标签:style blog code http tar com
ASCII 编码称为美国信息交换标准代码,使用一个字节来编码,最高位始终为0,所以总共可以表示128个字符,目前分配情况如下:
ASCII 编码最高位始终是0,只使用低七位进行编码,总共编码128个字符,如果将最高位用上,可以再编码128个字符。ASCII 编码是美国标准,所以欧洲有些符号并未包含其中,于是利用字节的最高位对 ASCII 编码进行扩展便产生了 ISO8859 编码。
ISO8859 编码并不是一个标准,其包含16个编码标准,每个标准中0x00-0x7F(即最高位是0)区段表示的字符与 ASCII 编码相同,0x80-0xFF(即最高位是1)区段表示的字符根据标准而异,基定义如下:
Unicode 也称为万国码,主要为了解决传统字符编码方案的局限性,它为每种语言中的每个字符分配统一并且唯一的编码,即定义一个整数来表示某字符。以解决跨平台信息交换的问题。
Unicode 并不定义字形,字符的展示工作留给其它软件来处理。目前最新版本为第六版,已经收录了超过十万个字符,至今还在不断增加,具体内容可参考 Unicode Roadmaps。
Unicode 定义了17个平面,目前用到的只有少数平面,每个平面有65536(即2^16)个代码点。第0平面叫基本多文种平面,其它16个平面称为辅助平面。一个 Unicode 字符至少要用21位来编码,略少于3字节。目前用到的平面如下:
最常用到的是基本多文种平面,占用两个字节,基本多文种平面的分区如下图所示:
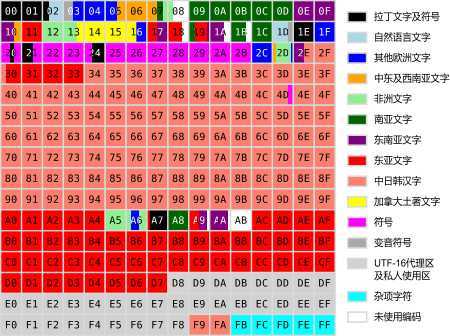
Unicode 编码系统分为编码方式和实现方式两个层次。编码方式规定某字符的编码是什么,即代表此字符的整数值是什么;实现方式规定此整数值应该如何存储。编码方式已经通过17个平面来解决,下面讨论实现方式。
基本多文种平面的字符要用两个字节来表示,辅助平面的字符都要用三个字节来表示。如果一个文件包含100个’N’和100个’七’,’N’的 Unicode 编码是0x004E,’七’的 Unicode 编码是0x4E25。这里就会遇到一个问题,如果用固定字节数来表示一个字符,那么会浪费很多存储空间,比如用4个字节来表示一个字符,此文件将占用800个字节,浪费掉500个字节;如果用变长字节数来表示一个字符,那么计算机不能区分某个字节是一个 ASCII 编码还是一个多字节编码的一部分,比如计算机读到文件中的4E就不能区分这代表’N’,还是代表’七’的高字节。
显然固定字节数来表示一个字符是不可取的,只能使用变长字节数,而 Unicode 的编码不能直接用来存储、交换,必须经过某种转换,UTF(Unicode 转换格式)就是为了解决此问题而诞生的,主要包括 UTF-8、UTF-16、UTF-32,最常用到的是 UTF-8 编码,它使用一至六个字节来为每个字符编码,其规则如下:
标签:style blog code http tar com
原文地址:http://www.cnblogs.com/kvmisc/p/3781133.html