标签:
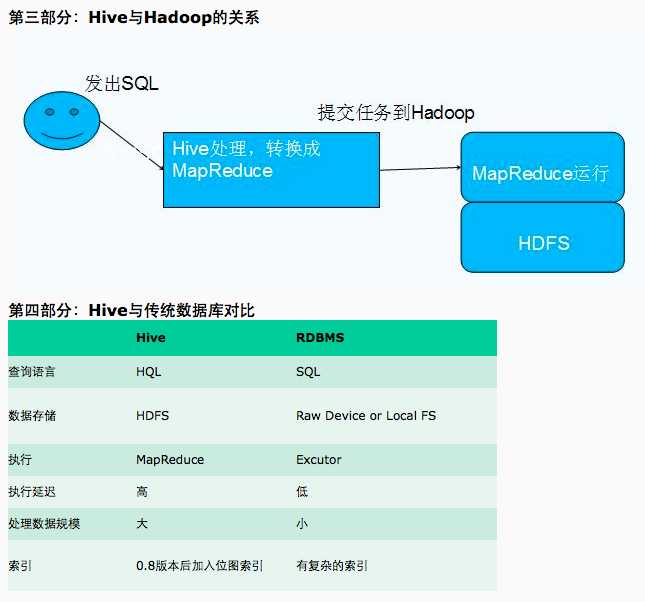
Hive是基于Hadoop文件系统上的数据仓库架构。
它为数据仓库的管理提供了许多功能:
数据ETL(抽取,转换和加载)工具
数据存储管理
大型数据集的查询与分析
定义了类SQL的语言——Hive QL
Hive的数据存储是建立在Hadoop文件系统之上的。Hive本身没有专门的数据存储格式,也不能为数据建立索引,用户可以非常自由地组织Hive中的表,只需在创建表时告诉Hive数据中的列分隔符和行分隔符就可以解析数据了。
Hive主要包括4类数据模型:表,外部表,分区,桶。
Hive中的表和数据库中的表在概念上类似,每个表在Hive中都有一个对应的存储目录。
Hive中每个分区对应数据库中相应分区列的一个索引,但分区的组织方式和传统关系型数据库不同。在Hive中,表中的一个分区对应表下的一个目录,所有分区的数据都存储在对应目录中。
Hive的特点
标签:
原文地址:http://www.cnblogs.com/jawiezhu/p/4437013.html