标签:
其实,在之前上海交大模式分析与机器智能实验室对2.6版本的svm.cpp做了部分注解,(在哪里?google一下你就知道)。但是,这个注释只是针对代码而注释,整篇看下来,你会发现除了理解几个参数的含义,还是会对libsvm一头雾水。当然作为理解程序的辅助材料,还是有很大用处的。特别是,对几个结构体的说明,比较清楚。但是要清楚程序具体做了什么,还是要追踪程序中去。
由于svm涉及的数学知识比较多,我们这篇只是讲一些基本的思路,所以就从最基本的C-SVC型svm,核函数采用常用的RBF函数。LibSVM就采用2.6版本的好了,因为后续的版本作者又加了很多内容,不易理解作者最初的思路。我是做模式识别,主要从分类的角度来解析函数的调用过程,我们从svmtrain.c看起,其调用的函数过程如下: 

上图是整个C-SVC的计算过程,下面对一些重要的内容进行具体说明:
1. svm_group_class
在2.6版中没有此函数的,其功能直接在svm_train实现,为了增强可读性,2.89版中设置了这个函数,其实所作的工作都是一样的。需要说明的是其重新排列后perm中只存储的是各个样本在原始位置的序号,而非数据。这样做的好处有两个:
1)不必破坏原始数据(也就是读进来的x的数据);
2)检索起来方便,只需要L维的数据检索,得到序号后,然后定位到原始数据中相应的位置就可以。

perm是中各类的排列顺序是按照原始样本中各类出现的先后顺序排列的,不一定是按照你原始样本的label序号排列,假如原始样本的label是{-1,0,1},而最先出现的label为1的样本,那么perm中就把label为1的作为类0最先排列。而start中记录的是各类的起始序号,而这个序号是在perm中的序号。
2. 多类判别的one-against-one
svm做判别是用的分界线(面),两类之间只有一个分界线(面),因此分类器也只有1种,要么是1类要么是2类。但是对于多类,分类方式就有多种。目前,存在的方法主要有:
1)1-V-R方式
对于k类问题,把其中某一类的n个训练样本视为一类,所有其他类别归为另一类,因此共有k个分类器。最后预测时,判别式使用竞争方式,也就是哪个类得票多就属于那个类。
2)1-V-1方式
也就是我们所说的one-against-one方式。这种方法把其中的任意两类构造一个分类器,共有(k-1)×k/2个分类器。最后预测也采用竞争方式。
3)有向无环图(DAG-SVM)
该方法在训练阶段采用1-V-1方式,而判别阶段采用一种两向有向无环图的方式。
LibSVM采用的是1-V-1方式,因为这种方式思路简单,并且许多实践证实效果比1-V-R方式要好。

