标签:
基本环境:
我是在win7环境下,spark1.0.2,HBase0.9.6.1
使用工具:IDEA14.1, scala 2.11.6, sbt。我现在是测试环境使用的是单节点
1、使用IDEA创建一个sbt的工程后,在build.sbt文件加入配置文件
libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.0.2" % "provided" libraryDependencies += "org.apache.spark" % "spark-streaming_2.10" % "1.0.2" % "provided" libraryDependencies += "org.apache.hbase" % "hbase-common" %"0.96.1.1-hadoop2" % "provided" libraryDependencies += "org.apache.hbase" % "hbase-client" % "0.96.1.1-hadoop2" % "provided" libraryDependencies += "org.apache.hbase" % "hbase-server" % "0.96.1.1-hadoop2" % "provided"
2、创建一个scala Object
对应的路径和表名,列族自己修改
package cn.rcz.bigdata import org.apache.spark.SparkContext import org.apache.spark._ import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.HTableDescriptor import org.apache.hadoop.hbase.client.HBaseAdmin import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.HColumnDescriptor import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.client.HTable import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.client.Delete /** * Created by ptbx on 2015/4/7. */ import org.apache.spark.{SparkContext, SparkConf} import org.apache.spark.SparkContext._ object Test01 extends Serializable{ def main(args: Array[String]) { /* if (args.length != 2) { System.err.println("Usage: LogAnalyzer <input> <output>") System.exit(1) }*/ val sc = new SparkContext("spark://master:7077", "SparkHBase01") val conf = HBaseConfiguration.create() conf.set("hbase.zookeeper.property.clientPort", "2181") conf.set("hbase.zookeeper.quorum", "master") conf.set("hbase.master", "master:60000") conf.addResource("/home/hadoop/hbase-0.96.1.1-cdh5.0.2/conf/hbase-site.xml") conf.set(TableInputFormat.INPUT_TABLE, "carInfo") val admin = new HBaseAdmin(conf) if (!admin.isTableAvailable("messInfo")) { print("Table Not Exists! Create Table") val tableDesc = new HTableDescriptor("messInfo") tableDesc.addFamily(new HColumnDescriptor("messInfo".getBytes())) admin.createTable(tableDesc) } val hbaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result]) val count = hbaseRDD.count() println("HBase RDD Count:" + count) hbaseRDD.cache() val res = hbaseRDD.take(count.toInt) for (j <- 1 until count.toInt) { println("j: " + j) var rs = res(j - 1)._2 var kvs = rs.raw for (kv <- kvs) println("rowkey:" + new String(kv.getRow()) + " cf:" + new String(kv.getFamily()) + " column:" + new String(kv.getQualifier()) + " value:" + new String(kv.getValue())) } System.exit(0) } }
3:打包成jar 提交运行
在doc下, 进入文件目录后,输入sbt
再次输入compile,进入编译然后在输入package

打包后的jar包在项目的out文件夹里面
4、提交到spark上运行
spark 的运行方式有3种,后续文件会有补充
sh spark-submit --class cn.szkj.bigdata.Test01 --master local[3] /home/hadoop/work.jar
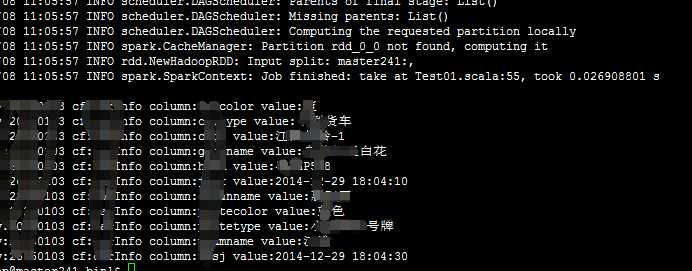
spark1.0.2读取hbase(CDH0.96.1)上的数据
标签:
原文地址:http://www.cnblogs.com/zhanggl/p/4401925.html