标签:
1. MapReduce - 映射、化简编程模型
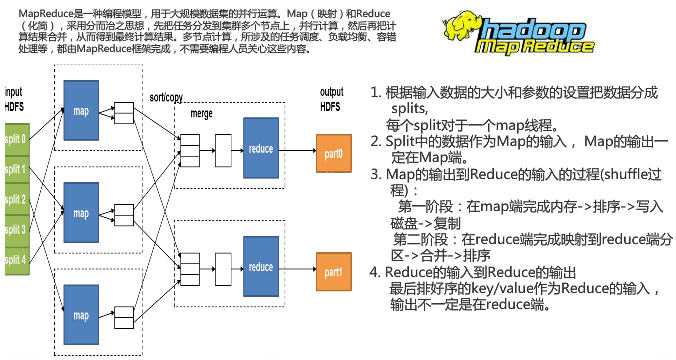
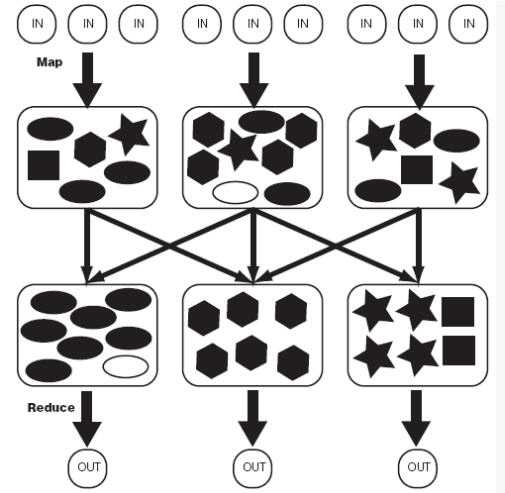
运行原理:

2. Hadoop V1 中的 MapReduce 的实现
Hadoop 1.0 指的是版本为Apache Hadoop 0.20.x、1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统组成,其中,MapReduce是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker和TaskTracker)和 数据处理引擎(MapTask和ReduceTask)三部分组成。
2.1 Hadoop V1 中 MapReduce 的实现
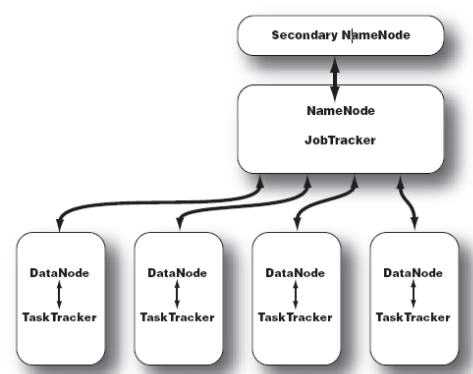
- NameNode 中记录了文件是如何被拆分成 block 以及这些 block 都存储到了那些DateNode节点。NameNode 同时保存了文件系统运行的状态信息.
- DataNode中存储的是被拆分的blocks.
- Secondary NameNode 帮助 NameNode收集文件系统运行的状态信息.
- JobTracker 当有任务提交到 Hadoop 集群的时候负责 Job 的运行,负责调度多个TaskTracker.
- TaskTracker 负责某一个 map 或者 reduce 任务.
MapReduce 原理:
1. 数据分布存储:HDFS 有一个名称节点 NameNode 和 N 个数据节点组成,每个节点均是一台普通计算机。HDFS底层把文件分割成了block,然后这些block分散地存储到不同的DataNode上。每个Block还能复制数份存储在不同的DataNode上,达到容错容灾的目的。NameNode 是 HDFS 的核心,它记录每个文件被切割成多少各Block,这些block分散在哪些DataNode上,每个DataNode 的状态如何。
2. 分布式并行计算。Hadoop 有一个作为主控的 JobTracker,用于调度和管理TaskTracker。JobTracker 可以运行在集群中的任何一个节点上。TaskTracker负责执行任务,,它必须运行在 DataNode 上,也就是说 DataNode 既是数据存储节点,也是计算节点。JobTracker 把map和reduce任务发给空闲的TaskTracker,让其运行并监控其运行情况。在TaskTracker故障时,JobTracker 会把它的任务转交给另一个空闲的TaskTracker。
3. 本地计算:数据存储在哪个节点上,就由哪个节点进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的要求。“本地计算”是一种最有效的节约网络带宽的手段。
4. 任务粒度:原始大数据切割为小数据集时,通常让数据集小于或者等于HDFS中一个block的大小(默认是64M),从而保证一个数据集是位于一台计算机上,便于本地计算。
M 个小数据集,启动 M 个 map 任务,这些任务分布在 N 台计算机上,它们会并行运行,reduce 的任务数量 R 由用户指定。
5. 数据分割(Partition):把 map 任务输出的中间结果按照 key 的范围划分为 R 份, R 是预先定义的 reduce 任务数目。
6. 数据合并(Combine):数据分割之前,还可以把中间结果进行数据合并,即将中间结果中有相同key 的<key,value>合并成一对。Combine 是map 任务的一部分,这样做可以减少数据传输流量。
7. Reduce:map 任务的结果,以文件形式存在于本地磁盘上。中间结果文件的位置会通知 JObTracker,JObTracker 再通知 reduce 任务到哪个 DataNode上去取中间结果。每个 reduce 需要向许多的 map 任务节点取得落在其负责的 key 区间的中间结果,然后执行 reduce 函数。
8. 任务管道: 有 R 个 reduce 任务,就会有 R 个最终结果。有时候这 R 个结果不需要合并成一个最终结果,因为这 R 个结果可以作为另一个计算任务的输入,开始另一个并行计算任务,这就形成了任务管道。
2.2 MapReduce 的资源管理
Hadoop V1 中,MapReduce 除了数据处理外,还兼具资源管理功能。
