标签:
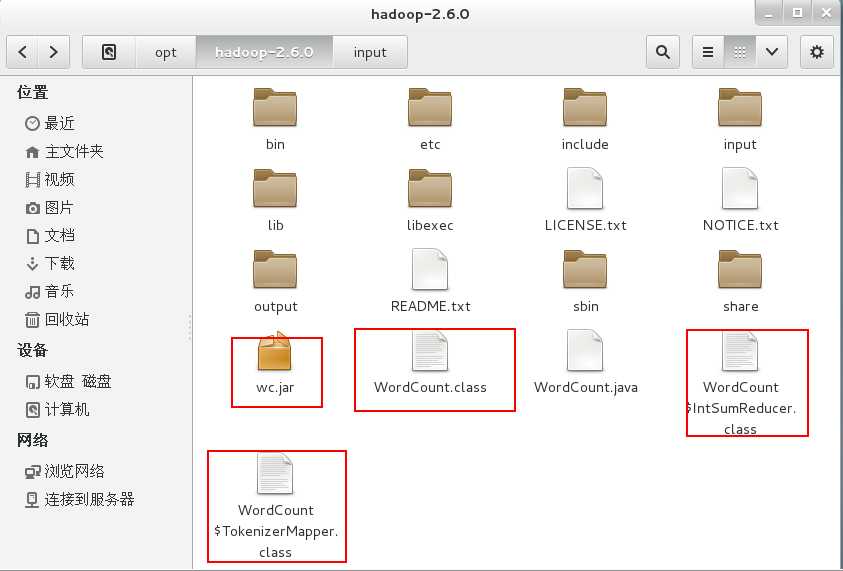
将源码文件WordCount.java放到Hadoop2.6.0文件夹中。
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
$ bin/hadoop com.sun.tools.javac.Main WordCount.java #将WordCount.java编译成三个.class文件
$ jar cf wc.jar WordCount*.class #将三个.class文件打包成jar文件
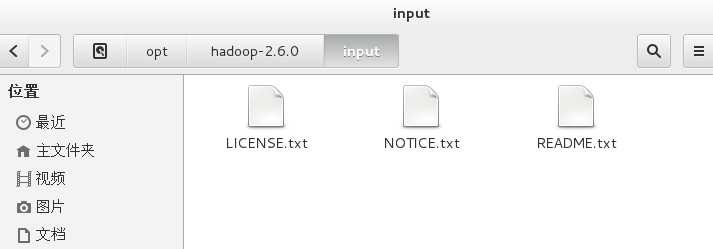
新建input文件夹,用于存放需要统计的文本。
cd /opt/hadoop-2.6.0
mkdir input
复制hadoop-2.6.0文件夹下的txt文件到input文件夹下。
cp *.txt /opt/hadoop-2.6.0/input
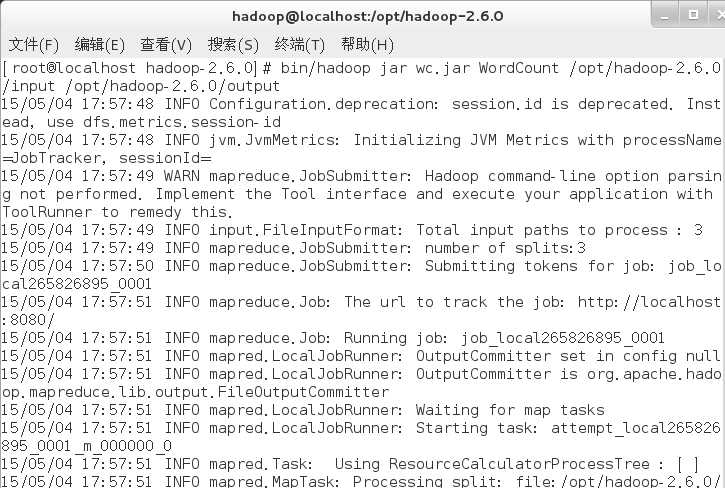
运行命令。
bin/hadoop jar wc.jar WordCount /opt/hadoop-2.6.0/input /opt/hadoop-2.6.0/output #自动生成output文件夹,用于存放分词统计结果。
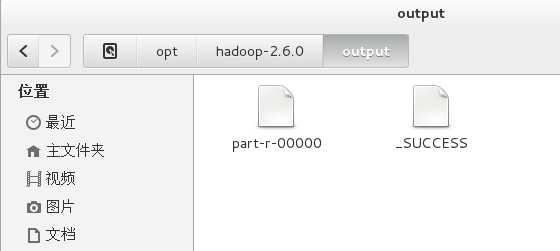
bin/hdfs dfs -cat /opt/hadoop-2.6.0/output/part-r-00000

至此,WordCount分词统计运行成功,Hadoop环境搭建成功。
标签:
原文地址:http://www.cnblogs.com/hehaiyang/p/4478233.html