标签:
现在做网络爬虫很容易,最常使用到的应该莫过于Python,类库丰富开发方便,简单。当然还有其他的,我没有接触的东西也很多,今天就说一下我两年前接触的一个项目中的很小一部分——模仿浏览器访问网站,大名网络机器人。
其实前一段时间看过一篇文章《在浏览器中输入网址后都发生了什么》,这是一篇很好的文章,过程说的很清楚明白,网络爬虫其实就是最大限度的模仿了浏览器访问web服务器的过程,下面的图能说明简单的过程:
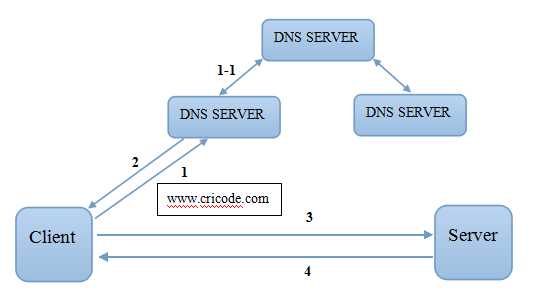
但还是不完整,下面将详细描述一个Http请求的过程:
根据域名获得IP地址的方法很多,你有可能返回的是很多IP地址,建议缓存起来,这有可能是存在一个一对多的关系。
获得了IP地址之后发起TCP连接,建议在这个过程中使用不同的IP地址访问,因为大量访问同一个可能产生服务器内部错误5XX等异常。温馨提示Http的默认端口是80,https的默认端口是443。完成连接的过程只是TCP的三次握手。
发送Http请求就是拼接的报文发送给web服务器,但是拼接报文涉及的东西很复杂,例如:
"GET %s HTTP/1.1\r\n"
"Host: %s\r\n"
"Connection: keep-alive\r\n"
"Cache-Control: max-age=0\r\n"
"Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*\r\n"
"User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:20.0)Gecko/20100101 Firefox/20.0\r\n"
"Accept-Encoding: gzip,deflate\r\n"
"Accept-Language: zh-CN,zh\r\n"
"Accept-Charset: GBK,utf-8\r\n"
"Referer: http://%s/\r\n\r\n"
这些"GET %s HTTP/1.1\r\n"的含义:GET方式的请求,%s代表网页的绝对路径,HTTP/1.1说明的是Http协议的版本号。
"Host: %s\r\n"的含义:主机名称。
"Connection: keep-alive\r\n"建立连接之后的连接方式
"Cache-Control: max-age=0\r\n"的含义:缓存控制的最长时间
"Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*\r\n"的含义:接受的文本类型
"User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:20.0)Gecko/20100101 Firefox/20.0\r\n"的含义:浏览器的类型,操作系统,等
"Accept-Encoding: gzip,deflate\r\n"的含义:浏览器接受的加密方式
"Accept-Language: zh-CN,zh\r\n"的含义:浏览器接受的语言
"Accept-Charset: GBK,utf-8\r\n"的含义:编码格式
"Referer: http://%s/\r\n\r\n"的含义:从哪个页面跳转过来
如果是模拟登录应该会涉及cookie的保存和发送的处理,关于cookie放在下一篇中讨论。
终于到了web服务器响应的过程了,这的很不容易的,先返回的是响应的状态码、cookie、传输方式、加密方式等信息,这是报文的头部。
需要首先解析响应报文才能知道后续的流程要如何处理,根据状态码判断应答是否正确,根据传输方式判断内容的接收方式,根据加密方式判断接收后的报文是否需要解密等等。状态码常见的有200、3XX、4XX、5XX。含义各不相同。200代表正常、3XX代表跳转、4XX代表不存在、5XX代表服务器内部错误。传输方式分为chunked和一般,处理方式不同。加密方式:gzip是一种公用的格式。
当爬虫正确的拿到报文之后,通信完成,关闭连接,通过TCP的四次挥手完成。之后需要筛选URL和内容,将URL保存以便访问,将内容按需要处理。这两种仅涉及字符串的处理,方式很多没必要仔细的说明。
标签:
原文地址:http://www.cnblogs.com/stlong/p/4449109.html