标签:
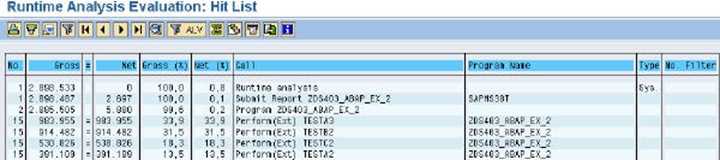
The hit list summarizes the measurements of execution and processing times into one entry per operation. If the aggregation is ‘per calling position‘, then you will see two separate entries for the same operation if the operation is called from two different programs or if the operation is called from two different positions in the same program. The unique keys fields of the hit list are therefore ‘Call‘, i.e. operation (col. 7), ‘Program Name‘ (col.8) and ‘Line‘, i.e. calling position. Unfortunately, the line is not displayed in the default layout of the hit list and can be added by layout change.
The important measured values are ‘No.‘ (col. 1), ‘Gross‘ (col. 2), and ‘Net‘ (col. 4). They tell you how often an operation was executed, and how much time it required, either as a total including sub-operations (Gross time), or without sub-operations (Net time). Remember that the times are measured in microseconds (ms) and that the shown times are the total times, not the times per execution.
The other columns contain additional, although less important information. These are the equality sign ‘=‘ (col. 3), the percentages ‘Gross (%)‘ (col. 5) and ‘Net (%)‘ (col. 6), and also the ‘Type‘ (col. 9) and the ‘No. Filter‘ (col. 10).
? ?
From <http://lianxiangpanjin.blog.sohu.com/132793680.html>
? ?
? ?
select中连接查询相关
2014年4月6日
22:58
? ?
一般情况
尽量控制连接的表的数量(据说控制在三张以内)
个人估计性能问题主要是在
大数据量的多表查询上,或者包含大数据量的表(最坏情况下,查询时间就是倍数增长)
所以对于有些大数据量的表涉及多表查询
分成多个查询 查询结果放在多个内表之间
然后组合或者过滤这些内容
(这个过程中注意for all entries in 使用时导致的重复数据丢失的问题)
注意多表查询时,非关键字段作为连接条件,该条件出现在where语句中
可能导致查询速度的下降
典型的案例:
自己开发的zs066 一个date相关的range变量 只有low值时没问题
low 和 high都有值时, 查询时间异常
个人估计使用range变量时,low和high都有值
?在数据库层面上 没有使用索引
查询顺序的问题:
并不是简单的个人认为的按表依次查询
上次看到一老外的文章说
有一个优化器
根据where条件会计算查询表的顺序
这个问题也就能很好的说明z_rfc_0014中加了销单条件的查询速度了
The database optimizer first determines the order in which?the tables in the join?are to be accessed. To do this, it?uses the WHERE clause?to estimate the number of returned table records or data blocks for each table in the join.
? ?
To determine which table will be the?outer table, the optimizer determines the table with the?lowest number of returned table records or data blocks, because it assumes that in total the fewest data blocks need to be read in this table.
? ?
Therefore, the goal once more is to minimize the number of data blocks to be read (index blocks or table blocks). If there are more than two tables in the join,?the inner table is selected in the same way.(超过两张表也是这么选的)
? ?
In the second step, the table records from the?outer table are first selected. For these table records, the table records from?the next innermost table?are read according to the join condition, and so on.
? ?
For the SQL statement above, the optimizer selects the table VVBAK as the outer table, because a selective WHERE condition exists for the field VVBAK-OBJNR. For each table record that fulfills the WHERE condition, table records from VVBUK are selected according to the join condition.?
简单的翻译一下:(应该是针对inner join的选择顺序 ?left join肯定最后操作才有意义)
主要阐述join的查询顺序
大概就是
根据where条件
选择记录最少的表进入
(optimizer有自己的estimate的算法:这只是一个评估,并不是具体值)
剩余的就按照join的顺序随便抓了
第一张join表的选择有点类似木桶效应的意思 ?选择的基数降到最低
range变量在select条件中需要注意
它本身是一个内表
对于它的一条记录就是一个筛选条件
尤其要关注high和low不为空的条件?
