标签:

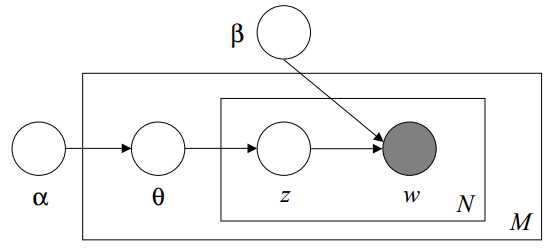
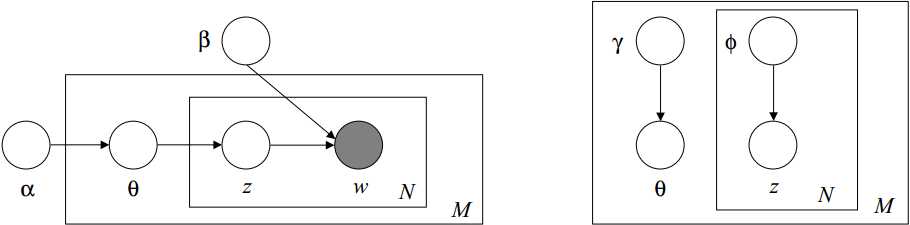
$L=E_q(logp(\theta,z,w|\alpha,\beta))-E_q(logq(\theta,z|\gamma,\phi))\\\ \ \, =E_q(logp(\theta|\alpha)p(z|theta)p(w|z,\beta))-E_q(logq(\theta|\gamma)q(z|\phi))\\\ \ \,=E_q(logp(\theta|\alpha))_{[1]}+E_q(logp(z|\theta))_{[2]}+E_q(logp(w|z,\beta))_{[3]}-E_q(logq(\theta|\gamma))_{[4]}-E_q(logq(z|\phi))_{[5]}$
$[1]=\int q(\theta|\gamma)log [\frac{\Gamma(\sum_i \alpha_i)}{\prod_i\Gamma(\alpha_i)}\prod_i \theta_i^{\alpha_i-1}]d\theta\\\ \ \ \ =\int q(\theta|\gamma)(log\Gamma(\sum_i \alpha_i)-\sum_i log\Gamma(\alpha_i)+\sum_i (\alpha_i-1)log\theta_i)d\theta\\\ \ \ \ =log\Gamma(\sum_i \alpha_i)-\sum_i log\Gamma(\alpha_i)+\sum_i (\alpha_i-1)(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))$
$[2]=\int q(\theta|\gamma)\sum_{n=1}^N \sum_i \phi_{ni}log\theta_i) d\theta \\\ \ \ \ = \sum_{n=1}^N \sum_i \phi_{ni}(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))$
$[3]=\sum_{n=1}^N \sum_i \sum_{j=1}^V \phi_{ni}w_n^jlog\beta_{ij}$ $w_n^j$表示$w_n$的第j个分量
$[4]=\int q(\theta\gamma)log [\frac{\Gamma(\sum_i \gamma_i)}{\prod_i\Gamma(\gamma_i)}\prod_i \theta_i^{\gamma_i-1}]d\theta\\\ \ \ \ =log\Gamma(\sum_i \gamma_i)-\sum_i log\Gamma(\gamma_i)+\sum_i (\gamma_i-1)(\Psi(\gamma_i)-\Psi(\sum_j \gamma_i))$
$[5]=\sum_{n=1}^N \sum_i \phi_{ni} log \phi_{ni}$
E-step(固定$\alpha$,$\beta$,对每份文档优化$\gamma$,$\phi$,以最大化L)
1.优化$\phi$
L中和$\phi$相关项:
$L_{[\phi]}=\sum_{n=1}^N \sum_i \phi_{ni}(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))+\sum_{n=1}^N \sum_i \sum_{j=1}^V \phi_{ni}w_n^jlog\beta_{ij}+\sum_{n=1}^N \sum_i \phi_{ni} log \phi_{ni}$
限制条件为:$\sum_i \phi_{ni}=1$,使用拉格朗日乘数法,加$\lambda(\sum_i \phi_{ni}-1)$,对$\phi_ni$求导得到:
$\frac{\partial L}{\partial \phi_{ni}}=\Psi(\gamma_i)-\Psi(\sum_j \gamma_j)+log(\beta_{iv}-log\phi_{ni})-1+\lambda$ $beta_{iv}$表示第i个主题下单词$w_n$出现的概率
令上式为0
$\phi_{ni}=\beta_{iv}exp(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))exp(\lambda-1)$
注意:在实际代码中,在更新完$\phi_{ni}$后,需要进行正规化(使相加为1),所以后面的公共项$exp(-\Psi(\sum_j \gamma_j))exp(\lambda-1)$不用计算
2.优化$\gamma$
L中和$\gamma$有关的项:
