这里简要的讨论 hybrid network 与一些时序数据的分析。
hybrid network 指网络中存在离散随机变量与连续随机变量,这种情况下一般非常麻烦,这主要是因为连续型随机变量需要使用某个参数族来进行刻画,某些情况下对应的 margin 却不属于给定的参数族。常用的处理手段是离散化,即将某些连续分布离散化成为离散随机变量,这样虽然处理起来容易,但是会丢失非常多的信息,也引入了一个也非常困难的问题,如何离散化才有意义?很显然离散化只是为了计算效率进行近似的折衷。因此关于 hybrid network 的讨论其实主要集中在一些特殊情况。前面讲过的 Gaussian network 是一种分析性质良好的连续 r.v.s.,我们首先讨论一下前面一些技术在它上面的应用,继而讨论上面 hybrid network 的性质、近似与精确 inference 的策略。
我们首先引入所谓的 canonical form,这其实和 exponential family 的有一定相似
我们不难获得这些参数与矩参数 
在引入了离散随机变量后 Gaussian network 的表示往往都是随变量个数增加,参数指数的增加(表示就困难了),因此也很容易证明,此类问题下即便网络是 polytree,甚至离散的是二值的 r.v.s. 问题都将成为 NP-hard。一种直接的想法就是将 message 进行简化,我们知道某些 Gaussian 在 marginalize 掉离散变量后就成为了 mixture of Gaussians,这时我们需要进行近似避免该 message 过于复杂,这一般是使用单个的 Gaussian 进行 M-projection。这样做虽然是一种“可行”的策略,但是往往获得的 Gaussian 并非“正常的”(负方差)。这时有一类所谓 Lauritzen 算法,可以提供正确性和计算有效性上的折衷(看来这个 Lauritzen 算法总是要好好研究下的)。
如果 r.v.s. 之间的关系不再是 linear 情形(比如前面的 CLG),我们往往需要对这类后验关系进行近似,最常见的做法就是所谓的 Laplace approximation,即用一个 Gaussian 去逼近后验。更一般的想法是使用 Taylor 展开,进行更高阶的近似。Laplace approximation 可以认为是使用二阶在 M-projection 下进行的近似。对某些情况下的积分虽然是没有解析解,但是由于是 Gaussian 下积分,我们仍然可以用一些数值解法获得相对精确的解。另外一种思路自然是借助 sampling,这类 network 往往 forward sampling 容易进行,另外 MCMC 与 collapsed sampling 也容易应用到这类问题上,总算是提供了一种“万能”的笨办法。
在时序问题中,最常见的是下面三类 inference 问题:
")
")
")
前两者的计算其实是耦合在一起的,因为我们可以利用前者推出后者,
而后者到前者,我们只需要用一下 Bayesian 公式
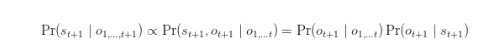
smoothing 的计算一般也并不麻烦,我们只需要使用 dynamic programming 即可(这是标准的 MAP)。说穿了这都是常见的 inference 问题,如果我们不考虑时序结构直接应用前面的算法势必会比较麻烦。比较理想的情况就是根据这个时间关系进行求解。但要注意,很多情况下可能会出现 entanglement 导致这类做法变得复杂起来,也就是 state 之间还存在另外的路径,可以证明所谓的 fully persistent BN 是不可能单独 track 当前状态的分布的(entanglement theorem),由于存在 entanglement,我们只能用整个联合分布来表达。其实我们使用的不少模型都是避免了 entanglement,当 entanglement 存在的时候我们常见的策略就是使用近似:
对连续变量来说,常见的就是 LDS 这种 model 了,其中的重要算法包括 Kalman filter、pariticle filtering。
我们后面将对一些常用的模型(如 HMM、LDS 和 chain CRF)进行相关的推导,这三者是不需要近似算法的。
—————–
And Sarah said, God has made me to laugh, so that all that hear
will laugh with me.
原文地址:http://www.cnblogs.com/focus-ml/p/3775459.html
 = \exp\left( -\frac{1}{2} X^\top K X + h^\top X + g\right)")
 = \sum_{s_t} \Pr(s_{t + 1} \mid s_t) \Pr (s_t \mid o_{1, \ldots t})")