标签:
本段代码的目的是从 http://www.tax.sh.gov.cn/tycx/TYCXqjsknsrmdCtrl-getQjsknsrmd.pfv 获取 欠税信息。
通过Fiddler工具 ,抓包查看该站点的推送方式。
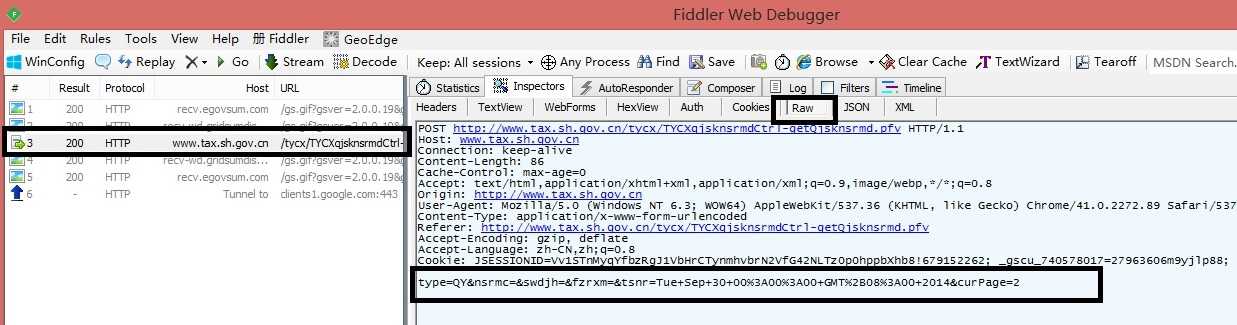
通过工具我们可以发现,有POST信息,且post的内容为,type nsrmc swdjh fzrxm tsnr curPage
因此,我们可以模型上述URL的请求。
以下代码,是使用了代理的方式访问:
通过生成一个ProxyHandler对象,来打开相应的网页。
#coding:utf-8 import sys,re import urllib.request import http.client from _overlapped import PostQueuedCompletionStatus fname = "C:/Users/Songxiaodi/Desktop/tax_file.txt" file = open(fname, ‘w‘) for line in range(1,170): proxy_handler = urllib.request.ProxyHandler({‘http‘:‘11.1.0.10:80‘}) opener = urllib.request.build_opener(proxy_handler) postdata = urllib.parse.urlencode({‘type‘:‘QY‘,‘nsrmc‘:‘‘,‘swdjh‘:‘‘,‘fzrxm‘:‘‘,‘tsnr‘:‘Tue+Sep+30+00%3A00%3A00+GMT%2B08%3A00+2014‘,‘curPage‘:line}) postdata = postdata.encode(‘utf-8‘) page = opener.open(‘http://www.tax.sh.gov.cn/tycx/TYCXqjsknsrmdCtrl-getQjsknsrmd.pfv‘,postdata) html = str(page.read(), ‘utf-8‘) reg=re.compile(r"\<td\>(.*公司.*)\<\/td\>") print (reg.findall(html)) content=reg.findall(html) for cc in range(0, len(content)): #print("--:" + str(cc)+content[cc]) file.write(str(content[cc])) file.write("\n") file.close() print (‘OK‘)
若不使用代理访问,可以使用urllib.request.urlopen
1 #coding:utf-8 2 import sys,re 3 import urllib.request 4 import http.client 5 from _overlapped import PostQueuedCompletionStatus 6 7 fname = "C:/Users/Songxiaodi/Desktop/tax_file.txt" 8 file = open(fname, ‘w‘) 9 10 for line in range(1,170): 11 #=========================================================================== 12 # proxy_handler = urllib.request.ProxyHandler({‘http‘:‘11.1.0.10:80‘}) 13 # opener = urllib.request.build_opener(proxy_handler) 14 #=========================================================================== 15 postdata = urllib.parse.urlencode({‘type‘:‘QY‘,‘nsrmc‘:‘‘,‘swdjh‘:‘‘,‘fzrxm‘:‘‘,‘tsnr‘:‘Tue+Sep+30+00%3A00%3A00+GMT%2B08%3A00+2014‘,‘curPage‘:line}) 16 postdata = postdata.encode(‘utf-8‘) 17 page = urllib.request.urlopen(‘http://www.tax.sh.gov.cn/tycx/TYCXqjsknsrmdCtrl-getQjsknsrmd.pfv‘,postdata) 18 html = str(page.read(), ‘utf-8‘) 19 reg=re.compile(r"\<td\>(.*公司.*)\<\/td\>") 20 print (reg.findall(html)) 21 content=reg.findall(html) 22 for cc in range(0, len(content)): 23 #print("--:" + str(cc)+content[cc]) 24 file.write(str(content[cc])) 25 file.write("\n") 26 file.close() 27 print (‘OK‘)
标签:
原文地址:http://www.cnblogs.com/maomaoxiyu/p/4396228.html