标签:
1. Linear Regression Model
The Least Square Method is derived from maximum likelihood under the assumption of a Gaussian noise distribution, and hence could give rise to the problem of over-fitting, which is a general property of MLE.
The Regularized Least Squares, which is the generalized form of LSM, stems from a naive Bayesian approach called maximum posterior estimate. Given a certain MAP model, we can deduce the following closed-form solution to the linear regression:
1 function w = linRegress(X,t,lamb)
2 % Closed-Form Solution of MAP Linear Regression
3 % Precondtion: X is a set of data columns,
4 % row vector t is the labels of X
5 % Postcondition: w is the linear model parameter
6 % such that y = w‘* x
7 if (nargin<3)
8 % MLE, no regularizer (penalty term)
9 lamb = 0;
10 end
11 m = size(X,1); % m-1 features, one constant term
12 w = (X*X‘+lamb*eye(m))\X*t‘;
13 end
However, batch techniques run on the entire training set can be computationally costly, so we need some effective on-line algorithms:
1 function w = linRegress(X,t,err)
2 % Batch Gradient Descent for Linear Regression
3 % by using the Newton-Raphson Method
4 % Precondtion: X is a set of data columns,
5 % row vector t is the labels of X
6 % Postcondition: w is the linear model parameter
7 % such that y = w‘* x
8 if (nargin<3)
9 err = 0.0001;
10 end
11 m = size(X,1);
12 w = zeros(m,1);
13 grad = calGrad(X,t,w);
14 while (norm(grad)>=err)
15 w = w-calHess(X)\grad;
16 grad = calGrad(X,t,w);
17 end
18 end
19
20 function grad = calGrad(X,t,w)
21 % Gradient of the Error Function
22 [m,n] = size(X);
23 grad = zeros(m,1);
24 for i = 1:n
25 grad = grad+(w‘*X(:,i)-t(i))*X(:,i);
26 end
27 end
28
29 function hess = calHess(X)
30 % Hessian Matrix of the Error Function
31 m = size(X,1);
32 hess = zeros(m);
33 for i = 1:m
34 for j = 1:m
35 hess(i,j) = X(i,:)*X(j,:)‘;
36 end
37 end
38 end
In frequentist viewpoint of Model Complexity, the expected square loss can be decomposed into a squared bias (the difference between the average prediction and the desired one), a variance term (sensitivity to data sets) and a constant noise term. A relatively rigid model (e.g. MAP with large lambda) has lower variance but higher bias compared with a flexible model (e.g. MLE), and this is the so-called bias-variance trade-off.
Bayesian model comparison would choose model averaging instead, which is also known as the fully Bayesian treatment. Given the prior distribution of models (hyper-parameters) p(Mi) and the marginal likelihood p(D|Mi) (a convolution of p(D|w,Mi) and p(w|Mi)), we can deduce the posterior distribution of models p(Mi|D). To make a prediction, we just marginalize with respect to both the parameters and hyper-parameters.
However, the computations in fully Bayesian treatment is usually intractable. To make an approximation, we can carry on model selection in light of the model posterior distribution (MAP estimate), and just marginalize over parameters. Here we take linear regression for example to illustrate how to implement such evidence approximation once having the optimal hyper-parameters.
First of all, given p(w) = Gauss(w|m0,S0), we can infer the posterior distribution of the parameters:
p(w|X,t) = Gauss(w|mN,SN), where mN=SN*(inv(S0)*m0+beta*X‘*t), inv(SN) = inv(S0)+beta*X‘*X .
Then we shall calculate the convolution of the likelihood of t and the posterior of w to get the predictive distribution:
p(t|x,X,t) = Gauss(t|mN‘*X,beta-1+X‘*SN*X).
We can easily find that the prediction value (the mean vector) is a linear combination of the training set target variables.
2. Logistic Regression Model
Classification by generative approach is somehow to maxmize the likelihood, the product of all p(xn,Ck)tnk, to get the prior class possibilities p(Ck) (usually Nk/N) and class-conditional distribution p(xn|Ck) (usually in the form of Gaussian or multinomial). An alternative is discriminative approach, in which we directly presume the form of class-conditional distribution (usually parametric softmax functions) and estimate the parameters by maximizing the likelihood.
For example, in 2-class Logistic Regression, we presume the form of p(C1|x) is y(x) = sigmoid(w‘*x+b), and by taking the negative logarithm of the likelihood we get cross-entropy error function:
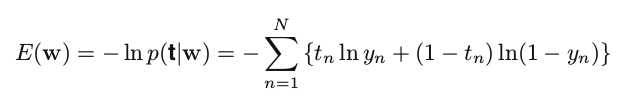
where tn indicates whether xn belongs to C1, and yn = p(C1|xn). To minimize it, we can use Newton-Raphson method to update the parameters iteratively:
w(new) = w(old) - inv(X‘*R*X)*X‘*(y-t)
1 function y = logRegress(X,t,x)
2 % Logistic Regression for 2-Class Classification
3 % Precondtion: X is a set of data columns for training,
4 % row vector t is the labels of X (+1 or -1)
5 % x is a data column for testing
6 % Postcondition: the predicted value of data x
7 m = size(X,1);
8 options = optimset(‘GradObj‘,‘on‘,‘MaxIter‘,1000);
9 w = fminunc(@logRegCost,rand(m,1),options);
10 function [val,grad] = logRegCost(w)
11 % Determine the value and the gradient
12 % of the error function
13 q = (t+1)/2;
14 p = 1./(1+exp(-w‘*X));
15 val = -q*log(p‘)-(1-q)*log(1-p‘);
16 grad = X*(p-q)‘/size(q,2);
17 end
18 y = 2*round(1./(1+exp(-w‘*x)))-1;
19 end
When it comes to Bayesian method, we should first know the technique of Laplace Approximation, which construct a Gaussian distribution to approximate a function with a global maximum point z0:
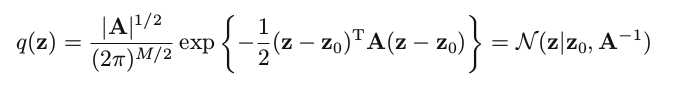
where A is the Hessian matrix of negative logarithm of f(z) at the point z0.
To tackle logistic regression in a Bayesian way, given a Gaussian prior p(w) = Gauss(w|m0,S0), we should first use the method above to approximate the posterior distribution p(w|X,t) as Gauss(wMAP,SN), and then approximate the predictive distribution (the convolution of p(C1|x,w) and p(w|X,t)) as σ(κ(σa2)μa), where
κ(σa2) = sqrt(1+πσa2/8)-1, σa = X‘*SN*X, μa = wMAP‘*X.
References:
1. Bishop, Christopher M. Pattern Recognition and Machine Learning [M]. Singapore: Springer, 2006
标签:
原文地址:http://www.cnblogs.com/DevinZ/p/4472476.html