标签:
伪分布模式安装即在一台计算机上部署HBase的各个角色,HMaster、HRegionServer以及ZooKeeper都在一台计算机上来模拟。
首先,准备好HBase的安装包,我这里使用的是HBase-0.94.7的版本,已经上传至百度网盘之中(URL:http://pan.baidu.com/s/1pJ3HTY7)
(1)通过FTP将hbase的安装包拷贝到虚拟机hadoop-master中,并执行一系列操作:解压缩、重命名、设置环境变量
①解压缩:tar -zvxf hbase-0.94.7-security.tar.gz
②重命名:mv hbase-94.7-security hbase
③设置环境变量:vim /etc/profile,增加内容如下,修改后重新生效:source /etc/profile
export HBASE_HOME=/usr/local/hbase
export PATH=.:$HADOOP_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
(2)进入hbase/conf目录下,修改hbase-env.sh文件:
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=true #告诉HBase使用它自己的zookeeper实例,分布式模式下需要设置为false
(3)在hbase/conf目录下,继续修改hbase-site.xml文件:
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-master</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(4)【可选步凑】修改regionservers文件,将localhost改为主机名:hadoop-master
(5)启动HBase:start-hbase.sh
PS:由上一篇可知,HBase是建立在Hadoop HDFS之上的,因此在启动HBase之前要确保已经启动了Hadoop,启动Hadoop的命令是:start-all.sh
(6)验证是否启动HBase:jps
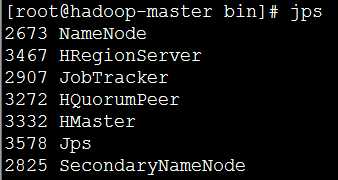
由上图发现,多了三个java进程:HMaster、HRegionServer以及HQuorumPeer。
还可以通过访问HBase的Web接口查看:http://hadoop-master:60010
本次安装在1.1节的伪分布模式的基础上进行修改搭建分布式模式,本次的集群实验环境结构如下图所示:
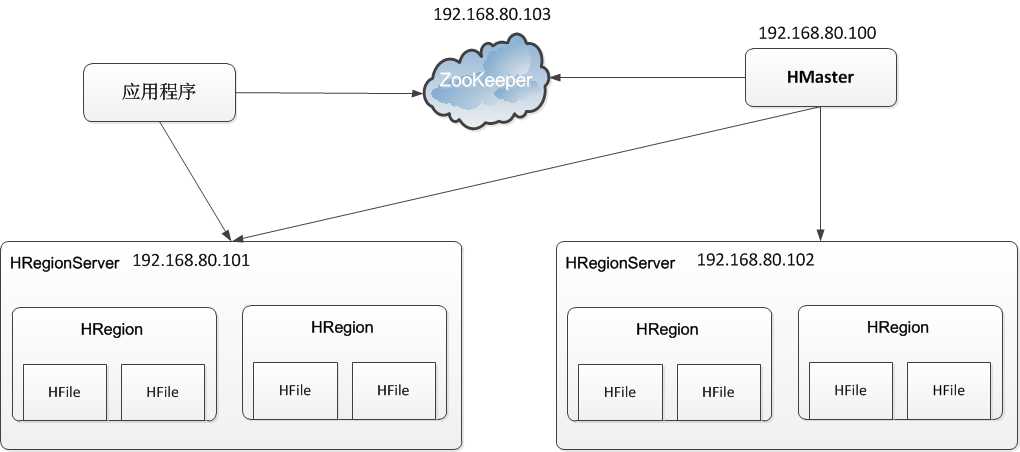
由上图可知,HMaster角色是192.168.80.100(主机名:hadoop-master),而两个HRegionServer角色则是两台192.168.80.101(主机名:hadoop-slave1)和192.168.80.102(主机名:hadoop-slave2)组成的。
(1)修改hadoop-master服务器上的的几个关键配置文件:
①修改hbase/conf/hbase-env.sh:将最后一行修改为如下内容
export HBASE_MANAGES_ZK=false #不使用HBase自带的zookeeper实例
②修改hbase/conf/regionservers:将原来的hadoop-master改为如下内容
hadoop-slave1
hadoop-slave2
(2)将hadoop-master上的hbase文件夹与/etc/profile配置文件整体复制到hadoop-slave1与hadoop-slave2中:
scp -r /usr/local/hbase hadoop-slave1:/usr/local/
scp -r /usr/local/hbase hadoop-slave2:/usr/local/
scp /etc/profile hadoop-slave1:/etc/
