标签:

Size visibleSize = Director::getInstance()->getVisibleSize(); Sprite *sp = Sprite::create("HelloWorld.png"); sp->setPosition(Point(visibleSize.width * .5, visibleSize.height * .5)); this->addChild(sp, 1);
void Sprite::setTextureRect(const Rect& rect, bool rotated, const Size& untrimmedSize)
1. _quad
V3F_C4B_T2F_Quad _quad;
//! 4 Vertex3FTex2FColor4B struct CC_DLL V3F_C4B_T2F_Quad { //! top left V3F_C4B_T2F tl; //! bottom left V3F_C4B_T2F bl; //! top right V3F_C4B_T2F tr; //! bottom right V3F_C4B_T2F br; }; //! a Vec2 with a vertex point, a tex coord point and a color 4B struct CC_DLL V3F_C4B_T2F { //! vertices (3F) Vec3 vertices; // 12 bytes //! colors (4B) Color4B colors; // 4 bytes // tex coords (2F) Tex2F texCoords; // 8 bytes };
_quad.bl.texCoords.u = left; _quad.bl.texCoords.v = bottom; _quad.br.texCoords.u = right; _quad.br.texCoords.v = bottom; _quad.tl.texCoords.u = left; _quad.tl.texCoords.v = top; _quad.tr.texCoords.u = right; _quad.tr.texCoords.v = top;
// Atlas: Vertex float x1 = 0 + _offsetPosition.x; float y1 = 0 + _offsetPosition.y; float x2 = x1 + _rect.size.width; float y2 = y1 + _rect.size.height; // Don‘t update Z. _quad.bl.vertices = Vec3(x1, y1, 0); _quad.br.vertices = Vec3(x2, y1, 0); _quad.tl.vertices = Vec3(x1, y2, 0); _quad.tr.vertices = Vec3(x2, y2, 0);
void Sprite::draw(Renderer *renderer, const Mat4 &transform, uint32_t flags) { // Don‘t do calculate the culling if the transform was not updated _insideBounds = (flags & FLAGS_TRANSFORM_DIRTY) ? renderer->checkVisibility(transform, _contentSize) : _insideBounds; if(_insideBounds) { _quadCommand.init(_globalZOrder, _texture->getName(), getGLProgramState(), _blendFunc, &_quad, 1, transform); renderer->addCommand(&_quadCommand); }
TRIANGLES_COMMAND
QUAD_COMMAND
GROUP_COMMAND
CUSTOM_COMMAND
BATCH_COMMAND
PRIMITIVE_COMMAND
MESH_COMMAND
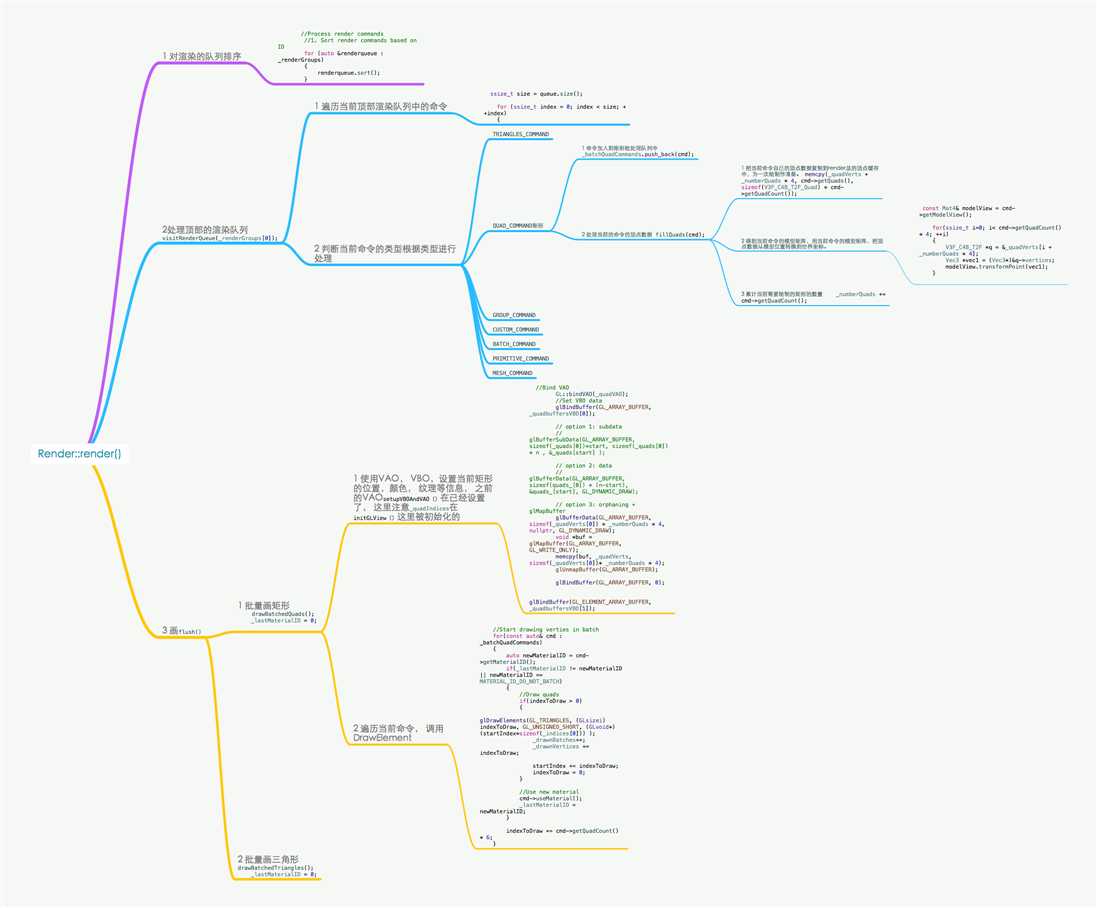
else if ( RenderCommand::Type::QUAD_COMMAND == commandType ) { flush3D(); if(_filledIndex > 0) { drawBatchedTriangles(); _lastMaterialID = 0; } auto cmd = static_cast<QuadCommand*>(command); //Batch quads if( (_numberQuads + cmd->getQuadCount()) * 4 > VBO_SIZE ) { CCASSERT(cmd->getQuadCount()>= 0 && cmd->getQuadCount() * 4 < VBO_SIZE, "VBO for vertex is not big enough, please break the data down or use customized render command"); //Draw batched quads if VBO is full drawBatchedQuads(); } _batchQuadCommands.push_back(cmd); fillQuads(cmd); }
void Renderer::fillQuads(const QuadCommand *cmd) { memcpy(_quadVerts + _numberQuads * 4, cmd->getQuads(), sizeof(V3F_C4B_T2F_Quad) * cmd->getQuadCount()); const Mat4& modelView = cmd->getModelView(); for(ssize_t i=0; i< cmd->getQuadCount() * 4; ++i) { V3F_C4B_T2F *q = &_quadVerts[i + _numberQuads * 4]; Vec3 *vec1 = (Vec3*)&q->vertices; modelView.transformPoint(vec1); } _numberQuads += cmd->getQuadCount(); }
