标签:
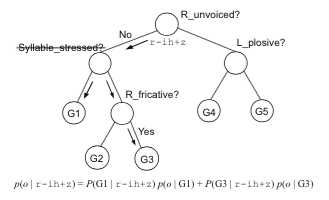
2.1 Decision Tree Marginalization
-jyu+6#sil+x$kei+4&0+0!0+0|0+...0#0^0#0_0#0-0$0&0$0!0$0|
5、《Speech recognition with speech synthesis models by marginalising over decision tree leaves》_1
原文地址:http://www.cnblogs.com/yu-blog/p/4405130.html