标签:
在sever端的run.xml中run和debug中加入如下参数:
<jvmarg value="-XX:+PrintGCDateStamps"/>
<jvmarg value="-XX:+PrintGCDetails"/>
<jvmarg value="-Xloggc:./gclogs"/>
启动server端后发现server文件夹下多了一个名为gclogs的文件。查看gclogs文件的内容如下:
2015-04-29T11:17:40.703+0800: 2.456: [Full GC (System) 2.456: [Tenured: 0K->3382K(174784K), 0.0546714 secs] 67363K->3382K(253440K), [Perm : 12488K->12488K(12544K)], 0.0547715 secs] [Times: user=0.06 sys=0.00, real=0.06 secs] 2015-04-29T11:17:48.671+0800: 10.422: [Full GC 10.422: [Tenured: 3382K->7703K(174784K), 0.0825413 secs] 53274K->7703K(253504K), [Perm : 16639K->16639K(16640K)], 0.0827269 secs] [Times: user=0.09 sys=0.00, real=0.09 secs] 2015-04-29T11:17:52.937+0800: 14.384: [Full GC 14.384: [Tenured: 7703K->8872K(174784K), 0.0812765 secs] 32672K->8872K(253568K), [Perm : 20735K->20735K(20736K)], 0.0813813 secs] [Times: user=0.08 sys=0.00, real=0.08 secs] 2015-04-29T11:19:53.656+0800: 130.211: [GC 130.211: [DefNew: 70080K->2097K(78784K), 0.0093047 secs] 78952K->10970K(253568K), 0.0095041 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] …..//全部都是GC 2015-04-29T12:17:53.015+0800: 3609.469: [Full GC (System) 3609.469: [Tenured: 10304K->9764K(174784K), 0.1250319 secs] 37316K->9764K(253568K), [Perm : 22686K->22551K(22784K)], 0.1251192 secs] [Times: user=0.13 sys=0.00, real=0.13 secs] 2015-04-29T12:21:14.390+0800: 3810.844: [GC 3810.844: [DefNew: 70208K->1096K(78912K), 0.0057242 secs] 79972K->10861K(253696K), 0.0058007 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] …//全部都是GC 2015-04-29T13:17:53.140+0800: 7209.486: [Full GC (System) 7209.486: [Tenured: 9766K->10453K(174784K), 0.0993441 secs] 56183K->10453K(253696K), [Perm : 22560K->22560K(22784K)], 0.0994195 secs] [Times: user=0.09 sys=0.00, real=0.09 secs] 2015-04-29T13:21:15.390+0800: 7411.729: [GC 7411.729: [DefNew: 70208K->1058K(78912K), 0.0049616 secs] 80661K->11512K(253696K), 0.0050321 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] …//全部都是GC 2015-04-29T14:17:53.234+0800: 10809.475: [Full GC (System) 10809.475: [Tenured: 10468K->11261K(174784K), 0.1007012 secs] 61961K->11261K(253696K), [Perm : 22569K->22569K(22784K)], 0.1007760 secs] [Times: user=0.11 sys=0.00, real=0.11 secs] 2015-04-29T14:21:13.671+0800: 11009.908: [GC 11009.908: [DefNew: 70201K->1043K(78912K), 0.0050655 secs] 81462K->12304K(253696K), 0.0051476 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] Heap def new generation total 78912K, used 66339K [0x02a60000, 0x07ff0000, 0x17fb0000) eden space 70208K, 92% used [0x02a60000, 0x06a18d30, 0x06ef0000) from space 8704K, 12% used [0x06ef0000, 0x07000188, 0x07770000) to space 8704K, 0% used [0x07770000, 0x07770000, 0x07ff0000) tenured generation total 174784K, used 11261K [0x17fb0000, 0x22a60000, 0x42a60000) the space 174784K, 6% used [0x17fb0000, 0x18aaf4f0, 0x18aaf600, 0x22a60000) compacting perm gen total 22784K, used 22591K [0x42a60000, 0x440a0000, 0x46a60000) the space 22784K, 99% used [0x42a60000, 0x4406fe28, 0x44070000, 0x440a0000) No shared spaces configured.
