标签:
常见的编码与字符集
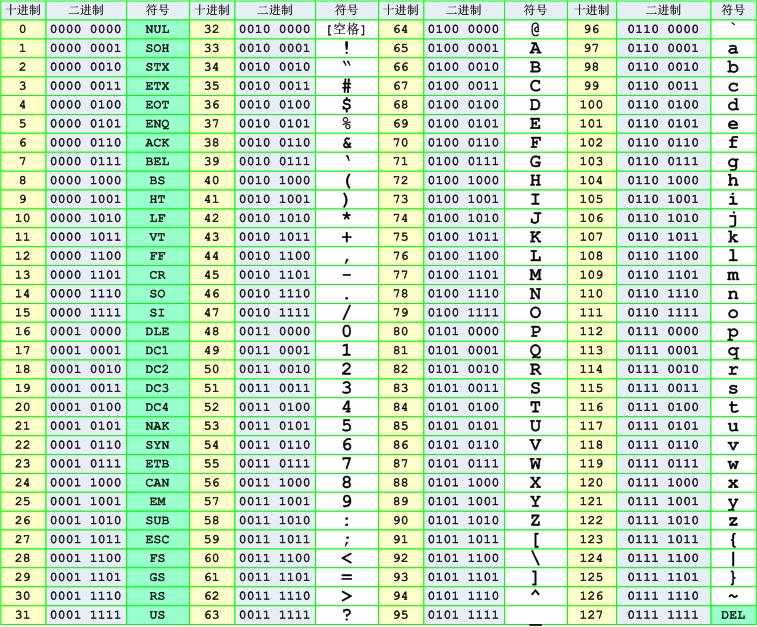
ASCII 被 ISO (International Standardization Organization,国际标准化组织)批准为国际标准。
但是 ASCII 码只包含英文和数字和一些控制符号等有限的符号,只够美国人用。对于其他国家的人,想表示自己的语言就得自己想办法了。
GB2312 编码
GB2312是适合中国人使用的编码,由中国国家标准总局发布。它主要分为两个部分:
127之前的符号跟 ASCII 码所表示的意义相同。都是一个字节表示。
127之后的符号统一用两个字节表示,包含了几乎所有的简体中文字。允许
台湾和香港那边喜欢用繁体字,GB2312 编码只包含简体中文,显然不够他们用,于是台湾和香港用包含了繁体字的 BIG5 编码,叫大五码,这里不做解释。
GBK 编码
GBK 编码的前半部分跟GB2312完全相同,还往后扩展了更多的汉字,包括几乎所有常见的不常见的汉字、繁体字、日语的平假名和片假名、俄文字母。
可以说GBK适用于中国大陆、台湾、香港、日本和俄国。虽然适合日本用,估计日本也不会用GBK 编码。确实,日本用的是JIS编码。
虽然增加了繁体字,但是GBK跟BIG5还是不兼容。
貌似从windows 95以后的操作系统都是以GBK为基础汉字编码。
ANSI 编码
ANSI编码不是一种特定的编码。
在简体中文系统下,ANSI编码代表着GB2312 编码;
在日文操作系统下,ANSI编码代表着JIS编码
Unicode编码
各个国家都像中国一样搞出自己的一套编码系统。这对于软件的国际化是一种转换上的灾难。
ISO(国际标准化组织)决定着手解决这个问题,废除了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码。跟以前现有的任何编码都不兼容。
Unicode编码和 UTF 编码之间的关系
UTF-8,UTF-16,UTF-32都是对Unicode的编码。不同的是组织形式。
UTF-8
UTF-8的特点是对不同范围的字符使用不同长度的编码。
对于0~127,完全跟 ASCII 相同。使用一个字节。
从Unicode到UTF-8的编码方式如下:
| Unicode编码(16进制) | 十进制表示 | 幂表示 | UTF-8 字节流(二进制) | 所占字节数 |
| 000000 - 00007F | 0-127 | 0-(27-1) | 0xxxxxxx | 1 |
| 000080 - 0007FF | 128-2047 | 27-(211-1) | 110xxxxx 10xxxxxx | 2 |
| 000800 - 00FFFF | 2048-65535 | 211-(216-1) | 1110xxxx 10xxxxxx 10xxxxxx | 3 |
| 010000 - 10FFFF | 65536-1114111 | 216-(216+220-1) | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 |
UTF-16
对于所有的字符都用两个字节来表示。
优点是长度固定。在Java语言中,字符就是采用了UTF-16的编码方式。缺点是跟ASCII不兼容。
UTF-32
对所有的字符都用32bit即4个字节来表示。
太浪费空间了,一般不用。
Base64编码
Base64编码不像以上提到的编码,主要用于在计算机内表示字符的编码。Base64编码是网络上最常见的用于传输8Bit字节代码的编码方式之一。
其详细规范由MIME在rfc2045~rfc2049标准中规定。
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
若要处理的数据长度不是3的倍数,可能是余1或者余2。则在后面添加2个或者1个=来填充。所以你见到的Base64编码的数据末尾常有=,但最多不会超过2个。
由于转换后的数据最大只能为0011 1111等于十进制的63。所以编码表只需要有63个字符即可。
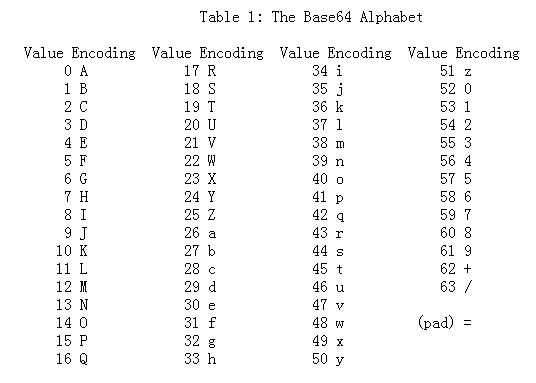
以上为Base64的编码表。
可见,若看到一段数据只包含大小写字母、数字、加号+和正斜杠 / 以及末尾有可能有=,那么该编码十有八九是Base64编码。
Base64可用于简单的网络加密,但是它所实现的只是不能让你一眼就能看出来明文是什么。称它为编码还更适合一点。
转自:http://www.cnblogs.com/infosec-hoary/archive/2012/02/28/2371385.html
标签:
原文地址:http://www.cnblogs.com/harry335/p/4441470.html