标签:
云计算越来越流行的今天,单一机器处理能力已经不能满足我们的需求,不得不采用大量的服务集群。服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,这些信息如何推送到各个节点?并且保证信息的一致性和可靠性?
众所周知,分布式协调服务很难正确无误的实现,它们很容易在竞争条件和死锁上犯错误。如何在这方面节省力气?Zookeeper是一个不错的选择。 Zookeeper背后的动机就是解除分布式应用在实现协调服务上的痛苦。本文在介绍Zookeeper的基本理论基础上,用Zookeeper实现了一 个配置管理中心,利用Zookeeper将配置信息分发到各个服务节点上,并保证信息的正确性和一致性。
引用官方的说法:“Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级 的服务,比如同步,配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在java上,提供java和C的客户端 API”。
Zookeeper服务自身组成一个集群(2n+1个服务允许n个失效)。Zookeeper服务有两个角色,一个是leader,负责写服务和数据同步,剩下的是follower,提供读服务,leader失效后会在follower中重新选举新的leader。
Zookeeper逻辑图如下,

Zookeeper表现为一个分层的文件系统目录树结构(不同于文件系统的是,节点可以有自己的数据,而文件系统中的目录节点只有子节点)。
数据模型结构图如下,

圆形节点可以含有子节点,多边形节点不能含有子节点。一个节点对应一个应用,节点存储的数据就是应用需要的配置信息。
应用配置集中到节点上,应用启动时主动获取,并在节点上注册一个watcher,每次配置更新都会通知到应用。
分布式命名服务,创建一个节点后,节点的路径就是全局唯一的,可以作为全局名称使用。
不同的系统都监听同一个节点,一旦有了更新,另一个系统能够收到通知。
Zookeeper能保证数据的强一致性,用户任何时候都可以相信集群中每个节点的数据都是相同的。一个用户创建一个节点作为锁,另一个用户检测该节点,如果存在,代表别的用户已经锁住,如果不存在,则可以创建一个节点,代表拥有一个锁。
每个加入集群的机器都创建一个节点,写入自己的状态。监控父节点的用户会受到通知,进行相应的处理。离开时删除节点,监控父节点的用户同样会收到通知。
我们公司做极光推送,Push 业务平台有大量的逻辑服务器,按业务类型分组。逻辑服务的运行依赖于配置,并且配置会在线调整,需要一个集中的配置项管理中心。Zookeeper的发布 与订阅特性以及发送更新通知的机制很好的满足了我们的需求。Zookeeper的容灾特性也免去了我们相关的大量管理工作。
下面我主要和大家分享一下Zookeeper在我们内部服务中的应用。
a. 我们的逻辑服务器包含两类配置。
一种为Acl(访问控制列表),用户的消息消费后,按照列表中的条件走向下一个逻辑服务器。另一种只是单独的算法逻辑的外提,称为Agl(访问算法列表),但是其中某些判断条件会经常变化。这两类配置被收集到了配置管理中心(即Zookeeper)。
逻辑图如下,
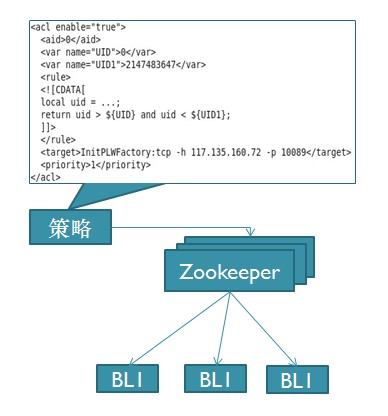
用户编辑好策略配置信息(xml格式),通过客户端加载到Zookeeper。Zookeeper立即通知其下的逻辑服务器(BLx),逻辑服务器 下载最新的配置策略,并应用新的策略。新的策略有可能改变某一段id范围内用户的数据流向,或越过原来的逻辑服务器,或指向新加入的逻辑服务器。
b. 数据模型设计
同一类型的逻辑服务在Zookeeper上创建一个节点,共享相同的配置信息。
该节点下面为策略配置项,分为Acl和Agl两类,如下图:(以代理逻辑服务为例)
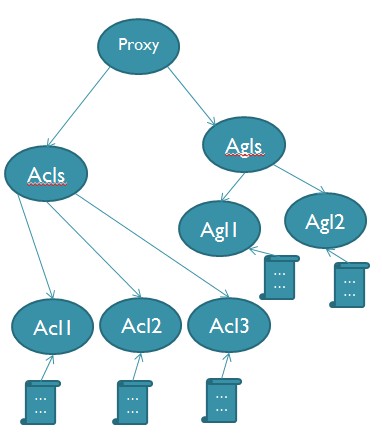
Acl1, Acl2, Acl3, Agl1, Agl2分别存有策略配置信息。变化后会通知监听Proxy节点的逻辑服务器,Proxy逻辑服务器下载最新策略,并应用该策略。新节点的加入和退出也会通知到Proxy逻辑服务器。
c. 业务处理流程如下图
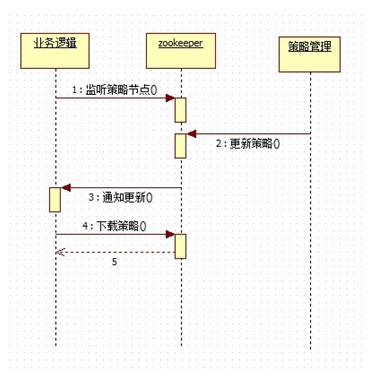
原文地址http://blog.jpush.cn/index.php/push_zookeeper_study_usage/
标签:
原文地址:http://www.cnblogs.com/405845829qq/p/4478027.html