标签:
Hadoop的简介
Hadoop的设计思想来源于谷歌在2003年、2004年和2006年,发表了三篇论文:《The Google File System 》 、《MapReduce: Simplified Data Processing on Large Clusters》 和《Bigtable: A Distributed Storage System for Structured Data》,介绍谷歌分布式文件系统GFS、分布式计算框架MapReduce和分布式数据存储系统。Hadoop的HDFS、MapReduce和HBase分别是谷歌这三个系统的开源实现。最初Hadoop是作为Lucene的子项目,用于处理检索系统中海量的文本文件已经其他数据。随着“大数据”概念的兴起,Hadoop受到了很多公司的追捧。发展到今天Hadoop已经成为大数据的代名词。短短几年间,Hadoop从一种边缘技术成为事实上的标准。
Hadoop中的HDFS
HDFS被设计成适合运行在通用硬件上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。MapReduce是用于并行处理大数据集的软件框架。
Hadoop中的MapReduce
MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。MapReduce可以将大量任务分布在多台主机上进行计算,每台主机承担一部分计算任务,提高计算效率
这个分布式框架很有创造性,而且有极大的扩展性,使得Google在系统吞吐量上有很大的竞争力。因此Apache基金会用Java实现了一个开源版本,支持Fedora、Ubuntu等Linux平台。
Hadoop实现了HDFS文件系统和MapRecue。用户只要继承MapReduceBase,提供分别实现Map和Reduce的两个类,并注册Job即可自动分布式运行。
Hadoop的原理及架构
HDFS的架构
HDFS是一个具有高度容错性的分布式文件系统,适合部署在廉价的集群上。HDFS能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS的架构如下图,总体采用了master/slave架构,主要由以下几个组件组成:Client、NameNode、SecondaryNameNode和DataNode。
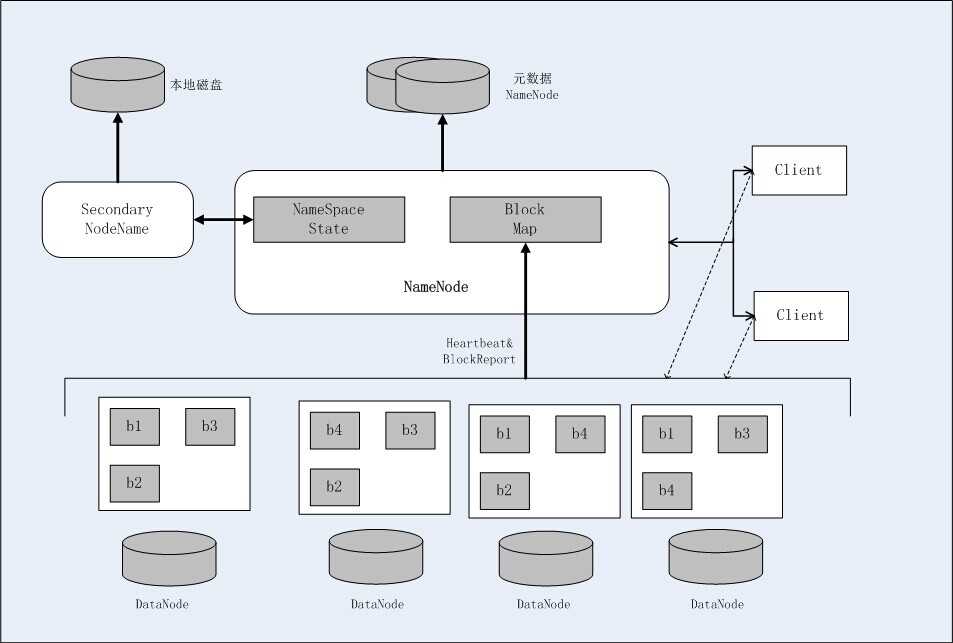
Client通过与NameNode和DataNode交互从而访问HDFS中的文件。Client提供了一个类似POSIX的文件系统接口供用户调用。
整个Hadoop集群中只有一个NameNode。它是整个系统的“总管”,负责管理HDFS的目录树和相关的文件元数据信息,这些信息是以“fsimage”(HDFS元数据镜像文件)和“editlog”(HDFS元数据改动日志)两个文件形式存放在本地磁盘,当HDFS重启时重新构造出来。此外,NameNode还负责监控各个DataNode的健康状态,一旦发现DataNode宕机,则将该DataNode移出HDFS并重新备份其上面的数据。
Secondary NameNode最重要的任务不是为NameNode元数据进行热备份,而是定期合并fsimage和editsLog,并传输给NameNode。为了减小NameNode的压力,NomeNode并不会自己合并fsimage和editsLog,并将文件存储到磁盘上,而是交由Secondary NameNode完成的。
一般而言,每个Slave阶段上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB。当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分布存储在不同的DataNode;同时为了保证数据可靠,会将同一个block以流水线方式写到若干个不同的DataNode上。这种文件切割方式后存储的过程对用户透明。
Hadoop MapReduce架构
Hadoop MapReduce也采用Master/Slave(M/S)架构,如下图所示。
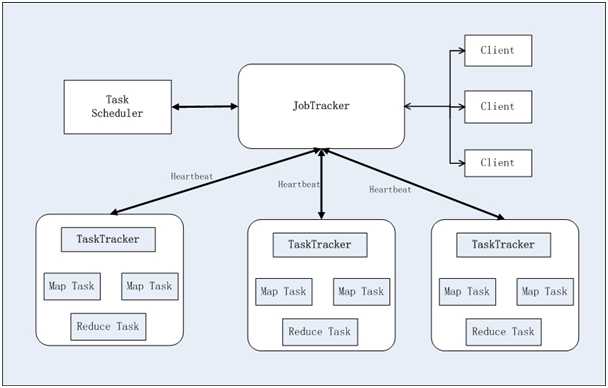
主要由以下几个组件组成:Client、JobTracker、TaskTracker和Task。
用户编写MapReduce程序通过Client提交到JobTracker端;同时用户可通过Client提供的一写接口查看作业运行状态。在Hadoop内部用“作业”表示MapReduce程序。一个MapReduce程序可对若干个作业,而每个作业会被分解成若干个Map/Reduce任务。
JobTracker主要负责资源监控和作业调度。JobTracker监控所有taskTracker与作业的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时JobTracker会跟踪任务执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。
TaskTracker会周期性的通过HeartBeat将本节点上资源的使用情况和任务运行信息汇报给JobTracker,同时也接受来自JobTracker发来的命令并且执行他们,比如说启动一个任务或者杀死一个任务等等。TaskTracker使用slot等量划分本几点上的资源量。一个Task只有获取一个slot之后才有机会运行,而hadoop调度器的作用就是将各个TaskTracker上空闲的slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别给Map Task和Reduce Task使用。TaskTracker通过slot数目来限定Task的并发度。
Task分为Map Task和Reduce Task两种,有TaskTracker启动。Map Task将对应的输入信息解析成一个个的key/value对,调用map函数进行处理,最终将临时结果放到本地磁盘上,临时数据会被分成若干个partition,每个partition对应一个Reduce Task。Reduce Task过程:从节点上读取Map Task中间结果;按照key对key/value对进行排序;调用reduce函数,将结果保存到HDFS上。
注:本篇博文中的内容是基于Hadoop的第一个稳定版1.0版的内容作出的介绍,2.0以上版本的新内容会在后续的博文中介绍。
标签:
原文地址:http://www.cnblogs.com/imcking/p/4402209.html