scp /etc/profile hadoop-slave2:/etc/
(3)在hadoop-slave1与hadoop-slave2中使配置文件生效:
source /etc/profile
(4)在hadoop-master中启动Hadoop、Zookeeper与HBase:(注意先后顺序)
start-all.sh
zkServer.sh start
start-hbase.sh
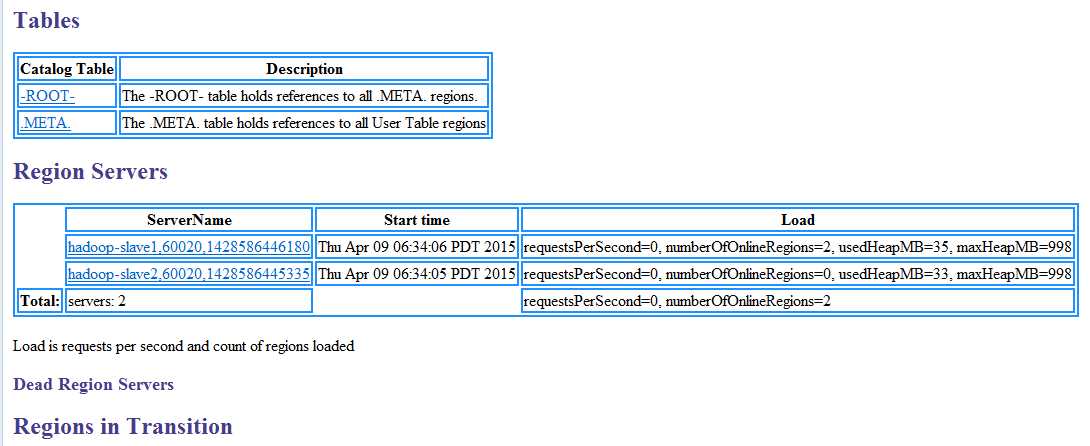
(5)在HBase的Web接口中查看Hbase集群状态:
(1)创建表:
>create ‘users‘,‘user_id‘,‘address‘,‘info‘
#这里创建了一张表users,有三个列族user_id,address,info
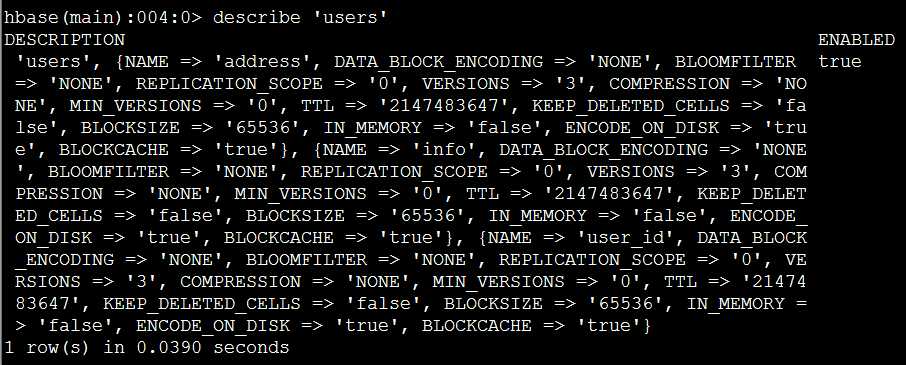
获取表users的具体描述:
>describe ‘users‘
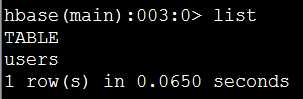
(2)列出所有表:
>list
(3)删除表:在HBase中删除表需要两步,首先disable,其次drop
>disable ‘users‘
>drop ‘users‘
(1)增加记录:put
>put ‘users‘,‘xiaoming‘,‘info:age‘,‘24‘;
>put ‘users‘,‘xiaoming‘,‘info:birthday‘,‘1987-06-17‘;
>put ‘users‘,‘xiaoming‘,‘info:company‘,‘alibaba‘;
>put ‘users‘,‘xiaoming‘,‘address:contry‘,‘china‘;
>put ‘users‘,‘xiaoming‘,‘address:province‘,‘zhejiang‘;
>put ‘users‘,‘xiaoming‘,‘address:city‘,‘hangzhou‘;
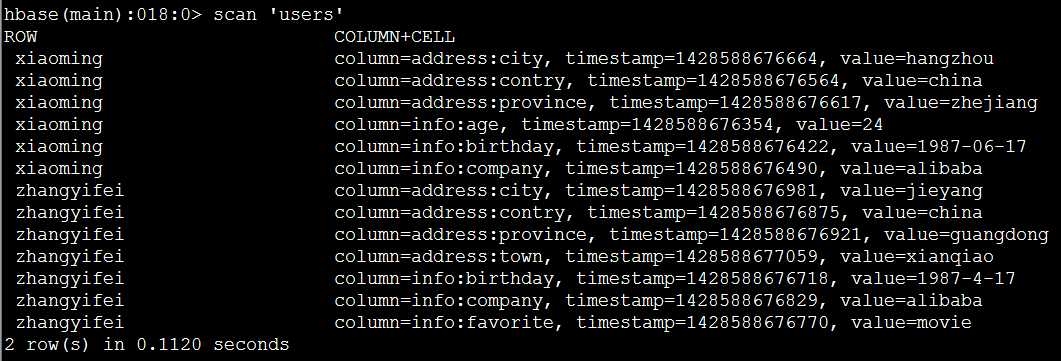
(2)扫描users表的所有记录:scan
>scan ‘users‘
(3)获取一条记录
①取得一个id(row_key)的所有数据
>get ‘users‘,‘xiaoming‘
②获取一个id的一个列族的所有数据
>get ‘users‘,‘xiaoming‘,‘info‘
③获取一个id,一个列族中一个列的所有数据
>get ‘users‘,‘xiaoming‘,‘info:age‘
(4)更新一条记录:依然put
例如:更新users表中小明的年龄为29
>put ‘users‘,‘xiaoming‘,‘info:age‘ ,‘29‘
>get ‘users‘,‘xiaoming‘,‘info:age
(5)删除记录:delete与deleteall
①删除xiaoming的值的‘info:age‘字段
>delete ‘users‘,‘xiaoming‘,‘info:age‘
②删除xiaoming的整行信息
>deleteall ‘users‘,‘xiaoming‘
(1)count:统计行数
>count ‘users‘
(2)truncate:清空指定表
>truncate ‘users‘
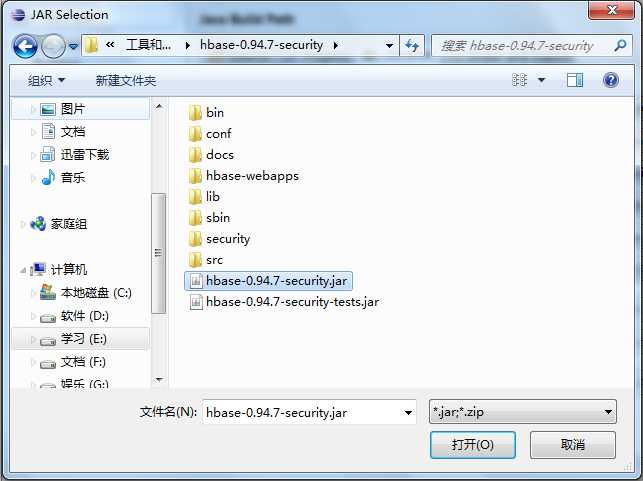
(1)导入HBase的项目jar包
(2)导入HBase/lib下的所有依赖jar包
/* * 获取HBase配置 */ private static Configuration getConfiguration() { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.rootdir","hdfs://hadoop-master:9000/hbase"); //使用eclipse时必须添加这个,否则无法定位 conf.set("hbase.zookeeper.quorum","hadoop-master"); return conf; }
