标签:
整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。 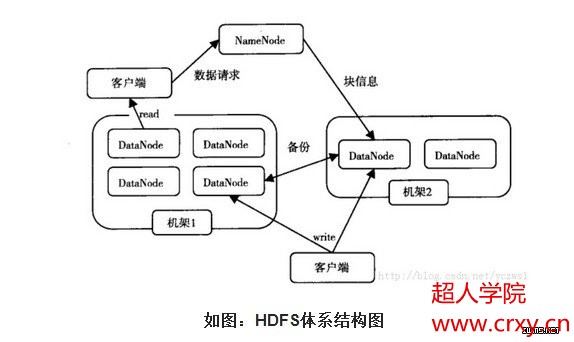
图中涉及三个角色:NameNode、DataNode、Client。NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
文件写入:
1) Client向NameNode发起文件写入的请求。
2) NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3) Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。 文件读取:
1) Client向NameNode发起读取文件的请求。 2) NameNode返回文件存储的DataNode信息。 3) Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题
标签:
原文地址:http://my.oschina.net/crxy/blog/398595