标签:
朴素贝叶斯(Naive Bayes)适用于离散特征的分类问题,对于连续问题则需将特征离散化后使用。朴素贝叶斯有多元伯努利事件模型和多项式事件模型,在伯努利事件模型中,特征每一维的值只能是0或1,而多项式模型中特征每一维的值可取0到N之间的整数,因此伯努利模型是多项式模型的一种特例,下面的推导就直接使用伯努利模型。
朴素贝叶斯原理推导
与GDA类似,朴素贝叶斯对一个测试样本分类时,通过比较p(y=0|x)和p(y=1|x)来进行决策。根据贝叶斯公式:
\( \begin{aligned} p(y=1|x)=\frac{p(x|y=1)p(y=1)}{p(x)} \end{aligned}\)
其中x是一个多维向量,\(x=(x_1,x_2,…,x_n)\),则
\( \begin{aligned} p(x|y)=p(x_1|y)p(x_2|y,x_1)p(x_3|y,x_1,x_2)…p(x_n|y,x_1,x_2,…,x_{n-1}) \end{aligned}\)
上面这个式子如此多的条件概率,可没法求呀。那么就限定一下条件,使得特殊情况下可以求解,于是就有了下面这个很Naive的假设:
在给定类别y的条件下,\(x_i\;(i=1,2,…,n)\)直接相互独立。
这个假设表达的意思是在每个类别内部,特征x的每一维与其他维没有关系,需要注意的是此条件独立并不等价于完全独立。这个假设的直观表达是:
\( \begin{aligned} p(x_i|y,x_j)= p(x_i|y,x_j)\;(all\; i \neq j) \end{aligned}\)
基于此假设,上面的公式就可写成:
\( \begin{aligned} p(x|y)=p(x_1|y)p(x_2|y)p(x_3|y)…p(x_n|y)=\prod_{i=1}^n{p(x_i|y)} \end{aligned}\)
对于一个训练样本集合\( \{(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\}\),\(x^{(i)}=(x^{(i)}_1,x^{(i)}_2,...,x^{(i)}_n)\),\( n_i=\sum_{j=1}^n{x^{(i)}_j}\),其似然函数为:
\( \begin{aligned} L&=\prod_{i=1}^m{p(x^{(i)},y^{(i)})} \\&=\prod_{i=1}^m{p(x^{(i)}|y^{(i)})p(y^{(i)})} \\&=\prod_{i=1}^m{\prod_{j=1}^{n_i}p(x^{(i)}_j|y^{(i)})p(y^{(i)})} \end{aligned} \)
与高斯判别分析中的推导类似,对似然函数取对数并最大化,通过求导可求解出:
\( \begin{aligned} \phi_{k|y=1}=p(x^{(i)}=k|y=1)=\frac{\sum_{i=1}^m{\sum_{j=1}^{n_i}I(x^{(i)}_j=k\;and\;y^{(i)}=1)}}{\sum_{i=1}^m{I(y^{(i)}=1)n_i}}\end{aligned}\)
\( \begin{aligned} \phi_{k|y=0}=p(x^{(i)}=k|y=0)=\frac{\sum_{i=1}^m{\sum_{j=1}^{n_i}I(x^{(i)}_j=k\;and\;y^{(i)}=0)}}{\sum_{i=1}^m{I(y^{(i)}=0)n_i}}\end{aligned}\)
\( \begin{aligned} \phi_y=p(y=1)=\frac{\sum_{i=1}^m{I(y^{(i)}=1)}}{m} \end{aligned}\)
式中I为指示函数。
拉普拉斯平滑
对于上面推导的公式,假设\(x_i\)的理论取值范围是0~99,但我们的训练样本中,没有任何一个样本中出现过99这个值,那么按照上面贝叶斯公式计算,会出现0/0的情况。基于这一点,对上面公式做一点修正,如下所示:
\( \begin{aligned} \phi_{k|y=1}=p(x_i=k|y=1)=\frac{\sum_{i=1}^m{\sum_{j=1}^{n_i}I(x^{(i)}_j=k\;and\;y^{(i)}=1)}+1}{\sum_{i=1}^m{I(y^{(i)}=1)n_i}+N} \end{aligned}\)
\( \begin{aligned} \phi_{k|y=0}=p(x_i=k|y=0)=\frac{\sum_{i=1}^m{\sum_{j=1}^{n_i}I(x^{(i)}_j=k\;and\;y^{(i)}=0)}+1}{\sum_{i=1}^m{I(y^{(i)}=0)n_i}+N} \end{aligned}\)
式中N即是\(x_i\)理论取值数。如此修正意义何在?做上述修正,对于理论上可能存在的状态,基本其多次试验没有发生,但我们也不否认其存在的可能性,只是认为其出现的可能性很小而已。一个直观的例子,我们都知道抛硬币正反面的概率都为0.5,但你抛100次却每次都是正面,即便如此相信你也不会认为抛出反面的概率是0吧?不过出现如此现象则可能让我怀疑此硬币设计有什么问题导致出现反面的概率如此之低。
