我们在网上购物或者逛一些论坛、社区时往往都会发现购物时会参考其他用户是如何评价这个商品的。逛社区,如知乎之类时我们看一些东西往往只会看排在前几个的答案,而基本会忽略掉后面众多的答案。除非你是瞎混时间,如玩豆瓣,一层层楼扒,不落下任何词句。
然而,很多购物网站、社区各自评论排列是不一样的规则,有的仅仅按照评论、答案更新时间排序,或者因为各自规则不同而导致我们会错过一些对我们决策的有用信息。就拿购物来说,可能最终会影响到我们是否下单,下单转化率降低,用户体验不佳。

那么,我们可以如何让有效的,优秀的评论or答案尽量不被隐藏or淹没在海量信息中呢?
主体思路主要是:如何把有价值的信息(好的或不好的)推到用户最容易获取的地方,将对用户没有价值或用户不感兴趣的信息尽量放在底层。
最近忽然很火的今日头条为什么会火?大的道理不说,大致也是因为他们做到了以上那点。
前面给分析了基本方向,接下来讲讲评论这块影响排序的因素主要有哪些。
目前想到的影响排序因素
1.内容相关性
评论与主题相关才有意义。你如果卖手机,人家评论内容给你贴大段小说内容,尽管是五星好评,这样的内容对用户参考价值会很大吗?
2.评论长短
内容与主题相关后,写的越长的一般会认为越倾向于优质。但其实大家知道并非必然联系。但这块却只能这么操作。经常性有的商家为了鼓励用户做长评而奖励,如聚美的优质评价送代金券就有类似的赶脚。
3.评论时间
你14年6月份来买东西肯定不希望看到要买的这个东西最新的一条评论是12年留下的吧?评论时间越靠近用户购物决策时间,用户越信任该评论。
4.优质评论/置顶评论
一般是管理人员来操作,类似于豆瓣小组的置顶话题、当当网的加精评论等等。
5.评论回复数
越多回复表示用户越感兴趣,根据用户回复情况我们也可以据此判断该评论的真实性。有趣的一个问题,之前购买手机看到一款好评,而且是排前1-2个位置的,用户购机才不到一个月,但是评论里居然写体验了2个月了。底下引起其他看评论的人围观,说是该品牌请了马甲。但对于类似有可能掺水的评论机器很难实现判别。
6.用户被like/dislike的数量,有的地方叫顶/有用
该数量体现了用户对该评论or答案的满意程度。有的网站就是以该规则为第一条,被顶越多则排在第一位置。例如后文将提到的reddit、知乎好像这块也类似。
7.评论星级
一般星级越高代表对该产品的购买体验越好。
从总体来看,第一条应该是最重要的一点,抛开第一点后其他的点即使有也不是太有意义。
以下,简单分析几个网站评论排序:
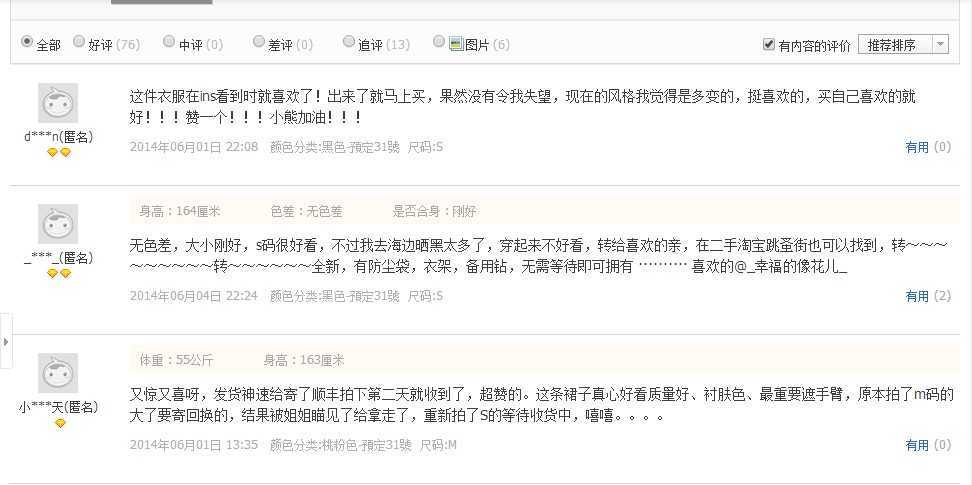
1.京东评论排序分析
简单研究了下,大概思路应该是有个评论推荐机制来执行:
主要是相关性/评论星级/评论长短/标签数/晒图数/评论下互动数/评论时间/有用数
这些点各自安排不同权重来打分,有管理员来不定期调整权重来影响这些评论排名的。机器通过评论下互动数以及有用数对评论真实性可以进行推算。
有个问题是:如何智能处理文不对题的评论?例如,有的用户明明购买了手机,其他都正常唯独评论里的内容是牛头不对马嘴,这类型的问题如果频发,机器如何处理?
