标签:
Spark is what:
Spache Spark is an open source clustercomputing system that aims to make dataanalytics fast — both fast to run and fast towrite
BDAS:
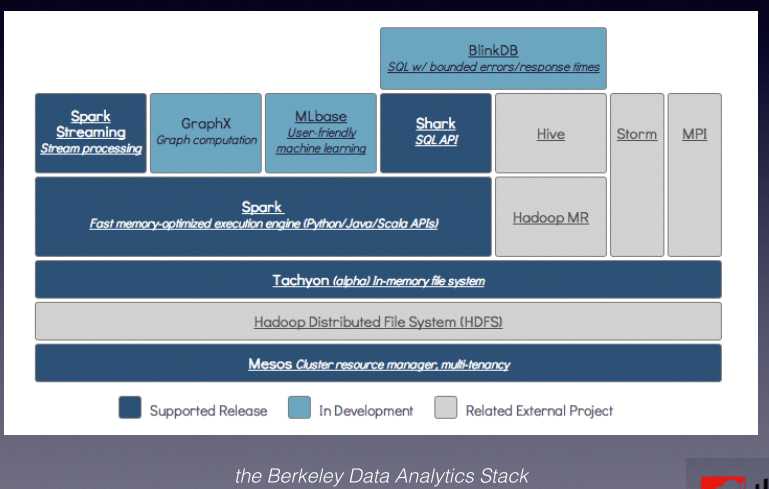
mesos:类似于yarn
hdfs:分布式文件系统
tochyon:同时也支持mapreduce,在hadoop2.3.0中,datanode也开始支持cache,这是一个非常重要的改进
shark:相当于Hive on spark
blinkdb:用于在海量数据上运行交互式查询的sql查询的大规模并行查询引擎,允许用户权衡数据精度来提升查询响应的时间
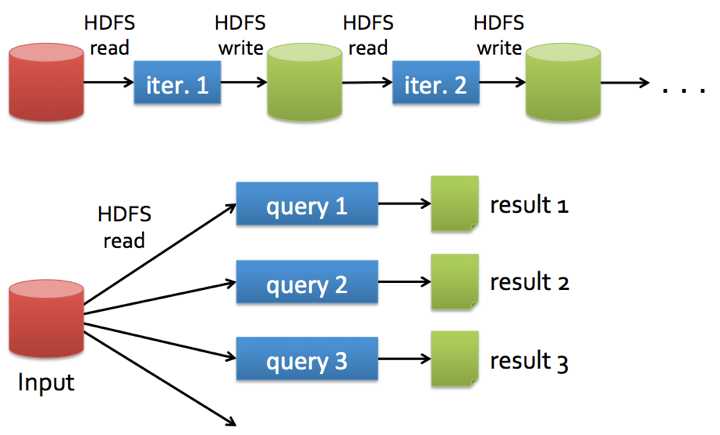
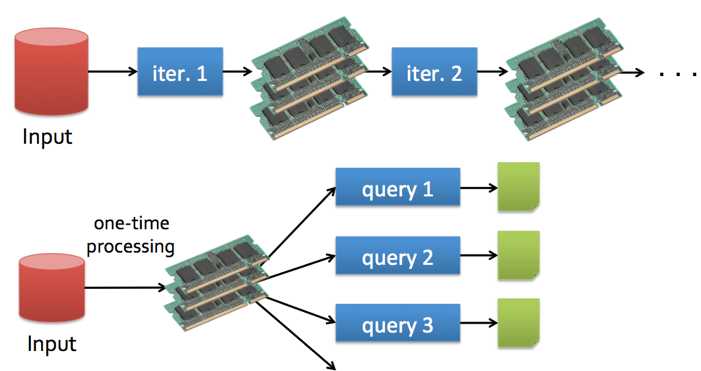 Spark的快是因为内存计算和DAG,很多优化措施其实是想通的,譬如说delay scheduling.
Spark的快是因为内存计算和DAG,很多优化措施其实是想通的,譬如说delay scheduling.
