标签:
前言
最近阅读了spark mllib(版本:spark 1.3)中Random Forest的实现,发现在分布式的数据结构上实现迭代算法时,有些地方与单机环境不一样。单机上一些直观的操作(递归),在分布式数据上,必须进行优化,否则I/O(网络,磁盘)会消耗大量时间。本文整理spark随机森林实现中的相关技巧,方便后面回顾。
?
随机森林算法概要
随机森林算法的详细实现和细节,可以参考论文Breiman 2001。这里简单说说大体思路,方便理解代码。
随机森林是一个组装(ensemble model)模型,内部的模型使用决策树。基本思想是生成很多很多决策树(构成森林),最后由这些决策数一起投票决定最终结果。生成树的过程中,从行和列两个方向添加随机过程。行方向,在构建每棵树前,使用有放回抽样(称为Bootstrapping),得到训练数据。列方向,每次选择切分点时,对feature进行无放回随机抽样,得到一个feature子集,在当前节点上,只使用这些子集对应的数据计算最优切分点。这也是为什么此算法称为随机森林,是不是很直观。相比于单一决策树,随机森林有以下一些优点:
当然,为了得到上面的优点,必须付出计算开销作为代价。在单机时代,使用随机森林(R或scikit-learn)往往成本很高,但是现在有了spark,使得大规模,分布式迭代计算成为了可能,所以在spark上运用随机森林是技术发展的必然结果!
?
Spark实现优化
spark在实现随机森林时,采用了下面几个优化策略:
使用这些策略,原因在于RDD的数据时分布在不同服务器上,为了避免过多的I/O,必须在原始算法上做出一些优化,否则执行时间可能难以接受。下面分别详细讨论这三个优化策略。
?
切分点抽样
此优化主要针对连续变量。先回忆一下一般的决策树是如何对连续变量进行切分点选择的。一般是先对feature进行排序,然后选取相邻两个数据之间的点作为切分点。如果在RDD上执行这个操作,不可避免会使用shuffle过程,此过程会带来大量的网络通讯。而且,一般RDD上的数据都很大,少则几百万,多则几亿到几十亿,甚至更多。在这样的数量级上进行排序操作,想想也是醉了。所以,为了避免排序操作,mllib通过抽样的方法,在样本上进行排序,并且根据样本,获取切分点。据spark团队反馈,使用此策略虽然牺牲了部分精度,但是在实际运用过程中,并没有带来过多的影响,模型效果可以接受。
?
feature装箱
根据抽样,得到切分点后,接下来是对feature进行装箱操作,箱子就是由相邻的样本切分点构成。箱子的个数是非常小的,一般实际中采用30个左右。计算每个箱子中不同种类的占比,可以很快计算出最优切分点。
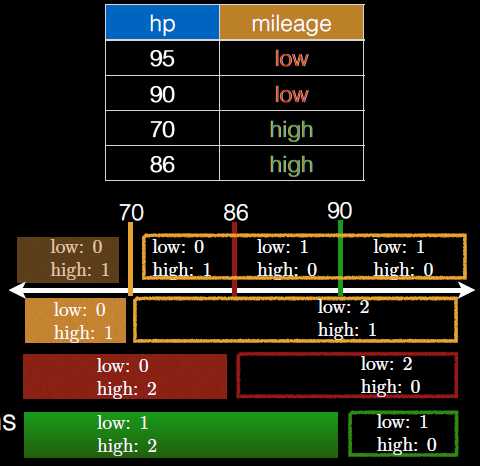
举个例子,参考上面的示例数据,第一行是每个切分点的比例统计。基于上面的数据,可能生成3中切分情况,分别有棕,红和绿色三行表示。如果需要计算棕色的切分情况,只需要按照第一行的组合方式,就可以很快的计算所出来。
?
分区统计
RDD分区中装箱数据单独统计后,可以通过reduce将每个分区的数据合并,得到总体的装箱数据(通过mapPartition实现分区统计)。正是由于装箱统计数据可以合并,所以可以很好的适应分布式数据环境,最后需要合并的数据也只是一些统计数据,不会带来很大的网络通讯开销。
?
逐层计算
单机版本的决策数生成过程是通过递归调用(本质上是深度优先)的方式构造树,在构造树的同事,需要移动数据,将同一个子节点的数据移动到一起。此方法在分布式数据结构上无法有效的执行,而且也无法执行,因为数据太大,无法放在一起,所以在分布式存储。mlib采用的策略是逐层构建树节点(本质上是广度优先),这样遍历所有数据的次数等于所有树的最大层数。每次遍历时,只需要计算每个节点所有feature的装箱统计参数,遍历完后,根据节点装箱统计量,决定是否切分,以及如何切分。
?
以上就是spark mllib实现的随机森林的关键技巧。当然还有很多实现细节这里没有描述,不过如果理解了这些技巧,对阅读spark mllib随机森林源代码会有很大帮助,希望对读者有用。
?
Spark RandomForest实现的不足
截止到spark 1.3,mllib的随机森林仍然不支持OOB error和variable importance的支持,也有一些网友在spark社区咨询此问题,但是目前没有得到官方的回应。希望后面,spark可以支持此特性。
?
参考资料
标签:
原文地址:http://www.cnblogs.com/bourneli/p/4473976.html