另外,标签这块,对京东这块进行了一些猜测:应该是对某类型的产品都统一用一套标签数据库的,在产品推出后则配备基本标签?那这些标签是用什么机制配备的?能否有一种算法来实现不需用户自己选择标签,机器能够实现直接从用户发表的评论自动提取对应的标签?想了下,应该是可以将用户评论进行词汇拆解,然后做机器处理,但具体如何实现估计挺有技术难度!
最后,关于评论下互动数,有的评论互动很长,但是京东这块都展示了,有些影响用户体验,个人感觉如果能加上收起按钮,语序用户收起互动评论体验起来会更好。
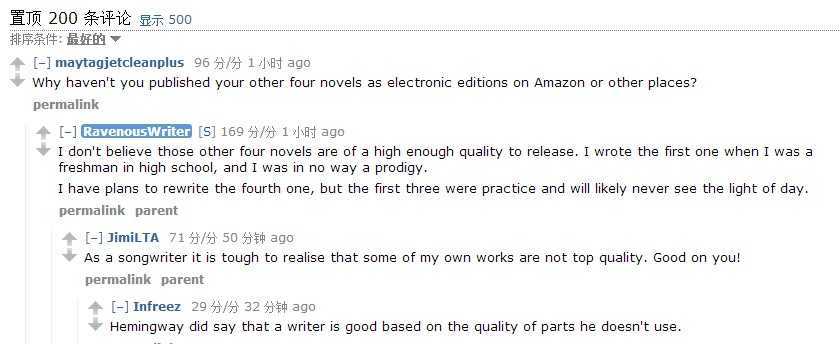
2.Reddit评论排序分析
“Best”排序(之前有Top/Hot/New/Controversial/Old)
大概思路是,有人对评论like,则数据库会进行采集,评论越多,like的越多,则机器越能精确判定该评论的排名。通过对精确程度的量化,从用户的like中尽可能推算出评论真实质量。机器从like与dislike数据库中抽样统计,计算出置信区间,我们第一步对这些区间进行排名,这个暂时排名比较的是这些评论最终排名100在一百次统计中95次可能落在的区间。对于抽样数据需要在数量上有保证,不然系统仍然会将其排在低位。10like+1dislike are better than 50like+25dislike. 前者会排在后者前面,通过概率计算结果来推算。即使后面证明这块有误差,但随着数据库收集的like与dislike样本变更,新抽样数据也会纠错。最终,优秀评论会得到置顶高位,欠佳评论只在底部。
问题是:拥有很多like or dislike的偏向于会吸引更多同类投票,仍然会有偏袒的效应存在,但比起光以时间优先排列,抢沙发、板凳来说还是优化了很多。
关于案例分析,以后会陆续补充淘宝、亚马逊的评论排序分析。
总结
1.可能有很多人会觉得这些因素我们都知道了,那如何安排权重呢?我觉得这块还是得看数据说话,比如小样本测试orA/B测试。
概念普及下:
小样本测试,举例来说,比如每个用户有user id,我们取能够整除5的用户来体验新设定的规则,然后根据他们体验的最终数据来对比没有变更规则的用户数据,据此来判定新规则是否有效。
A/B测试,制作A/B两套不同的权重安排规则,随机推荐给用户使用,最终来对比2套方案出来的用户数据,根据数据来最终判定哪组效果更好则选定哪组。
采用以上方法效果分析维度主要是几个因素:pv增长率、点击购买率、转化率、用户体验等等。
2.内容相关性这块主要有2种方向,一种是将用户评论分词,将句子拆分成名词、动词、形容词等等,然后计算该评论与该商品简介、其他用户评论等词汇相关性。这块还需要结合其他用户对该评价的评论等动作来综合识别是否评论靠谱。这种比较局限性,容易忽略掉用词方面比较个性化的优质评论。另一种是是将文档转换为特征向量后,就可以计算文档之间或者是查询和文档之间的相似性了。
3.评论排序规则一旦变更对商家来说影响很大,作为商家需要保证自己是商品订单量提升需要时刻保持关注这点,这也是为什么有的淘宝商家找水军买假好评的原因了。
ANY REPLY WILL BE HIGHLY APPRECIATED。
原文地址:http://www.cnblogs.com/qiansiqi/p/3775693.html