标签:style blog http ext color com
协同过滤推荐新闻根据用户浏览点击的相似,在推荐新闻方面主要有两个缺点:
1 first-rater problem 不能给用户推荐别的用户还没有阅读过的新闻,新的新闻是随着时间不断增加的,CF需要数个小时来收集用户的click
2 并不是所有用户都是对等的,没有考虑单个用户的兴趣差异性,例如娱乐新闻大多数人都喜欢,即使一个没有怎么点击娱乐新闻,但是他的邻居可能点击的很多,这样就给用户推荐的娱乐新闻比较多。
一个解决方案: 建立用户的profile,根据用户的profile过滤文章,即使新的新闻没有点击太多,也能被推荐。
系统的两个实践局限:1用户兴趣随时间变化 2 用户点击数量差异很大,如何对点击数量很少的用户也能很好的推荐
用户的兴趣分为长期兴趣和短时兴趣,短时兴趣可能是因为某些hot news的发生,长期兴趣才是用户的真正兴趣,
结合了CB和CF方法。用户点击有很大的噪音
1 对文本自动分类,建立用户对各个类别的喜好程度模型,然后对每个类别里面higher的文章推荐给用户。在一般topic水平来推荐而不是精确的tuning,因为用户是抱着show me sth interesting的态度来浏览网站,过度的对用户兴趣建模可能影响推荐效果。
2 点击分布: 文章先被分为一些预设好的类别(比如 娱乐,科技等)
对于每个用户u,计算用户在每个月 t 内的主题点击分布 D(u,t)
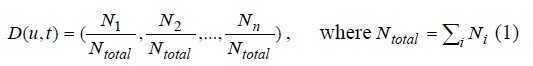
Ntotal表示这个月内 用户U的点击总量,Ni表示u对主题i的点击数量。 这是用户一个月的兴趣分布。
通过日志分析得到如下的结论:
用户兴趣随着时间变化
全局点击分布反应新闻趋势
不同地区新闻趋势不同
地区新闻趋势影响个人兴趣
用户兴趣:用户个人兴趣+当地的news trend
用户个人因素 :年龄,性别,点击新闻的分布,是长期兴趣
当地news trend ,比如一个火热话题,是短期兴趣
3 使用Bayesian frameworks对用户兴趣建模
用户对一个类别的兴趣度:
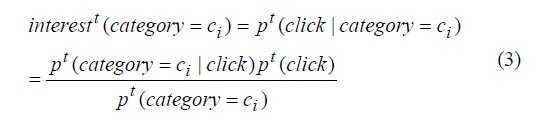
pt (category ci | click) 用户点击属于ci的概率,可以用 D(u,t)估计
pt (category = ci) 文章属于类别ci的概率,可以用当地的D(t)估计
pt (click) 用户点击任何一篇文章的概率,该项可以忽略
考虑更多的历史记录,合并一段时间的点击,得到如下式子

Nt,t时段用户点击的总次数。
假设Pt(click)不随着时间变化,上式可以写为:
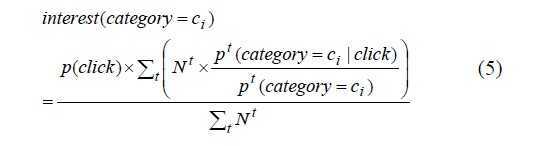
下面来计算news trend,用P0来表示
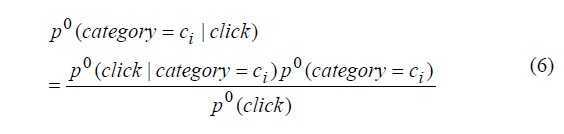
跟用户真正的兴趣合并:
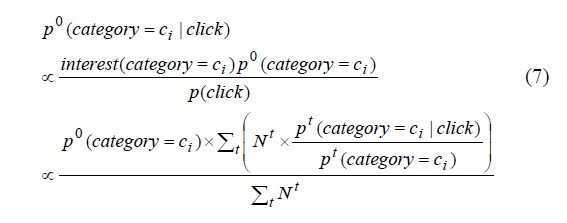
对用户点击加入平滑G(设置为10),最终的预测公式如下:
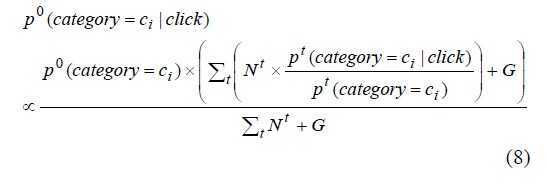
我的微博 http://weibo.com/mainmonkey
参考:
1 Personalized News Recommendation Based on Click Behavior
标签:style blog http ext color com
原文地址:http://www.cnblogs.com/mainmonkey/p/3781445.html