对于数值类型很好理解?但是在处理字符串时 尤其要当心
需要考虑过滤掉可能得到的非目标结果
有个取数逻辑需要关注
某条内表记录作为筛选条件 ?+ 附加条件 ?in ()
if sy-subrc = 0.
? ? ?delete."在某个范围内 删除
else.
? ? 筛选条件 + not in () "不在某个范围内
? ? ?if ?sy-subrc = 0.
? ? ?else.
? ? ? ? ? delete."不存在该条记录
? ? ?endif.
endif.
不能简单的认为 ?in () 结果为false 就认为该记录一定是可选的 还要判断该条记录是在表中
上面说的很模糊:
等效的一个判断就是
a先判断是否在某张表中
b再考虑某个字段是否满足条件
先a后b理解比较简单 ? 先b后a要当心
? ?
虽然说sap的数据库接口 或者说底层数据库自身有一个查询策略
但是这个策略只是针对大多数状况不出问题
部分状况还是要自己来控制的
这时候就不能依靠连接查询了
用程序逻辑控制查询的表的顺序
Exp:
ZC044的优化
原来是使用连接查询
其中mkpf 连接 mseg
虽然有一个budat的查询时间
但是更多的条件都在mseg中 ?可能查询策略是从mseg中取数 事实上这些条件并没有索引
反而根据时间从mkpf中更快
所以这里是采用分开来处理的
另外,for all entries in <itab> 如果表是mseg itab数量级很大的话 查询速度也有点慢
但是也是在能接受的范围内 ?如果可以的话尽量一次独处数据 在内表(内存中)二次筛选
避免多次从该表取数
? ?
? ?
查询条件不要作为连接中的字段
2014年4月6日
23:01
? ?
会导致查询时间暴增
尤其是关联本身数据量就很大的表
例如:
bkpf和vbrk关联的时候
涉及bkpf~budat ?= vbrk~fkdat
而fkdat在一个select-option范围内
当fkdat指定low和high后整个查询变得异常慢
原因不知
-----------------------------------
按理来说应该没有问题才对
进入bkpf时只有一个date
可能底层的实现没这么简单
总而言之
注意连接查询的关联条件
涉及到非关键字时都要小心
非关键字段还在条件中 ?此时需要考虑在loop中装填而不是连查
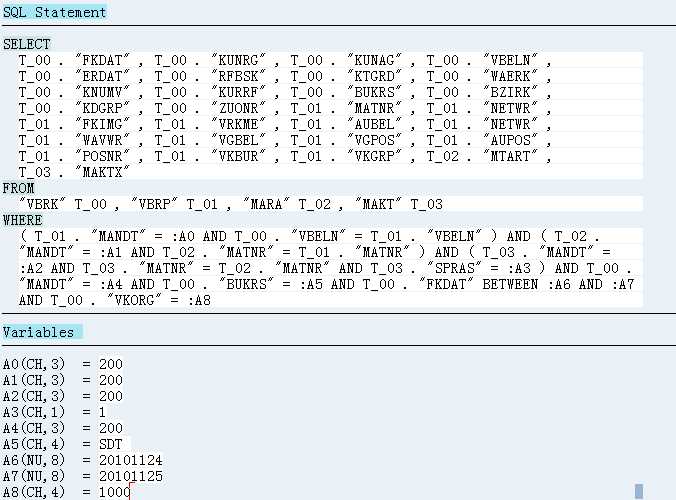
以上是改进后的查询结果
从sql语句上看一个常见的多表查询
后一张表的查询必须等待前一张表的查询
再看有问题的查询 关键在这个时间的处理
时间条件 t_00."FKDAT" between :time1 and time2
t_02.budat = t01.fkdat
作为sql的解释器来说
t_02.budat 的时间也在 time1~time2
这是就可以启动两个线程?
分别处理t_00 和 t_02?
然后合并
(这是个人假想的一个过程)
由于t_02时间between and 得到的数据量太大 时间太长
反而使得这个查询变慢?
解释器的这个设定是没有问题的额
正常外键关联主键
主键默认索引了
而这个问题在用正常的链接查询的时候是看不来的
总结:
连接条件尽量使用关键字段(或者被索引的字段)
条件字段出现在连接字段中
必须关注是否是被索引的
标签:
原文地址:http://www.cnblogs.com/rootbin/p/4463492.html