标签:
Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群。
(1) 数据在磁盘上的存取代价为O(1)
(2) 高吞吐率,在普通的服务器上每秒也能处理几十万条消息
(3) 分布式架构,能够对消息分区
(4) 支持将数据并行的加载到hadoop
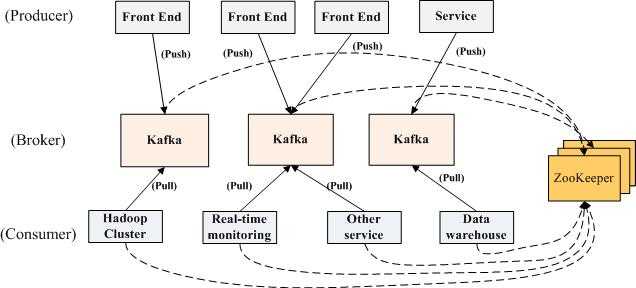
Kafka实际上是一个消息发布订阅系统。producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer。 在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。同时,它也使用了zookeeper进行负载均衡。
Kafka中主要有三种角色,分别为producer,broker和consumer。
Producer的任务是向broker发送数据。Kafka提供了两种producer接口,一种是low_level接口,使用该接口会向特定的broker的某个topic下的某个partition发送数据;另一种那个是high level接口,该接口支持同步/异步发送数据,基于zookeeper的broker自动识别和负载均衡(基于Partitioner)。
其中,基于zookeeper的broker自动识别值得一说。producer可以通过zookeeper获取可用的broker列表,也可以在zookeeper中注册listener,该listener在以下情况下会被唤醒:
当producer得知以上时间时,可根据需要采取一定的行动。
Broker采取了多种策略提高数据处理效率,包括sendfile和zero copy等技术。
consumer的作用是将日志信息加载到中央存储系统上。kafka提供了两种consumer接口,一种是low level的,它维护到某一个broker的连接,并且这个连接是无状态的,即,每次从broker上pull数据时,都要告诉broker数据的偏移量。另一种是high-level 接口,它隐藏了broker的细节,允许consumer从broker上push数据而不必关心网络拓扑结构。更重要的是,对于大部分日志系统而言,consumer已经获取的数据信息都由broker保存,而在kafka中,由consumer自己维护所取数据信息。
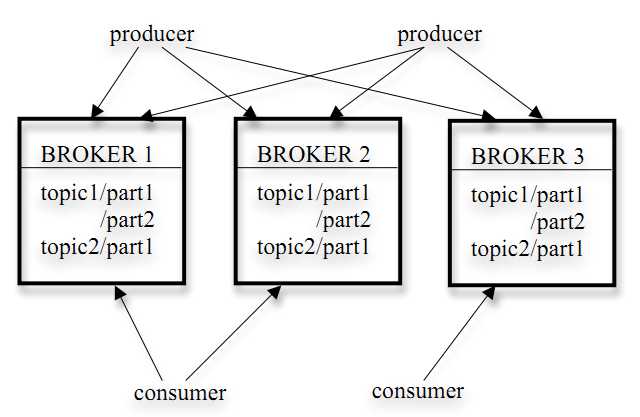
1. kafka 以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,由多个segment组成。
2. 每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3. 每个partition在内存中对应一个index,记录每个segment中的第一条消息偏移。
4. 发布者发到某个topic的消息会被均匀的分布到多个partition上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
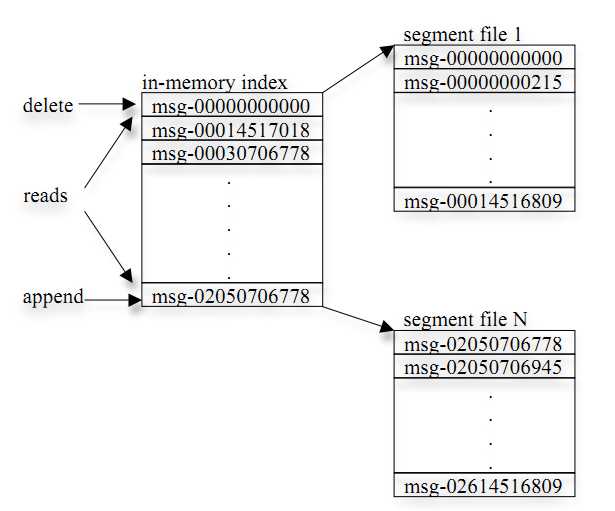
消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求,准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志段文件中分发字节给消费者。
Kafka代理是无状态的,这意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,代理完全不管:
发布接口
producer = new Producer(...); msg = new Message("your message".getBytes()); set = new MessageSet(msg); producer.send("topic", set)
发布消息时,kafka client先构造一条消息,并将消息加入到消息集set中(kafka支持批量发布,可以往消息集合中添加多条消息,一次行发布),send消息时,client需指定消息所属的topic。
订阅接口
streams[] = Consumer.createMessageStreams("topic", 1);
for (message:stream[0]) {
bytes = message.payload();
// do sth. with the bytes
}
订阅消息时,kafka client需指定topic以及partition num(每个partition对应一个逻辑日志流,如topic代表某个产品线,partition代表产品线的日志按天切分的结果),client订阅后,就可迭代读取消息,如果没有消息,client会阻塞直到有新的消息发布。consumer可以累积确认接收到的消息,当其确认了某个offset的消息,意味着之前的消息也都已成功接收到,此时broker会更新zookeeper上地offset registry。
参考文档:
http://dongxicheng.org/search-engine/log-systems/
http://kafka.apache.org/documentation.html#gettingStarted
标签:
原文地址:http://www.cnblogs.com/chenny7/p/4345164.html