memcpy(_quadVerts + _numberQuads * 4, cmd->getQuads(), sizeof(V3F_C4B_T2F_Quad) * cmd->getQuadCount());
for(ssize_t i=0; i< cmd->getQuadCount() * 4; ++i) { V3F_C4B_T2F *q = &_quadVerts[i + _numberQuads * 4]; Vec3 *vec1 = (Vec3*)&q->vertices; modelView.transformPoint(vec1); }
_numberQuads += cmd->getQuadCount();
GL::bindVAO(_quadVAO);
//Set VBO data glBindBuffer(GL_ARRAY_BUFFER, _quadbuffersVBO[0]); // option 3: orphaning + glMapBuffer glBufferData(GL_ARRAY_BUFFER, sizeof(_quadVerts[0]) * _numberQuads * 4, nullptr, GL_DYNAMIC_DRAW); void *buf = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY); memcpy(buf, _quadVerts, sizeof(_quadVerts[0])* _numberQuads * 4); glUnmapBuffer(GL_ARRAY_BUFFER);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, _quadbuffersVBO[1]);
for(const auto& cmd : _batchQuadCommands)
glDrawElements(GL_TRIANGLES, (GLsizei) indexToDraw, GL_UNSIGNED_SHORT, (GLvoid*) (startIndex*sizeof(_indices[0])) );
void Renderer::drawBatchedQuads() { //TODO: we can improve the draw performance by insert material switching command before hand. int indexToDraw = 0; int startIndex = 0; //Upload buffer to VBO if(_numberQuads <= 0 || _batchQuadCommands.empty()) { return; } if (Configuration::getInstance()->supportsShareableVAO()) { //Bind VAO GL::bindVAO(_quadVAO); //Set VBO data glBindBuffer(GL_ARRAY_BUFFER, _quadbuffersVBO[0]); // option 3: orphaning + glMapBuffer glBufferData(GL_ARRAY_BUFFER, sizeof(_quadVerts[0]) * _numberQuads * 4, nullptr, GL_DYNAMIC_DRAW); void *buf = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY); memcpy(buf, _quadVerts, sizeof(_quadVerts[0])* _numberQuads * 4); glUnmapBuffer(GL_ARRAY_BUFFER); glBindBuffer(GL_ARRAY_BUFFER, 0); glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, _quadbuffersVBO[1]); } else { } //Start drawing verties in batch for(const auto& cmd : _batchQuadCommands) { auto newMaterialID = cmd->getMaterialID(); if(_lastMaterialID != newMaterialID || newMaterialID == MATERIAL_ID_DO_NOT_BATCH) { //Draw quads if(indexToDraw > 0) { glDrawElements(GL_TRIANGLES, (GLsizei) indexToDraw, GL_UNSIGNED_SHORT, (GLvoid*) (startIndex*sizeof(_indices[0])) ); _drawnBatches++; _drawnVertices += indexToDraw; startIndex += indexToDraw; indexToDraw = 0; } //Use new material cmd->useMaterial(); _lastMaterialID = newMaterialID; } indexToDraw += cmd->getQuadCount() * 6; } //Draw any remaining quad if(indexToDraw > 0) { glDrawElements(GL_TRIANGLES, (GLsizei) indexToDraw, GL_UNSIGNED_SHORT, (GLvoid*) (startIndex*sizeof(_indices[0])) ); _drawnBatches++; _drawnVertices += indexToDraw; } if (Configuration::getInstance()->supportsShareableVAO()) { //Unbind VAO GL::bindVAO(0); } else { glBindBuffer(GL_ARRAY_BUFFER, 0); glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, 0); } _batchQuadCommands.clear(); _numberQuads = 0; }
标签:
原文地址:http://www.cnblogs.com/liangzhimy/p/4448126.html