标签:
最近在忙着优化集团公司的一个报表。优化完成后,报表查询速度有从半小时以上(甚至查不出)到秒查的质变。从修改SQL查询语句逻辑到决定创建存储
过程实现,花了我3天多的时间,在此总结一下,希望对朋友们有帮助。
首先项目是西门子中国在我司实施部署的MES项目,由于项目是在产线上运作(3 years+),数据累积很大。在项目的数据库中,大概上亿条数据的表有5个以上,千万级数据的表10个以上,百万级数据的表,很多...
(历史问题,当初实施无人监管,无人监控数据库这块的性能问题。ps:我刚入职不久...)
不多说,直接贴西门子中国的开发人员在我司开发的SSRS报表中的SQL语句:


1 select distinct b.MaterialID as matl_def_id, c.Descript, case when right(b.MESOrderID, 12) < ‘001000000000‘ then right(b.MESOrderID, 9)
2 else right(b.MESOrderID, 12) end as pom_order_id, a.LotName, a.SourceLotName as ComLot,
3 e.DefID as ComMaterials, e.Descript as ComMatDes, d.VendorID, d.DateCode,d.SNNote, b.OnPlantID,a.SNCUST
4 from
5 (
6 select m.lotname, m.sourcelotname, m.opetypeid, m.OperationDate,n.SNCUST from View1 m
7 left join co_sn_link_customer as n on n.SNMes=m.LotName
8 where
9 ( m.LotName in (select val from fn_String_To_Table(@sn,‘,‘,1)) or (@sn) = ‘‘) and
10 ( m.sourcelotname in (select val from fn_String_To_Table(@BatchID,‘,‘,1)) or (@BatchID) = ‘‘)
11 and (n.SNCust like ‘%‘+ @SN_ext + ‘%‘ or (@SN_ext)=‘‘)
12 ) a
13 left join
14 (
15 select * from Table1 where SNType = ‘IntSN‘
16 and SNRuleName = ‘ProductSNRule‘
17 and OnPlantID=@OnPlant
18 ) b on b.SN = a.LotName
19 inner join MMdefinitions as c on c.DefID = b.MaterialID
20 left join Table1 as d on d.SN = a.SourceLotName
21 inner join MMDefinitions as e on e.DefID = d.MaterialID
22 where not exists (
23 select distinct LotName, SourceLotName from ELCV_ASSEMBLE_OPS
24 where LotName = a.SourceLotName and SourceLotName = a.LotName
25 )
26 and (d.DateCode in (select val from fn_String_To_Table(@DCode,‘,‘,1)) or (@DCode) = ‘‘)
27 and (d.SNNote like ‘%‘+@SNNote+‘%‘ or (@SNNote) = ‘‘)
28 and ((case when right(b.MESOrderID, 12) < ‘001000000000‘ then right(b.MESOrderID, 9)
29 else right(b.MESOrderID, 12) end) in (select val from fn_String_To_Table(@order_id,‘,‘,1)) or (@order_id) = ‘‘)
30 and (e.DefID in (select val from fn_String_To_Table(@comdef,‘,‘,1)) or (@comdef) = ‘‘)
31 --View1是一个嵌套两层的视图(出于保密性,实际名称可能不同),里面有一张上亿数据的表和几张千万级数据的表做左连接查询
32 --Table1是一个数据记录超过1500万的表
这个查询语句,实际上通过我的检测和调查,在B/S系统前端已无法查出结果,半小时,一小时 ... 。因为我直接在SQL查询分析器查,半小时都没有结果。
(原因是里面对一张上亿级数据表和3张千万级数据表做全表扫描查询)
不由感慨,西门子中国的素质(或者说责任感)就这样?
下面说说我的分析和走的弯路(思维误区),希望对你也有警醒。
首先相关表的索引,没有建全的,把索引给建上。
索引这步完成后,发现情况还是一样,查询速度几乎没有改善。后来想起相关千万级数据以上的表,都还没有建立表分区。于是考虑建立表分区以及数据复制的方案。
这里有必要说明下:我司报表用的是一个专门的数据库服务器,数据从产线订阅而来。就是常说的“读写分离”。
如果直接在原表上建立表分区,你会发现执行表分区的事物会直接死锁。原因是:表分区操作本身会锁表,产线还在推数据过来,这样很容易“阻塞”,“死锁”。
我想好的方案是:建立一个新表(空表),在新表上建好表分区,然后复制数据过来。
正打算这么干。等等!我好像进入了一个严重的误区!
分析: 原SQL语句和业务需求,是对产线的数据做产品以及序列号的追溯,关键是查询条件里没有有规律的"条件"(如日期、编号),
贸然做了表分区,在这里几乎没有意义!反而会降低查询性能!
好险!还是一步一步来,先做SQL语句分析。
1. 查询语句的where条件,有大量@var in ... or (@var =‘‘) 的片段
2. where条件有like ‘%‘+@var+‘%‘
3. where条件有 case ... end 函数
4. 多次连接同一表查询,另外使用本身已嵌套的视图表,是不是必须,是否可替代?
