标签:
在完成分析Hadoop2源码的准备工作后,我们进入到后续的源码学习阶段。本篇博客给大家分享,让大家对Hadoop V2有个初步认识,博客的目录内容如下所示:
本篇文章的源码是基于Hadoop-2.6.0来分析,其他版本的Hadoop的源码可以此作为参考分析。
其实,早年Google的核心竞争力是它的计算平台,Google对外公布的论文有一下内容:
MapReduce
可见MapReduce并不是Hadoop所独有的功能,之后Apache基金会得到类似的项目,这些项目有隶属于Hadoop项目,分别是:
类似于这种思想的开源项目还有很多,如:Yahoo用Pig来处理巨大数据,Facebook用Hive来进行用户行为分析等。Hadoop的两大核心功能分别为HDFS和MapReduce,MapReduce是一个适合做离线计算的框架,它依赖于HDFS,HDFS作为一个分布式文件存储系统,是所有这些项目的基础支撑。下图为HDFS的支撑图,如下图所示:

Hadoop包与包之间依赖的关系较为复杂,究其原因为HDFS提供了一个分布式文件存储系统,该系统提供庞大的API,使得分布式文件系统底层的实现,依赖于某些高层的功能,这些功能互相引用,形成网状的依赖关系。举个例子,如conf包,它用于读取系统配置文件,依赖于fs包,主要是读取相应的配置文件时,需要使用到文件系统,而部分文件系统的功能都被抽象在fs包中。下图时Hadoop V2项目的核心部分依赖包,如下图所示:
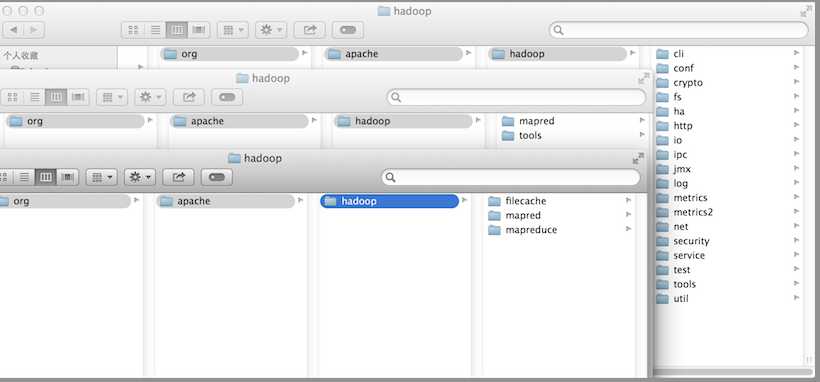
后面的章节,主要给大家分享以下几个部分,如:mapreduce,fs,hdfs,ipc,io,yarn。
下面对上图列出来的各个包做下介绍说明,各个包的功能如下所示:
Hadoop V2在底层设计上对比Hadoop V1是有区别的,新增HA,使得Hadoop V1中存在的单点问题得到了很好得解决;Hadoop V2新增Yarn系统,使得集群得资源管理和调度更加得完美,大大减少ResourceManager的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。同时,使得多种计算框架可以运行在一个集群中。
这篇文章就和大家分享到这里,如果大家在研究和学习的过程中有什么疑问,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4427985.html