标签:
主要是先看MapReduce模型有什么问题?
第一:需要写很多底层的代码不够高效,第二:所有的事情必须要转化成两个操作Map/Reduce,这本身就很奇怪,也不能解决所有的情况。
其实Spark出现就是为了解决上面的问题。介绍一些Spark的起源。发自 2010年Berkeley AMPLab,发表在hotCloud 是一个从学术界到工业界的成功典范,也吸引了顶级VC:Andreessen Horowitz的 注资 AMPLab这个实验室非常厉害,做大数据,云计算,跟工业界结合很紧密,之前就是他们做Mesos,Hadoop online, 在2013年,这些大牛(MIT最年轻的助理教授)从Berkeley AMPLab出去成立了Databricks。它是用函数式语言Scala编写,Spark简单说就是内存计算(包含迭代式计算,DAG计算,流式计算 )框架,之前MapReduce因效率低下大家经常嘲笑,而Spark的出现让大家很清新。 Reynod 作为Spark核心开发者, 介绍Spark性能超Hadoop百倍,算法实现仅有其1/10或1/100。
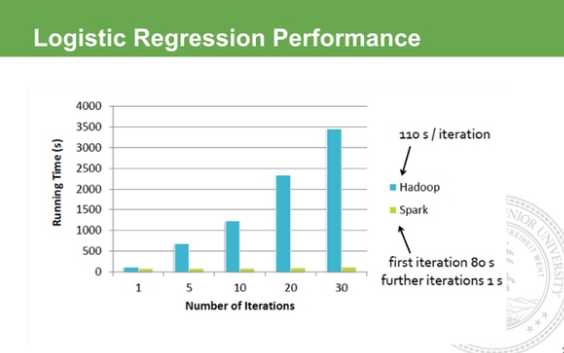
为啥用Spark,最直接的就是快啊,你用Hadoop跑大规模数据几个小时跑完,这边才几十秒,这种变化不仅是数量级的,并且是对你的开发方式翻天覆地的变化,比如你想验证一个算法,你也不知道到底效果如何,但如果能在秒级就给你反馈,你可以立马去调节。其他的如比MapReduce灵活啊,支持迭代的算法,ad-hoc query, 不需要你费很多力气花在软件的搭建上。在去年的Sorting Benchmark上,Spark用了比Hadoop更少的节点在23min跑完了100TB的排序,刷新了之前Hadoop保持的世界纪录。下图是跟Hadoop跟Spark在回归算法上比较,在Hadoop的世界里,做迭代计算是非常耗资源,它每次的IO 序列画代价很大,所以每次迭代需要差不多的等待。而Spark第一次启动需要载入到内存,之后迭代直接在内存利用中间结果做不落地的运算,所以后期的迭代速度快到可以忽略不计。
标签:
原文地址:http://www.cnblogs.com/mlj5288/p/4449086.html