通过哪些模式运?行Spark呢?有4种模式可以运行
• local(多用于测试)
• Standalone
• Mesos
• YARN
其实Spark一切都以RDD(Resilient Distributed Dataset)为基础
特点:
1.A list of partitions(分片)
2.A function for computing each split(每个分片上都有函数去迭代)
3.A list of dependencies on other RDDs(RDD之间会有一系列依赖)
4.Optionally, a Partitioner for key-value RDDs (e.g. to say that theRDD is hash-partitioned)(可以指定partitioner)
5.Optionally, a list of preferred locations to compute each split on(e.g. block locations for an HDFS file)(可以指定优先节点)
Spark runtime
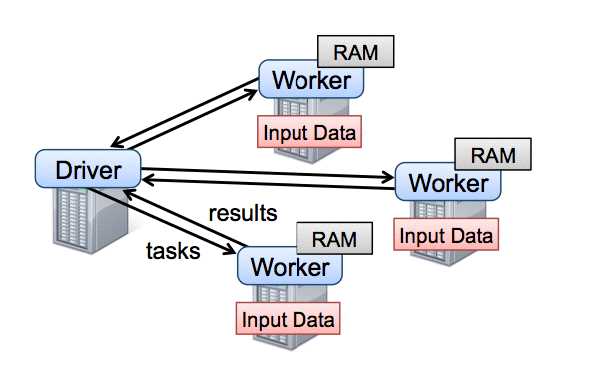
Spark流程示意图:RDD可以从集合直接转换?而来,也可以由从现存的任何Hadoop
InputFormat?而来,亦或者HBase等等。
 first demo!
first demo!
lines = sc.textFile(“hdfs://...”)
errors = lines.filter(_.startsWith(“ERROR”)) //transformation,并不立即执行
errors.persist() //缓存rdd 不立即执行
Mysql_errors = errors.filter(_.contains(“MySQL”)).count //action开始执行
http_errors = errors.filter(_.contains(“Http”)).count //action开始执行
缓存策略
class StorageLevel private(
private var useDisk_ : Boolean,
private var useMemory_ : Boolean,
private var deserialized_ : Boolean,
private var replication_ : Int = 1)
val NONE = new StorageLevel(false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, true)//默认缓存策略
//默认是反序列化存在的,序列化存在的时候,由于需要序列化,CPU消耗会多一些,在内存比较紧张的时候,最好使用反序列化的形式,这样可以减少内存消耗,spark支持除jdk序列化方式以外的其他序列化
val MEMORY_ONLY_2 = new StorageLevel(false, true, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, 2)
transformation & action

map:对每个元素经过函数转换后的所有值得到一个新的分布式数据集
filter:经过函数计算后,返回值为true的那些值,...
flatMap:先压扁再map
sample:生成样本子集
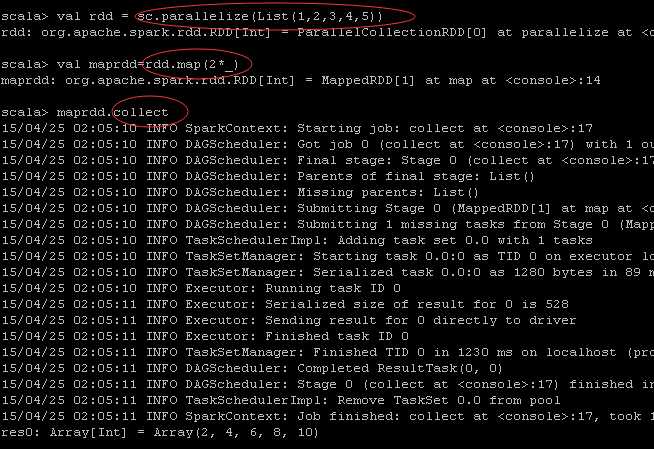
首先调用sc的paralize方法将一个集合转换成rdd,并未执行;
其次对rdd中每个元素执行*2操作,并未执行;
最后collect action触发上述操作执行

实际上上述步骤可以一步执行:
sc.parallelize(List(1,2,3,4,5)).map(2*_).filter(_>5).collect
rdd.count
rdd.cache//rdd放在内存,对比前后两个count的时间会发现不同
rdd.count
-----------------------------
wordcount on spark(结果未排序):
val rdd=sc.textFile(hdfs://..)
