标签:
一、前言
最近在设计数据仓库的数据逻辑模型,考虑到海量数据存储在分布式数据仓库中的技术架构模式,需要针对传统的面相关系型数据仓库的数据存储模型进行技术改造。设计出一套真正适合分布式数据仓库的数据存储模型。
二、事实表设计基础
事实表记录发生在现实世界中的操作型事件,其所产生的可度数值。事实表的设计完全依赖于物理活动,不受可能产生的最终报表的影响。事实表中,除数字度量外,事实表总是包含外键,用于关联与之相关的维度,也可以包含退化的维度键和日期/时间戳。
三、传统模式
以FS-LDM数据存储模型Event主题域数据存储模型设计为例,其事件主题域数据逻辑模型结构如下图所示:
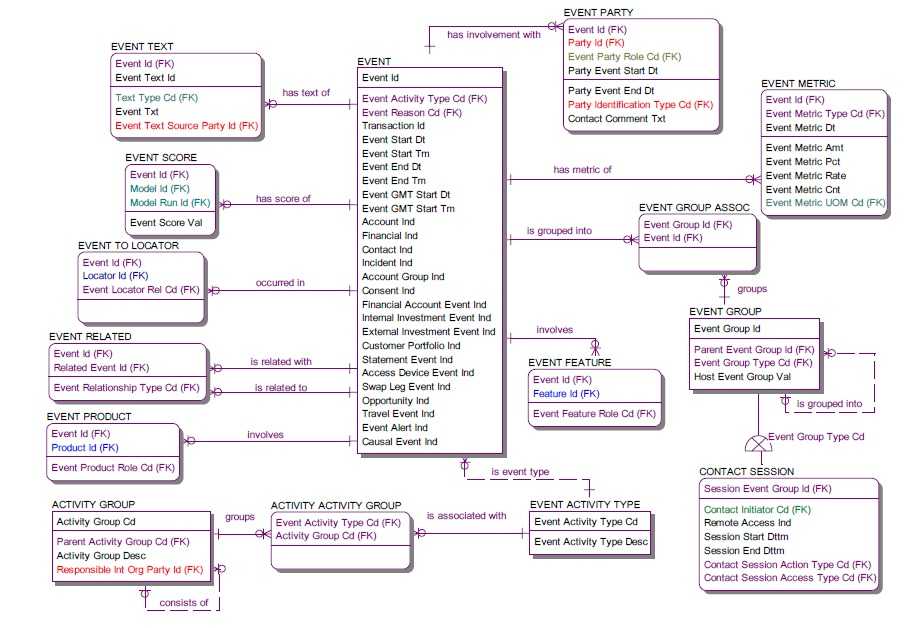
传统模式的主要问题如下:如果数据量很小的情况下,执行多表关联,没有问题,但是当在分布式数据仓库,单表存储海量数据的情况下,很明显模式将面临挑战。
三、分布式模式-维度建模新原则
(1)以值代键:针对键值唯一的维表,除非必要,否则不引入维表,如IP地址维表,采用IP作为维表的主键,事实表中存储IP值;
(2)合理分表:传统关系型数据仓库存在多表整合的冲动,如上图Event事实表,各种Acount Ind,Finance Ind等,用来扩展表的通用性,试图把所有的数据都存储到一张表 中。分布式数据仓库的设计,恰恰相反,因为单表数据规模的问题,如果要满足分析和处理的性能,合理的按照业务进行数据的分表存储。如财务相关事件、账户相关事件,单独成表。更有利于数据的计算和分析。
四、分布式维度模型实例
| 序号 | 字段英文 | 字段中文 | 字段解释 | 字段映射 | 字段加工逻辑 | 指标字段 |
| 1 | event_id | 事件ID | 记录标识 | 标识 | ||
| 2 | tm | 时间 | 时间戳 | 维度 | ||
| 3 | domain | 域 | 维度-值 | |||
| 4 | ip | IP地址 | IP地址 | 维度-值 | ||
| 5 | os | 操作系统 | 操作系统 | 维度-值 | ||
| 6 | user_id | 用户ID | 用户ID | 维度-FK | ||
| 7 | date | 日期 | 日期(新增) | 维度-值 | ||
| 8 | from | 来源 | 访问来源系统 | 维度-值 |
五、未完待续
分布式数据仓库数据存储模型设计进行中,后续会持续更新,请关注QQ群:分布式数据仓库建模 398419457。
标签:
原文地址:http://www.cnblogs.com/hadoopdev/p/4425715.html