标签:
? ?
引言
? ?
随机森林在机器学习实战中没有讲到,我是从伯克利大学的一个叫breiman的主页中看到相关的资料,这个breiman好像是随机森林算法的提出者,网址如下
? ?
http://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
? ?
随机森林算法简介
? ?
随机森林说白了就是很多个决策树组成在一起,就形成了森林,关键在于如何创建森林里的每一棵树,随机森林用到的方法bootstrap法,通俗的讲就是有放回的抽取样本
? ?
这里有个理论依据在这,说明有放回的抽取方法大概有三分之一的样本不会被抽取到,在此我简单说一下这个原因
? ?
三分之一的样本不会被抽取到的原因
? ?
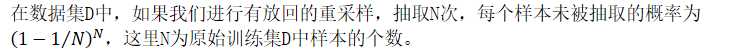
? ?
当N足够大时, 将收敛于1/e≈0.368,这表明原始样本集D中接近37%的样本不会出现在bootstrap样本中,这些数据称为袋外(Out-Of-Bag,OOB)数据,使用这些数据来估计模型的性能称为OOB估计
? ?
构建决策树
? ?
除了随机抽取样本外,构建一个决策树还需要随机抽取样本的特征,比如样本总共有100维特征,我们随机抽取其中的10维特征构建决策树
? ?
如果我们想构建200棵决策树的随机森林,我们就要这样随机抽取200次,每次抽取10维特征构建一个决策树
? ?
而用于构建决策树的样本也需要用之前说的那种bootstrap法有放回的随机抽取,简单说一下用于构建一个决策树的样本集生成的过程
? ?
bootstrap法抽取样本过程
? ?
随机抽取1个样本,然后让回,然后再随机抽取1个样本,这样抽取N次,可以得到N个样本的数据集,用这N个样本的数据集,按照之前随机选取的10维特征,遍历这10维特征,对数据集进行划分,得到一棵决策树
? ?
如果要构建200棵树,就需要随机抽取200次10维特征,随机抽取200次N个样本集
? ?
随机森林分类
? ?
得到了200棵树的随机森林如何用作分类呢,随机森林中用的OOB数据测试随机森林的分类结果,之前说到bootstrap方法会造成大概三分之一的数据不会被采样的,这部分数据就被称之为OOB数据,将这部分数据放入森林中,每一棵树会对相应的数据得到一个分类结果,那么最后的结果会根据投票来确定
? ?
为什么不用交叉验证的方法二用OOB的方法
? ?
有一个问题就是这种OOB的方法跟交叉验证中随机抽取样本有什么区别,比如十折交叉验证中就是把数据集平均分为10份儿,随机选取其中的9份儿用作训练,1份儿用作测试,重复十次,取平均值,那么OOB这种有放回的重采样,和交叉验证有什么区别呢
? ?
一个很重要的区别根据作者的说法在于计算量,用交叉验证(CV)估计组合分类器的泛化误差时,可能导致很大的计算量,从而降低算法的运行效率,而采用OOB数据估计组合分类器的泛化误差时,可以在构建各决策树的同时计算出OOB误
差率,最终只需增加少量的计算就可以得到。相对于交叉验证,00B估计是高效的,且其结果近似于交叉验证的结果
? ?
标签:
原文地址:http://www.cnblogs.com/keedor/p/4463927.html