最直观的信息是server端在启动的时候进行了3次Full GC,然后每一个小时左右会进行一次Full GC。
如果希望得到更为详细的gc日志信息,可以在sever端的run.xml中run和debug中加入如下参数:
<jvmarg value="-XX:+PrintGCDateStamps"/>
<jvmarg value="-XX:+PrintGCDetails"/>
<jvmarg value="-Xloggc:./gclogs"/>
<jvmarg value="-XX:+PrintHeapAtGC"/>
和之前的参数相比,多了<jvmarg value="-XX:+PrintHeapAtGC"/>一行。启动server端后发现server文件夹下多了一个名为gclogs的文件。查看gclogs文件的内容如下,相比较之前的日志信息要详细了许多。
{Heap before GC invocations=0 (full 0):
def new generation total 78656K, used 69952K [0x02a60000, 0x07fb0000, 0x17fb0000)
eden space 69952K, 100% used [0x02a60000, 0x06eb0000, 0x06eb0000)
from space 8704K, 0% used [0x06eb0000, 0x06eb0000, 0x07730000)
to space 8704K, 0% used [0x07730000, 0x07730000, 0x07fb0000)
tenured generation total 174784K, used 0K [0x17fb0000, 0x22a60000, 0x42a60000)
the space 174784K, 0% used [0x17fb0000, 0x17fb0000, 0x17fb0200, 0x22a60000)
compacting perm gen total 12544K, used 12468K [0x42a60000, 0x436a0000, 0x46a60000)
the space 12544K, 99% used [0x42a60000, 0x4368d0e0, 0x4368d200, 0x436a0000)
No shared spaces configured.
2015-05-04T10:07:17.234+0800: 10.983: [GC 10.983: [DefNew: 69952K->3374K(78656K), 0.0179218 secs] 69952K->3374K(253440K), 0.0179821 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]
Heap after GC invocations=1 (full 0):
def new generation total 78656K, used 3374K [0x02a60000, 0x07fb0000, 0x17fb0000)
eden space 69952K, 0% used [0x02a60000, 0x02a60000, 0x06eb0000)
from space 8704K, 38% used [0x07730000, 0x07a7bbc8, 0x07fb0000)
to space 8704K, 0% used [0x06eb0000, 0x06eb0000, 0x07730000)
tenured generation total 174784K, used 0K [0x17fb0000, 0x22a60000, 0x42a60000)
the space 174784K, 0% used [0x17fb0000, 0x17fb0000, 0x17fb0200, 0x22a60000)
compacting perm gen total 12544K, used 12468K [0x42a60000, 0x436a0000, 0x46a60000)
the space 12544K, 99% used [0x42a60000, 0x4368d0e0, 0x4368d200, 0x436a0000)
No shared spaces configured.
上面所述的gc日志文件是覆盖型的,重新启动一次JVM,新的文件将会覆盖旧的文件。
分析日志之前,先大概复习一下Java的内存模型。
Java堆内存的分代如下图:
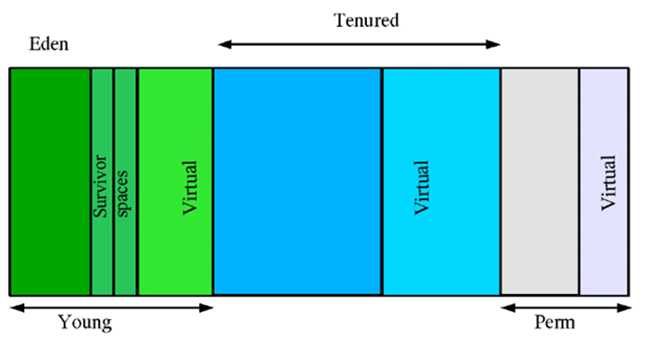
当GC发生在新生代时,称为Minor GC,次收集;当GC发生在年老代时,称为Major GC。一般的,Minor GC的发生频率要比Major GC高很多。
GC和Full GC是垃圾回收的停顿类型,而不是区分是新生代还是年老代,如果有 Full 说明发生了Stop-The-World 。如果是调用 System.gc() 触发的,那么将显示的是 [Full GC (System)] 。上面的gc日志文件中一小时出现了一次[Full GC (System)],可能是显示地调用了System.gc(),或者是RMI应用所导致的。
下面来分析gc日志中的内容:
2015-04-29T11:17:40.703+0800: 2.456: [Full GC (System) 2.456: [Tenured: 0K->3382K(174784K), 0.0546714 secs] 67363K->3382K(253440K), [Perm : 12488K->12488K(12544K)], 0.0547715 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
Full GC针对的是新生代、年老代和永生代。可以看到由于部分类从新生代进入到了年老代,Tenured所占内存反而会增大,永生代的变化也不会太大。整个堆大小的变化67363K->3382K(253440K)主要是发生在新生代。
