标签:
最近学了一下搜索开发的框架lucene,顺便也把在学习过程中积累的测试点给梳理一下。
毕竟身为一名测试人员,习惯性的会对测试点进行备份的。
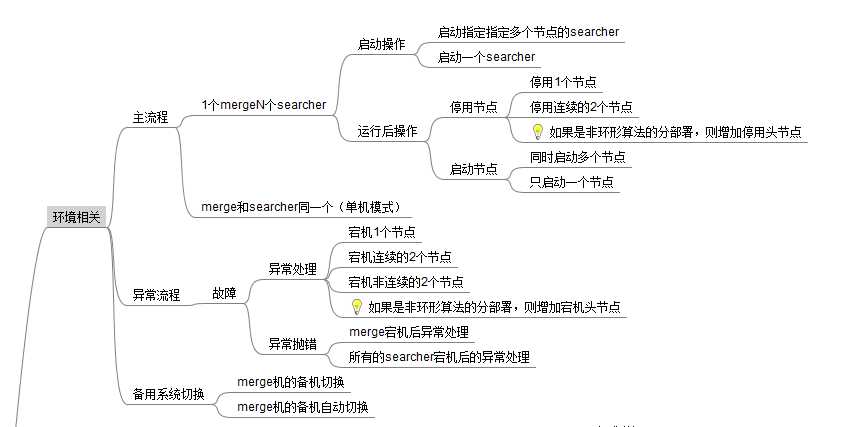
先看环境配置
对于大数据量的搜索的项目开发,那应该是离不开分布式的集群部署吧。
部署
集群模式:1个merge和N个searcher
单机模式:1个merge和1个searcher
节点的控制
启动节点
停止节点
启动部分节点
宕机的处理
节点策略,是否是hash一致的环形算法
宕机后数据是否有备份不影响使用
备份系统的切换
动态的切换主从系统
基本功能
从整个搜索的体系来看,大致分为二个部分
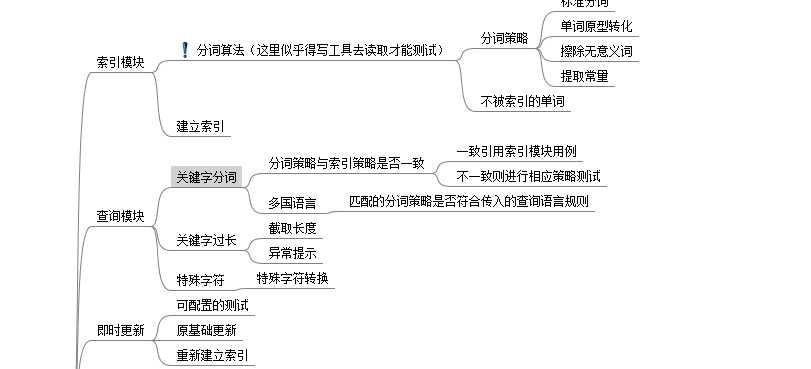
1 索引的建立机制
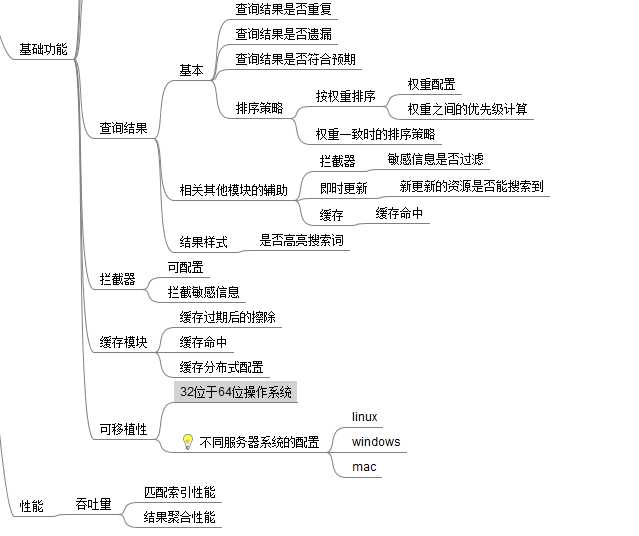
3 查询结果的聚合体系
索引体系
分词解析策略
我们知道索引的建立会经历单词的拆分与stopword、原型、提取常量等解析过程后行程;而对于结果的聚合,其实从查询开始也会经理关键字的拆解,随后是结果的聚合
聚合中需要关注:是否遗漏、是否重复、权重排序、敏感词过滤等
那么针对这些策略,我们需要配置相应的测试用例。
分词策略
1 大小写转换 ALIBABA--->alibaba
2 原型形式 learned--->learn
3 无意义的字 has a ---> 删除
4 关联词 table tennis --->table--tennis (拆分无法搜索到)
....
....
同理在搜索的时候,关键词也会经历上面的统一的一个策略逻辑
即时更新策略
1 在原来基础上更新
2 擦除全部后更新
查询结果体系
1 是否命中缓存
2 是否经历了拦截器的拦截(擦除敏感信息)
3 查询排序的策略权重
4 即时更新的内容是否被搜索到
5 结果是否重复
6 结果是否遗漏
标签:
原文地址:http://www.cnblogs.com/sunfan1988/p/4422141.html