Match类
示例:查找出字符串中包含的url
string text = "FirstUrl: http://www.sohu.com ,SecondUrl: http://www.baidu.com ";
string pattern = @"\b(\S+)://(\S+)\b"; //匹配URL的模式
MatchCollection mc = Regex.Matches(text, pattern); //满足pattern的匹配集合
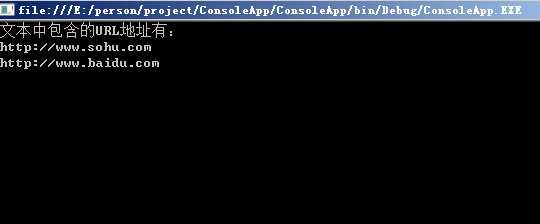
Console.WriteLine("文本中包含的URL地址有:");
foreach (Match match in mc)
{
Console.WriteLine(match.Value);
}
Console.ReadLine();
结果:
Group类
示例:找到字符串中包含的url,并找出每个url的协议和域名地址
string text = "FirstUrl: http://www.sohu.com ,SecondUrl: http://www.baidu.com ";
string pattern = @"\b(?<protocol>\S+)://(?<address>\S+)\b"; //匹配URL的模式,并分组
MatchCollection mc = Regex.Matches(text, pattern); //满足pattern的匹配集合
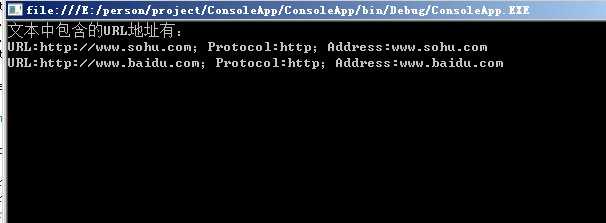
Console.WriteLine("文本中包含的URL地址有:");
foreach (Match match in mc)
{
GroupCollection gc = match.Groups;
string outputText = "URL:" + match.Value + ";Protocol:" + gc["protocol"].Value + ";Address:" + gc["address"].Value;
Console.WriteLine(outputText);
}
Console.Read();
说明:"?<protocol>"和"?<address>"定义了每个组的别名protocol和address
(注意:这是一个match内的设置不同名称的组,对这些组进行提取)
对具有相同模式的字符串内不同的组的提取怎样做呢,我是这样做的:
sourcetext:{name:john,data:[1,2,3],name:marry,data:[4,5,6]}
代码:
Regex reg = new Regex(@"data:\[([\w|.|,]{1,})\]", RegexOptions.IgnoreCase);
MatchCollection matches = reg.Matches(series);
foreach (Match match in matches)
{
GroupCollection groups = match.Groups;
for (int j = 0; j < groups.Count; j++)
{
string weightjsonInKgMode = covertToKg(groups[j].Value.Replace("data:[", "").Replace("]", ""));
string regModel = groups[j].Value;
regModel = regModel.Replace("[", "\\[").Replace("]", "\\]");
series = Regex.Replace(series, regModel, weightjsonInKgMode);
}
}
正则表达式match和group的区别 具有相同模式的字符串使用组的提取案例
原文地址:http://blog.csdn.net/goodshot/article/details/44935521