标签:
在使用一个工具之前,应该先对它的机制、组成等有深入的了解,以后才会更好的使用它。下面来介绍一下什么是HDFS,以及他的构架是什么样的。
1.什么是HDFS?
Hadoop主要是用于进行大数据处理,那么如何有效的存储大规模的数据呢?显然,集中式的物理服务器保存数据是不现实的,其容量、数据传输速度等都会成为瓶颈。那么要实现海量数据的存储,势必要使用十几台、几百台甚至是更多的分布式服务节点。那么,为了统一管理这些节点上存储的数据,必须要使用一种特殊的文件系统——分布式文件系统。HDFS(Hadoop Distributed File System)就是Hadoop提供的一个分布式文件系统。
HDFS具有大规模数据分布式存储能力、高并发访问能力、强大的容错能力、顺序式文件访问、简单的一致性模型(一次写多次读)、数据块存储模式等优点。
2.HDFS的基本框架
2.1 Architecture
HDFS一Master-Slave模式运行,主要由两类节点:一个NameNode(即Master)和多个DataNode(即Slave),其框架图如下图所示:
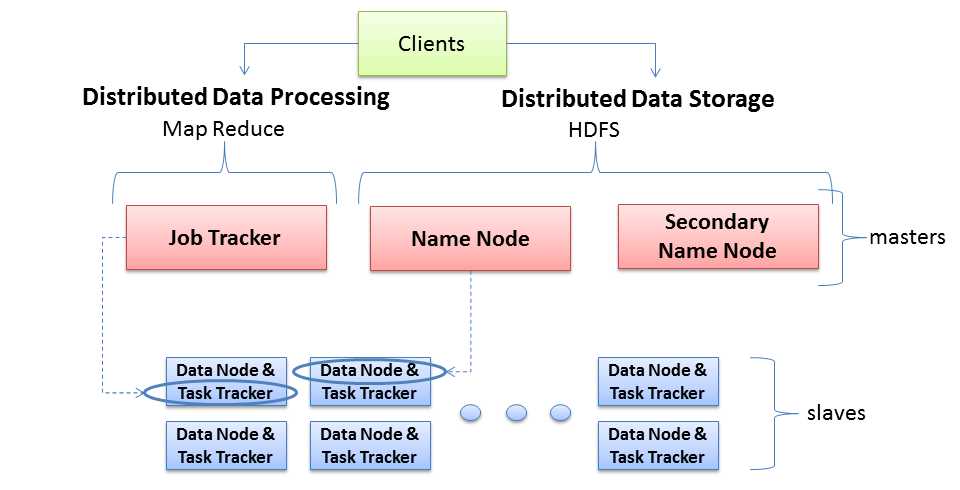
2.2 NameNode、DataNode、JobTracker和TaskTracker
NameNode保存了文件系统的三种元数据:
2. DataNode。HDFS对外提供了命名空间,让用户的数据可以存储在文件中,但是在内部,文件可能被分成若干个数据块,DataNode用来实际存储和管理文件的数据块。
3. JobTracker对应于NameNode,TaskTracker对应于DataNode(如上图所示),NameNode与Datanode是针对数据存储而言的,JobTracker与TaskTracker是针对与MapReduce的执行而言的。
2.3 HDFS的基本文件访问过程
2.4 MapReduce的执行过程
2.5 SecondaryNameNode
Hadoop中使用SecondaryNameNode来备份NameNode备份NameNode的元数据,以便在NameNode失效时能从SecondaryNameNode恢复出NameNode上的元数据,它充当NameNode的一个副本,它本身并不处理任何请求,周期性保存NameNode的元数据
参考链接:
[1]. hadoop JobTracker和TaskTracker——http://wz102.blog.51cto.com/3588520/1327972
[2]. HDFS学习(三)—NameNode and DataNode——http://shitouer.cn/2012/12/hdfs-namenode-datanode/
[3]. 深入理解大数据-大数据处理与编程实践
标签:
原文地址:http://www.cnblogs.com/little-YTMM/p/4401601.html