2015-04-29T12:21:14.390+0800: 3810.844: [GC 3810.844: [DefNew: 70208K->1096K(78912K), 0.0057242 secs] 79972K->10861K(253696K), 0.0058007 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
普通GC回收的是新生代,由70208K变为了1096K,减少了69112k。整个堆的大小由79972K变味了10861K,减少了69111k。也就更说明了普通的GC发生在新生代上。
应用进行一次GC,新生代可以一般可以回收70%~95%的空间,而永久代的GC效率远小于此。所以新生代和永生代采用了截然不同的内存回收算法。
永生代的回收主要体现在无用类信息的卸载,在大量使用反射、动态代理、CGLib等bytecode框架、动态生成JSP以及OSGi这类频繁自定义ClassLoader的场景都需要JVM具备类卸载的支持以保证永久代不会溢出,使用-XX:+ClassUnloading参数将允许JVM卸载无用的类信息。
最基础的搜集算法是“标记-清除算法”(Mark-Sweep)。
如它的名字一样,算法分成“标记”和“清除”两个阶段,首先标记出所有需要回收的对象,然后回收所有需要回收的对象。说它是最基础的收集算法原因是后续的收集算法都是基于这种思路并优化其缺点得到的。
它的主要缺点有两个,一是效率问题,标记和清理两个过程效率都不高,二是空间问题,标记清理之后会产生大量不连续的内存碎片,空间碎片太多可能会导致后续使用中无法找到足够的连续内存而提前触发另一次的垃圾搜集动作。
为了解决效率问题,一种称为“复制”(Copying)的搜集算法出现。
它将可用内存划分为两块,每次只使用其中的一块,当半区内存用完了,仅将还存活的对象复制到另外一块上面,然后就把原来整块内存空间一次清理掉。这样使得每次内存回收都是对整个半区的回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存就可以了,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,未免太高了一点。
现在的商业虚拟机中都是用了这一种收集算法来回收新生代,IBM有专门研究表明新生代中的对象98%是朝生夕死的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的eden空间和2块较少的survivor空间,每次使用eden和其中一块survivor,当回收时将eden和 survivor还存活的对象一次过拷贝到另外一块survivor空间上,然后清理掉eden和用过的survivor。
Sun Hotspot虚拟机默认eden和survivor的大小比例是8:1,也就是每次只有10%的内存是“浪费”的。当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有10%以内的对象存活,当survivor空间不够用时,需要依赖其他内存(譬如老年代)进行分配担保(Handle Promotion)。
复制收集算法在对象存活率高的时候,效率有所下降。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保用于应付半区内存中所有对象100%存活的极端情况,
在老年代一般不能直接选用复制算法,人们提出另外一种“标记-整理”(Mark-Compact)算法。
标记过程仍然一样,但后续步骤不是进行直接清理,而是令所有存活的对象一端移动,然后直接清理掉这端边界以外的内存。
下面关于收集器的描述都是基于Sun Hotspot虚拟机1.6版。
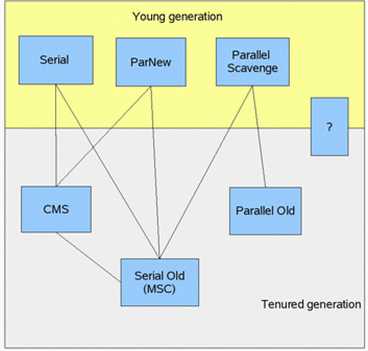
两个收集器之间存在连线的话就说明它们可以搭配使用。在介绍着些收集器之前,我们先明确一个观点:没有最好的收集器,也没有万能的收集器,只有最合适的收集器。
单线程收集器,收集时会暂停所有工作线程(我们将这件事情称之为Stop The World,下称STW),使用复制收集算法,是虚拟机运行在Client模式时的默认新生代收集器。
ParNew收集器就是Serial的多线程版本,除了使用多条收集线程外,其余行为包括算法、STW、对象分配规则、回收策略等都与Serial收集器一摸一样。是虚拟机运行在Server模式的默认新生代收集器,在单CPU的环境中,ParNew收集器并不会比Serial收集器有更好的效果。
Parallel Scavenge收集器(下称PS收集器)也是一个多线程收集器,也是使用复制算法,但它的对象分配规则与回收策略都与ParNew收集器有所不同,它是以吞吐量最大化(即GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化。
Serial Old是单线程收集器,使用标记-整理算法,是老年代的默认的收集器。
老年代版本吞吐量优先收集器,使用多线程和标记-整理算法,JVM 1.6提供,在此之前,新生代使用了PS收集器的话,老年代除Serial Old外别无选择,因为PS无法与CMS收集器配合工作。
CMS是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总体GC时间最小),但它能尽可能降低GC时服务的停顿时间,这一点对于实时或者高交互性应用(譬如证券交易)来说至关重要,这类应用对于长时间STW一般是不可容忍的。CMS收集器使用的是标记-清除算法,也就是说它在运行期间会产生空间碎片,所以虚拟机提供了参数开启CMS收集结束后再进行一次内存压缩。
标签:
原文地址:http://www.cnblogs.com/lnlvinso/p/4477908.html