(1)创建表
/* * 创建表 */ private static void createTable() throws IOException { HBaseAdmin admin = new HBaseAdmin(getConfiguration()); if (admin.tableExists(TABLE_NAME)) { System.out.println("The table is existed!"); }else{ HTableDescriptor tableDesc = new HTableDescriptor(TABLE_NAME); tableDesc.addFamily(new HColumnDescriptor(FAMILY_NAME)); admin.createTable(tableDesc); System.out.println("Create table success!"); } }
(2)删除表
/* * 删除表 */ private static void dropTable(String tableName) throws IOException { HBaseAdmin admin = new HBaseAdmin(getConfiguration()); if(admin.tableExists(tableName)){ try { admin.disableTable(tableName); admin.deleteTable(tableName); } catch (IOException e) { e.printStackTrace(); System.out.println("Delete "+tableName+" failed!"); } } System.out.println("Delete "+tableName+" success!"); }
(1)新增记录
public static void putRecord(String tableName, String row, String columnFamily, String column, String data) throws IOException{ HTable table = new HTable(getConfiguration(), tableName); Put p1 = new Put(Bytes.toBytes(row)); p1.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(data)); table.put(p1); System.out.println("put‘"+row+"‘,"+columnFamily+":"+column+"‘,‘"+data+"‘"); }
(2)读取记录
public static void getRecord(String tableName, String row) throws IOException{ HTable table = new HTable(getConfiguration(), tableName); Get get = new Get(Bytes.toBytes(row)); Result result = table.get(get); System.out.println("Get: "+result); }
(3)全表扫描
public static void scan(String tableName) throws IOException{ HTable table = new HTable(getConfiguration(), tableName); Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("Scan: "+result); } }
Hadoop学习笔记—15.HBase框架学习(基础实践篇)
标签:
原文地址:http://www.cnblogs.com/edisonchou/p/4405906.html