上图是一个5类1-V-1组合的示意图,红色是0类和其他类的组合,紫色是1类和剩余类的组合,绿色是2类与右端两类的组合,蓝色只有3和4的组合。因此,对于nr_class个类的组合方式为:
for(i = 0; i < nr_class; i ++)
{
for(j = i+1; i < nr_class; j ++)
{ 类 i –V – 类 j }
}
3. hessian矩阵的内存处理
因为svm是基于结构风险最小的,因此在分类识别方式具有较传统的基于经验风险最小的方式有优势。但是svm也有一个致命的缺陷,因为要计算hessian矩阵Qij所耗的内存巨大,不利于实践中应用。目前,怎么减小内存的使用依旧是SVM的研究的课题。LibSVM对hessian矩阵处理的策略是定义了一个内存处理类Cache类,预先认为分配一定的内存,存储计算好的Qij,其序号的检索采用双向链表的方式,加快了检索速度。其最重要的函数为:
int Cache::get_data(const int index, Qfloat **data, int len)
//len 是 data 的长度,data为返回的内存首地址,index为Qij的行。
每次都要查找链表中行为index的Qi,假如已经计算过了,就返回计算过的内存地址,并把储存首地址的链表节点插入到链表尾部。假如没计算过,就分配内存并进行计算,当剩余的内存不够时,就要回收链表头指向的内存。这里,可能有人会问,难道以前计算的就没有用了吗??其实,是因为Qij是稀疏矩阵,在训练过程中只要其对应的alpha[i]不再变动(这时alpha[i]=0或者alpha[i]=C),其对应的Qi就不会被选到来训练,因此原来计算的Qi就没有用了。其实,链表的顺序代表了别选到的频率,最头部的是最不可能被选到,因为这时alpha[i]=0或者alpha[i]=C,而最尾部的最容易被选到。
4. 数据选择select_working_set(i,j)
对于样本数量比较多的时候(几千个),SVM所需要的内存是计算机所不能承受的。目前,对于这个问题的解决方法主要有两种:块算法和分解算法。这里,libSVM采用的是分解算法中的SMO(串行最小化)方法,其每次训练都只选择两个样本。我们不对SMO做具体的讨论,要想深入了解可以查阅相关的资料,这里只谈谈和程序有关的知识。
一般SVM的对偶问题为:
![]()
S.t. (4.1)
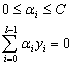
SVM收敛的充分必要条件是KKT条件,其表现为:
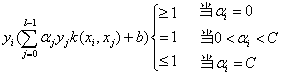 (4.2)
(4.2)
由4.1式求导可得:![]()
(4.3)
进一步推导可知:
 (4.4)
(4.4)
也就是说,只要所有的样本都满足4.4式,那么得到解就是最优值。因此,在每轮训练中,每次只要选择两个样本(序号为i和j),是最违反KKT条件(也就是4.4式)的样本,就能保证其他样本也满足KKT条件。序号i和j的选择方式如下:
![]() (4.5)
(4.5)
5. 停止准则
LibSVM程序中,停止准则蕴含在了函数select_working_set(i,j)返回值中。也就是,当找不到符合4.5式的样本时,那么理论上就达到了最优解。但是,实际编程时,由于KKT条件还是蛮苛刻的,要进行适当的放松。令:
 (4.6)
(4.6)
由4.4式可知,当所有样本都满足KKT条件时,gi ≤ -gj
加一个适当的宽松范围ε,也就是程序中的eps,默认为0.001,那么最终的停止准则为:
gi ≤ -gj +ε → gi + gj ≤ε (4.7)
6. 因子α的更新
由于SMO每次都只选择2个样本,那么4.1式的等式约束可以转化为直线约束:
![]() (4.8)
(4.8)
转化为图形表示为:

把4.8式中α1由α2 表示,即:![]() ,结合上图由解析几何可得α2的取值范围:
,结合上图由解析几何可得α2的取值范围:
 (4.9)
(4.9)
经过一系列变换,可以得到的α2更新值α2new:
 (4.10)
(4.10)
结合4.9和4.10式得到α2new最终表达式:
 (4.11)
(4.11)
得到α2new后,就可以由4.8式求α1new。
这里,具体操作的时候,把选择后的序号i和j代替这里的1和2就可以了。当然,编程时,这些公式还是太抽象。对于4.9式,还需要具体细分。比如,对于y1 y2 = -1时的L = max(0,α2 - α1),是0大还α2 - α1是大的问题。总共需要分8种情况。
7. 数据缩放do_shrinking()
上面说到SVM用到的内存巨大,另一个缺陷就是计算速度,因为数据大了,计算量也就大,很显然计算速度就会下降。因此,一个好的方式就是在计算过程中逐步去掉不参与计算的数据。因为,实践证明,在训练过程中,alpha[i]一旦达到边界(alpha[i]=0或者alpha[i]=C),alpha[i]值就不会变,随着训练的进行,参与运算的样本会越来越少,SVM最终结果的支持向量(0<alpha[i]<C)往往占很少部分。
LibSVM采用的策略是在计算过程中,检测active_size中的alpha[i]值,如果alpha[i]到了边界,那么就应该把相应的样本去掉(变成inactived),并放到栈的尾部,从而逐步缩小active_size的大小。
8. 截距b的计算
b计算的基本公式为:
![]() (4.12)
(4.12)
理论上,b的值是不定的。当程序达到最优后,只要用任意一个标准支持向量机(0<alpha[i]<C)的样本带入4.12式,得到的b值都是可以的。目前,求b的方法也有很多种。在libSVM中,分别对y=+1和y=-1的两类所有支持向量求b,然后取平均值:
 (4.13)
(4.13)
至此,libSVM的整个思路我们简单的过了一遍,里面涉及到很到理论知识,许多细节需要查看相关的SVM的书籍。说实话,笔者也是新手,有些理论也没弄很清楚,我只能把我知道的尽量的讲出来。希望对一些想要了解SVM的有所帮助。
标签:
原文地址:http://www.cnblogs.com/Miliery/p/4394081.html