Hadoop 1.0 资源管理由两部分组成:资源表示模型和资源分配模型,其中,资源表示模型用于描述资源的组织方式,Hadoop 1.0采用“槽位”(slot)组织各节点上的资源,而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。为了简化资源管理,Hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个task可根据实际需要占用多个slot 。通过引入“slot“这一概念,Hadoop将多维度资源抽象简化成一种资源(即slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”,一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和reduce slot数(由参数mapred.tasktrackerreduce.tasks.maximum指定)。
Hadoop 1.0中的资源管理存在以下几个缺点:
(1)静态资源配置。采用了静态资源设置策略,即每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。
(2)资源无法共享。Hadoop 1.0将slot分为Map slot和Reduce slot两种,且不允许共享。对于一个作业,刚开始运行时,Map slot资源紧缺而Reduce slot空闲,当Map Task全部运行完成后,Reduce slot紧缺而Map slot空闲。很明显,这种区分slot类别的资源管理方案在一定程度上降低了slot的利用率。
(3) 资源划分粒度过大。这种基于无类别slot的资源划分方法的划分粒度仍过于粗糙,往往会造成节点资源利用率过高或者过低 ,比如,管理员事先规划好一个slot代表2GB内存和1个CPU,如果一个应用程序的任务只需要1GB内存,则会产生“资源碎片”,从而降低集群资源的利用率,同样,如果一个应用程序的任务需要3GB内存,则会隐式地抢占其他任务的资源,从而产生资源抢占现象,可能导致集群利用率过高。
(4) 没引入有效的资源隔离机制。Hadoop 1.0仅采用了基于jvm的资源隔离机制,这种方式仍过于粗糙,很多资源,比如CPU,无法进行隔离,这会造成同一个节点上的任务之间干扰严重。
2.3 MapReduce 架构的局限
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
1. JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
2. JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
3. 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
4. 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
5. 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
6. 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
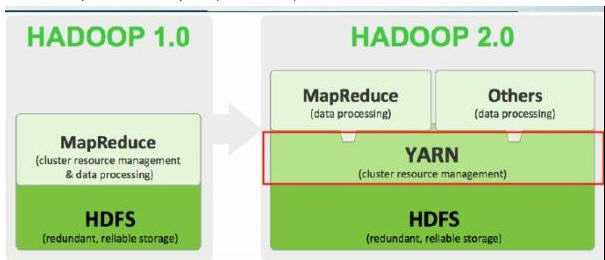
3. Hadoop 2.0 中的 MapReduce
源于上面描述的 MRv1 (传统的Hadoop MR)的缺陷,比如:
- 受限的扩展性;
- JobTracker 单点故障;
- 难以支持MR之外的计算;
- 多计算框架各自为战,数据共享困难,比如MR(离线计算框架),Storm实时计算框架,Spark内存计算框架很难部署在同一个集群上,导致数据共享困难等
Hadoop V2 重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是 资源管理和任务调度 / 监控。
- 新的资源管理器 YARN 全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
- 任务的调度和监控依然由 MapReduce 负责。
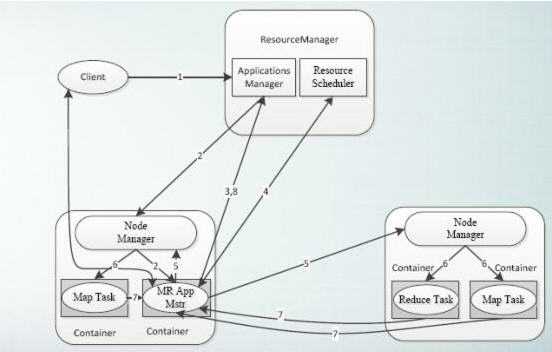
传统 MapReduce 在YARN上的调度:
注:以上内容均来自于互联网。
Hadoop 1.0 和 2.0 中的数据处理框架 - MapReduce
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4396142.html