val wordcount=rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wordcount.collect
wordcount.saveAsTextFile("路径")
-----------------------------------
val rdd1=sc.parallelize(List((‘a‘,1),(‘a‘,2)))
val rdd2=sc.parallelize(List((‘b‘,1),(‘b‘,2)))
val res=rdd1 union rdd2
res.collect
---------------------------------------
val rdd1=sc.parallelize(List((‘a‘,1),(‘a‘,2),(‘b‘,3),(‘b‘,4)))
val rdd2=sc.parallelize(List((‘a‘,5),(‘a‘,6),(‘b‘,7),(‘b‘,8)))
val res=rdd1 join rdd2//笛卡尔积
res.collect
---------------------------------------
val rdd=sc.parallelize(List(1,2,3,4,5))
rdd.reduce(_+_)//直接对rdd中元素进行制定操作,而且立即执行
--------------------------------------
val rdd1=sc.parallelize(List((‘a‘,1),(‘a‘,2),(‘b‘,3),(‘b‘,4)))
rdd1.lookup(‘a‘)//将Key为a的value放在数组中呈现出来,立即执行
--------------------------------------------------------
wordcount on spark(结果排序):
val wordcount=sc.textFile(hdfs://..).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).saveAsTextFile("路径")
---------------------------------------
LineAge容错

每一个都看做RDD,每个RDD都会记录自己依赖于哪个(哪些)RDD,万一某个RDD的某些partition挂了,可以通过其它RDD并行计算迅速恢复出来。但是假如每次都快到进化完的时候就挂了,那岂不是每次都要从头进化?何不在中间制作个拷贝呢?!
-----------------------------
依赖
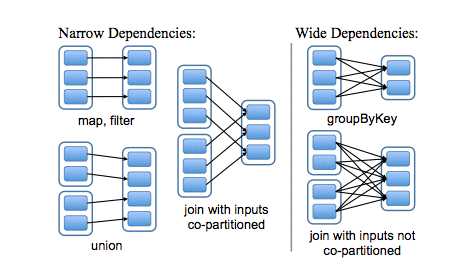 上图中的空心举行表示的是rdd,实心小矩形指的是partition,若干个partition组成了rdd.
上图中的空心举行表示的是rdd,实心小矩形指的是partition,若干个partition组成了rdd.
在窄依赖中,父rdd的每个partition至多被子rdd的一个partition使用;(map,filter,copartition导致窄依赖)
在宽依赖中,父rdd的每个partition可以被子rdd的多个partition使用;(join导致宽依赖)
---------------------------
集群配置:
spark-env.sh
export JAVA_HOME=
export SPARK_MASTER_IP=
export SPARK_WORKER_CORES=//几个cpu
export SPARK_WORKER_INSTANCES=1//几个实例,常用默认值1
export SPARK_WORKER_MEMORY=//分配内存
export SPARK_MASTER_PORT=8080//端口
export SPARK_JAVA_OPTS="-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps”
slaves
xx.xx.xx.2
xx.xx.xx.3
--------------------------------------
分析搜狗实验室提供的用户访问日志
1.加载 val rdd=sc.
2.统计时间小于某个时间点的访问数:rdd.map(_.split(‘\t‘)(0)).filter(_<"20111010000000").count//map将函数处理后的信息返回,这里返回第一列
3.统计有多少搜索链接是排名第一位的
rdd.map(_split(‘\t‘)(3)).filter(_.toInt==1).count
4.统计有多少排名第一的搜索链接是第一次就被搜索到的
rdd.map(_.split(‘\t‘)).filter(_(0).toInt==1).filter(_(1).toInt==1).count
标签:
原文地址:http://www.cnblogs.com/mlj5288/p/4456023.html