朴素贝叶斯实现
到这里算法实现基本就是按照上面的公式来进行训练和判别了,在matlab的训练代码为:

1 %phi_0(k)=p(x_i=k|y=0) for any i 2 %phi_1(k)=p(x_i=k|y=1) for any i 3 %phi=p(y=1) 4 function [phi_0, phi_1, phi] = NaiveBayesTrain(Feature, Label, V) 5 idx0 = find(Label == 0); 6 idx1 = find(Label == 1); 7 8 %calc phi_y 9 phi = length(idx1) / length(Label); 10 11 n = sum(Feature, 2); 12 n0 = sum(n(idx0)); 13 n1 = sum(n(idx1)); 14 15 phi_0 = (sum(Feature(idx0, :), 1) + 1) / (n0 + V); 16 phi_1 = (sum(Feature(idx1, :), 1) + 1) / (n1 + V); 17 end
在判别时,理论上需要计算出p(y=0|x)和p(y=1|x)的值,但实际应用时,只需比较二者大小即可,他们分母都相同,可以忽略,分子部分两边取对数可简化为判断\( log\;p(x|y=1)+log\;p(y=1)\)和\( log\;p(x|y=0)+log\;p(y=0)\)的大小,具体代码如下:
1 function label = NaiveBayesDiscriminate(phi_0, phi_1, phi, Feature) 2 log_p0 = Feature * (log(phi_0))‘ + log(1 - phi); 3 log_p1 = Feature * (log(phi_1))‘ + log(phi); 4 label = log_p0 < log_p1; 5 end
测试数据采用Andrew Ng网站上给出的垃圾邮件特征,特征如下:


第1列代表邮件编号,第二列代表单词在词典的次序,第三列代表该单词出现的次数,对应的训练和测试样本数据在这里。测试代码为:
1 clear all; clc 2 3 %训练样本数 4 numTrainDocs = 700; 5 %字典单词数,即每个x_i取值范围 6 numTokens = 2500; 7 8 %读取训练样本特征文件以及标签,转换为700x2500的矩阵,每行代表一封邮件 9 train_labels = dlmread(‘train-labels.txt‘); 10 M = dlmread(‘train-features.txt‘, ‘ ‘); 11 spmatrix = sparse(M(:,1), M(:,2), M(:,3), numTrainDocs, numTokens); 12 train_matrix = full(spmatrix); 13 14 %naivebayes训练 15 [phi_0, phi_1, phi] = NaiveBayesTrain(train_matrix, train_labels, numTokens); 16 17 %读取测试样本,格式同上 18 test_labels = dlmread(‘test-labels.txt‘); 19 N = dlmread(‘test-features.txt‘, ‘ ‘); 20 spmatrix = sparse(N(:,1), N(:,2), N(:,3)); 21 test_matrix = full(spmatrix); 22 23 %naivebayes测试 24 label = NaiveBayesDiscriminate(phi_0, phi_1, phi, test_matrix); 25 26 %计算正确率 27 err = sum(abs(label - test_labels)); 28 str = sprintf(‘result:err/all: %d / %d [%.2f%%]‘, err, length(test_labels), 100 * err / length(test_labels)); 29 disp(str)
测试输出结果为:
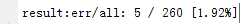
即错误率仅为1.9%。
算法分析
1.朴素贝叶斯那个很朴素的假设是条件独立而非独立,这一点必须要明确。实际上这是一个强假设,大多情况下问题不满足该假设却表现良好,这也算贝叶斯理论的一个特色吧。
2.算法计算了样本类别的先验分布,因此训练集正负样本数量需要符合其先验分布,这一点与GDA是类似。更进一步,所有的生成学习算法都要计算先验概率,故而对训练样本都有类似的要求。
标签:
原文地址:http://www.cnblogs.com/jcchen1987/p/4444462.html