5. SQL语句有*号,视图中也有*号出现
首先是用存储过程改写,好处是设计灵活。
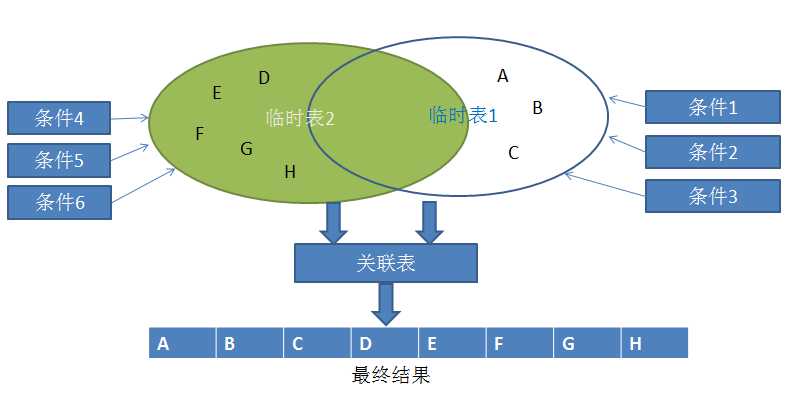
核心思想是:用一个或多个查询条件(查询条件要求至少输入一个)得到临时表,每个查询条件如果查到集合,就更新这张临时表,最后汇总的时候,
只需判断这个临时表是否有值。以此类推,可以建立多个临时表,将查询条件汇总。
这样做目前来看至少两点好处:1.省去了对变量进行 =@var or (@var=‘‘)的判断;
2.抛弃sql拼接,提高代码可读性。
再有就是在书写存储过程,这个过程中要注意:
1. 尽量想办法使用临时表扫描替代全表扫描;
2. 抛弃in和not in语句,使用exists和not exists替代;
3. 和客户确认,模糊查询是否有必要,如没有必要,去掉like语句;
4. 注意建立适当的,符合场景的索引;
5. 踩死 "*" 号;
6. 避免在where条件中对字段进行函数操作;
7. 对实时性要求不高的报表,允许脏读(with(nolock))。
如果想参考优化设计片段的详细内容,请参阅SQL代码:
1 /**
2 * 某某跟踪报表
3 **/
4 --exec spName1 ‘‘,‘‘,‘‘,‘‘,‘‘,‘‘,‘公司代号‘
5 CREATE Procedure spName1
6 @MESOrderID nvarchar(320), --工单号,最多30个
7 @LotName nvarchar(700), --产品序列号,最多50个
8 @DateCode nvarchar(500), --供应商批次号,最多30个
9 @BatchID nvarchar(700), --组装件序列号/物料批号,最多50个
10 @comdef nvarchar(700), --组装件物料编码,最多30个
11 @SNCust nvarchar(1600), --外部序列号,最多50个
12 @OnPlant nvarchar(20) --平台
13 AS
14 BEGIN
15 SET NOCOUNT ON;
16 /**
17 * 1)定义全局的临时表,先根据六个查询条件的任意一个,得出临时表结果
18 **/
19 CREATE TABLE #FinalLotName
20 (
21 LotName NVARCHAR(50), --序列号
22 SourceLotName NVARCHAR(50), --来源序列号
23 SNCust NVARCHAR(128) --外部序列号
24 )
25 --1.1
26 IF @LotName<>‘‘
27 BEGIN
28 SELECT Val INTO #WorkLot FROM fn_String_To_Table(@LotName,‘,‘,1)
29 SELECT LotPK,LotName INTO #WorkLotPK FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLot b WHERE b.Val=MMLots.LotID)
30
31 --求SourceLotPK只能在这里求
32 SELECT a.LotPK,a.SourceLotPK into #WorkSourcePK FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotPK b WHERE b.LotPK=a.LotPK) AND a.SourceLotPK IS NOT NULL
33
34 SELECT a.LotPK,a.SourceLotPK,b.LotName INTO #WorkSourcePK2 FROM #WorkSourcePK a JOIN #WorkLotPK b ON a.LotPK=b.LotPK
35
36 INSERT INTO #FinalLotName SELECT a.LotName,b.LotName AS SourceLotName,NULL FROM #WorkSourcePK2 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.SourceLotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
37 SELECT a.LotName,a.SourceLotName,b.SNCust INTO #FinalLotNameX1 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
38 DELETE FROM #FinalLotName
39 INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX1
40 END
41 --1.2
42 IF @BatchID<>‘‘
43 BEGIN
44 SELECT Val INTO #WorkSourceLot FROM fn_String_To_Table(@BatchID,‘,‘,1)
45 IF EXISTS(SELECT 1 FROM #FinalLotName)--如果@LotName也不为空
46 BEGIN
47 SELECT a.LotName,a.SourceLotName,a.SNCust INTO #FinalLotNameX2 FROM #FinalLotName a WHERE EXISTS(SELECT 1 FROM #WorkSourceLot b WHERE a.SourceLotName=b.Val)
48 DELETE FROM #FinalLotName
49 INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust 