功能.
? ?
新API支持"推"(push)和"拉"(pull)式的迭代. 这两类API, 均可以K/V pair把记录推给mapper, 亦可以从map()方法中pull.pull的好处是, 可以实现数据的批量处理, 而非逐条记录的处理.
? ?
新API实现了配置的统一. 不在通过JobConf对象(Hadoop配置的对象的一个扩展)配置, 而是通过Configuration配置.
新API中作业由Job类控制, 而非JobClient类, 它被删除了.
? ?
输出文件的命名方式稍有不同. map为part-m-nnnnn, reduce为part-r-nnnnn(nnnnn为分块序列号, 整数, 从0开始).
? ?

? ?

? ?
一些术语:
? ?
MapReduce作业(job)是一个工作单元:它包括输入数据, MapReduce程序和配置信息. Hadoop将作业分为若干个小task来执行, 分为两类, map和reduce任务.
? ?
两类节点控制着作业的执行过程: jobtracker(一个)和tasktracker(一系列). 前者调度后者, 后者返回结果给前者.
? ?

? ?
输入分片 (input split), 输入数据, 等长的小数据块. 简称分片. 一个分片一个map task.
? ?

? ?
负载均衡. 但是, split足够多, 可能会增加管理split的时间和构建map task的时间. 合理的是HDFS的一个块的大小(默认64MB).
? ?
数据本地化优化 (data locality optimization).即在HDFS的节点上运行map task, 性能最优. 节省了网络传输资源.
? ?
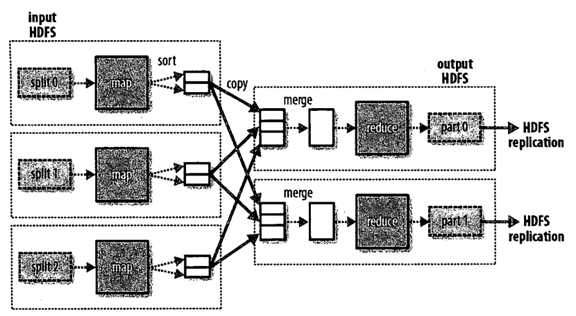
map任务写入本地硬盘, 而不是HDFS. 为何? map的输出是中间结果, 完成后可被删除. 如果map失败, 将在另一个节点重起一个map task, 再次构建map中间结果.
? ?
reduce任务不具备数据本地化的优势. 因为它的输入是多个map的输出. 需要网络.
reduce输出放在HDFS中, 可靠存储.即, 第一个副本在本地节点, 其他副本在其他机架节点上. 输出需要占网络带宽.
? ?
reduce的任务数量不是由输入数据的大小决定, 而是指定的.
? ?
如果有多个reduce任务, 每个map会对其输出 分区 (partition), 即为每个reduce任务创建一个分区.
? ?
分区由用户自定义的分区函数控制, 但是一般使用默认的分区器(partitioner)通过哈希函数来分区, 很高效.
? ?
? ?
这里map任务和reduce任务之间的数据流称为 混洗 (shuffle). 一般比此图要更复杂, 并且调整混洗参数对作业执行总时间有非常大的影响.
? ?
combiner, 合并函数. 优化方案, 对map任务的输出进行合并, 以减少map和reduce任务间的数据传输(占用带宽资源).
? ?
并非所有函数都可以合并, 需要具有某个属性(被称为"分布式的"函数). 比如算最大值,求和可以用合并,但算平均数, 需要K/V pair的个数.
? ?
使用combiner, 是需要慎重考虑的.
? ?

? ?
指定一个合并函数
? ?
下面的代码是旧的API的实现方法, 本书中都是使用旧的API实现的.
? ?
红色部分为执行的合并函数,它与reducer是一样的
? ?
相当于执行了两次reducer
? ?
public class MaxTemperatureWithCombiner {
public static void main(String[] args) throws IOException {
if(args.length !=2 ) {
System.err.println("Usage: MaxTemperatureWithCombiner <input path> <output path>");
System.exit(-1);
}
? ?
JobConf conf = new JobConf(MaxTemperatuerWithCombiner.class);
conf.setJobName("Max temperature");
? ?
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
? ?
conf.setMapperClass(MaxTemperatuerMapper.class);
conf.setCombinerClass(MaxTemperatuerReducer.class);
conf.setReducerClass(MaxTemperatuerReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
? ?
JobClient.runJob(conf);
? ?
}
《Hadoop权威指南》笔记 第一章&第二章 MapReduce初探
标签:
原文地址:http://www.cnblogs.com/keedor/p/4393678.html