我打算边看书边复习讲义,然后用自己的话把每章能看懂的点总结下,欢迎大家指正。由于用语会尽量口语保证易懂,所以会有失严谨性,具体的细节可以看本书。《Learning from data》
第一章主要解决两个问题:
- 通过一个例子介绍机器学习算法;
- 粗略的证明为什么机器学习是可行的?
关于第一点
虽然举得例子PLA比较简单,也基本没啥可用性,但是确实比较适合做为第一个机器学习算法给初学者基本的印象。这个算法的理解在于迭代不等式,为什么这个等式可以不断纠错直到最终的收敛?
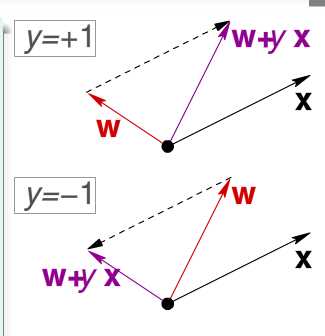
Cousera课程的ppt上有个很直观的解释:
当y=+1时,表示x与w(也就是直线的法向量,假设w朝向正的这边)的夹角小于90℃,如果有一个点它与w的夹角大于90℃说明是分错的点,做一个向量的加法即可让朝着与x夹角减小的方向前进(问题1,不一定一次就搞定吧?)。
迭代的方向没问题之后,剩下的就是为什么会收敛?证明思路是构造一个最终的完美的wf(即可以完全平分数据集的直线),然后证明w最终在有限轮之后可以和wf的夹角为0,具体证明可以看这里。
2 前一个PLA的例子是给初学者直观的映像,什么是机器学习算法,个人觉得第一章最精华的地方是第二点,即粗略证明机器学习是可能的。
首先,什么是机器学习?从这本书的书名我们可以得到简单的解释,是指机器从数据中学习,这个非常关键,有些时候不是学习而是记忆,例如人们学习数学公式,由于公式已经是确定的理论成果,已经经过实践检验的,那个不是学习而是记忆,然后理解,而学习是它的反向过程,即要求人或机器去推导出这样一个公式,所以机器学习的先觉条件是数据。之后才是算法之类的。
有了数据以后,我们就要开始学习了。假设全部的数据用D表示,我们拿到的用于训练的数据用d表示,所谓学习,本质上是得到一个假设函数g,这个g在抽样数据集d上错误率很小,更重要的是,它在全集D的错误率也很低,这样我们就可以用g去预测未来各种情况了,也就是说我们学到了g。严格来说,机器学习伴随着两个过程,一个是学习即求解g,第二个就是验证了。
换句话说。这里有两个问题我们需要解决:
- 这个假设g怎么得到?-- 学习
- 怎么保证我们的g在全集D的错误率很低?全集D是无限大的,我们怎么知道?-- 验证
第一个问题,就是机器学习算法要知道的,就是从一堆假设里面选。怎么选?当然选能够在我们的d上表现最好的,这样我们就得到了那个g。其实这个问题没那么简单,因为有第二个问题。怎么验证得到的g在全集的错误率低?d上的错误率和D上的错误率有没有关系呢?这个叫做g的泛化能力。我们只能求助于概率统计了,那个神奇的公式就是hoffeding inequality。如下所示:
从公式的形式不能看出,它能表示假设h在d和D上的错误率之差在一定的范围内的概率,我们只需要让这个概率越大越好。从公式,我们就可以发现,只要N越大,这个就能得到保证,看看,数据的多少也很重要。这里有两个隐形的条件:
- h是固定的,也就是说,这个公式只预先得到的h有作用;
- d的抽取,必须能够反映D的概率分布,这个很自然,如果d只能表示一部分,那我们学不全嘛,会有很多没见过的样子,怎么学。。。,所以一般都是随机抽取,而不是人工看到哪个数据顺眼选哪个,这个和直觉是相符的,我们做抽样检查就是基于这个原理;
问题又来了,机器学习的训练过程就是先确定数据,再从茫茫多(暂且理解为M个)的假设里面选取最佳的假设,这样的话hoffeding inequality就不能直接用了?当然不会,花了这么大力气隆重介绍的神奇公式最后不能用岂不很惨。首先明确,问题是什么?我们要证明:
这个东西是有上限的,这样g才能够在全集D上错误率有所保障。条件呢? 我们有M个假设,这个是预先确定的,因为机器学习算法已经定好了才能学,而我们选的g是从M中来的,所以可以得到:
在概率里面一个事件A可以推导出另一个事件B则其发生的概率是小于等于B的,所以得到了最终M个概率的和:
这个上限是很松的,而且很多机器学习算法的假设貌似是无限啊,像PLA,那可是全体直线。。。这个问题是第二章要证明的,结论肯定是,还有个更紧的上线能够保证g的错误率在d和D上接近。有了这个,我们就能够放心的选取错误率最小的假设作为g了,因为这个错误率可以泛化到全集。这里再次说明下,那我们去找错误率为0的就行了啊,可是要找到那个假设得要多少备胎啊,备胎越多M越大,泛化能力就下来了,那就有可能选到的最小的不一定在全集D表现好(例子可参见这里提到的硬币翻转实验),可见万事万物都是要平衡的。

.png)
.png)
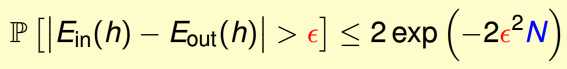
.png)
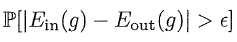
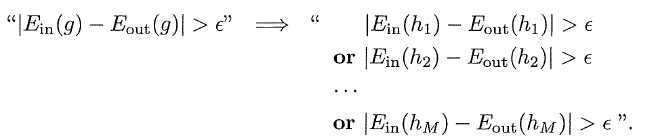
.png)