$L_{[\gamma]}=\sum_i (\alpha_i-1)(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))+\sum_{n=1}^N \sum_i \phi_{ni}(\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))-log\Gamma(\sum_i \gamma_i)+\sum_i log\Gamma(\gamma_i)-\sum_i (\gamma_i-1)(\Psi(\gamma_i)-\Psi(\sum_j \gamma_i))\\ \ \ \ \ \ \ =\sum_i (\Psi(\gamma_i)-\Psi(\sum_j \gamma_j))(\alpha_i+\sum_n \phi_{ni}-\gamma_i)-log\Gamma(\sum_i \gamma_i)+\sum_i log\Gamma(\gamma_i)$
对$\gamma_i$求导得到:
$\frac{\partial L}{\partial \gamma_i}=\Psi ‘(\gamma_i)(\alpha_i+\sum_n \phi_{ni}-\gamma_i)-\Psi ‘(\sum_j \gamma_j)\sum_j(\alpha_j+\sum_n \phi_{nj}-\gamma_j)$
令上式为0
$\gamma_i=\alpha_i+\sum_n \phi_{nj}$
代码实现中需要初始化$\gamma_i=\alpha_i+N/k$($Dir(\gamma)$为后验分布,在给定每个单词的主题后,可以计算得到$\gamma$的值)
M-step(固定每份文档的$\gamma$,$\phi$,优化$\alpha$,$\beta$,以最大化$\sum_{d=1}^ML$,提高似然函数的下界)
1.优化$\beta$
L中和$\ beta $相关的项,加上拉格朗日乘子式($\sum_{j=1}^V \beta_{ij}-1=0$):
$\sum_{d=1}^ML_{[\ beta]}=\sum_{d=1}^M\sum_{n=1}^{N_d}\sum_{i=1}^k\sum_{j=1}^V \phi_{dni}w_{dn}^jlog\beta_{ij}+\sum_{i=1}^k\lambda_i(\sum_{j=1}^V \beta_{ij}-1)$
对$\beta_{ij}$求导:
$\frac{\partial L}{\partial \beta_{ij}}=\sum_{d=1}^M\sum_{n=1}^{N_d}\phi_{dni}w_{dn}^j/\beta_{ij}+\lambda_i$
令上式为0
$\beta_{ij}=-\frac{1}{\lambda_i}\sum_{d=1}^M\sum_{n=1}^{N_d}\phi_{dni}w_{dn}^j$
注意:在实际代码中,在更新完$\beta_{ij}$后,需要进行正规化(使相加为1),所以公共项$-\frac{1}{\lambda_i}$不用计算
2.优化$\alpha$
L中和$\alpha$相关的项:
$\sum_{d=1}^ML_{[\alpha]}=\sum_{d=1}^M(log\Psi(\sum_{i=1}^k \alpha_j)-\sum_{i=1}^k log\Psi(\alpha_i)+\sum_{i=1}^k(\alpha_i-1)(\Psi(\gamma_{di})-\Psi(\sum_{j=1}^k \gamma_{dj})))$
对$\alpha_i$求导:
$\frac{\partial L}{\partial \alpha_i}=M(\Psi(\sum_{j=1}^k \alpha_j)-\Psi(\alpha_i))+\sum_{d=1}^M(\Psi(\gamma_{di}-\Psi(\sum_{j=1}^k \gamma_{dj})))$
由于上式和$\alpha_j$相关,考虑使用newton法求解,迭代公式如下:
$\alpha_{t+1}=\alpha_k+H(\alpha_k)^{-1}g(\alpha_k)$ 这里求最大值,所以有$+$号,如果求最小值,要用$-$号
此处$H$为Hessian矩阵,$g$为梯度向量(即$\frac{\partial L}{\partial \alpha_i}$)
$H_{ij}=\frac{\partial L}{\partial \alpha_i\alpha_j}=\delta(i,j)M\Psi ‘(\alpha_i)-M\Psi ‘(\sum_{j=1}^k \alpha_j)$ $\delta(i,j)=1\quad if\ i=j$
hession矩阵具有以下形式:
$H=diag(h)+1\,Z\,1^T$
其中$h_{i}=M\Psi ‘(\alpha_i)$,$Z=-M\Psi ‘(\sum_{j=1}^k \alpha_j)$
所以在计算$H^{-1}g$时,可以用以下公式计算:
$(H^{-1}g)_i=\frac{g_i-c}{h_i}$ $c=\frac{\sum_{j=1}^k g_j/h_j}{\frac{1}{Z}+\sum_{j=1}^k \frac{1}{h_j}}$
LDA(latent dirichlet allocation)
标签:
原文地址:http://www.cnblogs.com/porco/p/4435249.html