标签:style class blog code java http
spark1.0.0新版本的于2014-05-30正式发布啦,新的spark版本带来了很多新的特性,提供了更好的API支持,spark1.0.0增加了Spark SQL组件,增强了标准库(ML、streaming、GraphX)以及对JAVA和Python语言的支持;
下面,我们首先进行spark1.0.0集群的安装,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机,增加更多的slave只需重复slave部分的内容即可。:
系统版本:
1. 安装JDK和hadoop集群
安装过程参见这里
2. 下载安装Scala
tar -xzvf scala-2.11.1.tgz
mv scala-2.11.1 /usr/lib/
在文件末尾添加scala路径

输入 source /etc/profile 使路径生效
PS:scala需要在所有slave节点上配置
3. 下载安装spark
tar -xzvf spark-1.0.0-bin-hadoop2.tgz
在文件末尾添加spark路径

输入 source /etc/profile 使路径生效
若没有该文件,则将 spark-env.sh.template 文件重命名即可,向文件中添加scala、java、hadoop路径以及master
ip等信息。
mv spark-env.sh.template
spark-env.sh
vi spark-env.sh
![]()
![]()

vi
slaves
![]()
4.
在所有slave机器上安装配置spark
现在可以将master主机上的spark文件分发给所有的slave节点,注意slave与master的spark所在目录必须一致,因为master会登录到slave上执行命令,并认为slave的spark路径与自己一样scp -r spark-1.0.0-bin-hadoop2 hadoop@slave:/home/hadoop/
5.启动spark集群
在master主机上执行命令:
cd
~/spark-1.0.0-bin-hadoop2/sbin
./start-all.sh
检测进程是否启动:输入 jps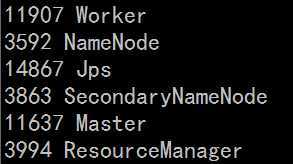
配置完成
6.
下面体验一下spark自带的例子
./bin/run-example
SparkPi

scala实现一个spark app
官方说明地址,这个小例子用于统计输入文件中字母“a”和字母“b”的个数。网站上提供了scala、java、python三种实现,这里就只做一下scala的吧,这里需要安装SBT(我们使用 sbt 创建、测试、运行和提交作业,可以简单将SBT看做是Scala世界的Maven)。
spark-1.0.0木有自带的sbt,我们可以选择手动安装,当然也可以选择sudo apt-get install
sbt的方式(我的系统中木有找到sbt包,所以就只有手动安装咯)。安装方法如下:
解压sbt到/home/hadoop/主目录下(hadoop是我的用户名,其实就是我的HOME啦) tar
-zxvf sbt-0.13.5.tgz
cd sbt/bin
java -jar sbt-launch.jar #进行sbt安装,时间大约一个小时吧,会下载很多东东,所以记得要联网哦
sudo vi /etc/profile
![]()
输入source /etc/profile 使路径生效
sbt安装完成,下面就来写这个简单的spark app吧

name := "Simple Project" version := "1.0" scalaVersion := "2.10.4" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.0.0" resolvers += "Akka Repository" at "http://repo.akka.io/releases/"

/* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) } }
PS:由于我们之前在spark配置过程中将hadoop路径配置好了,因此这里的输入路径YOUR_SPARK_HOME/XXX实际上为HDFS文件系统中的文件,存储位置与hadoop配置文件core-site.xml中的<name>相关(具体可参见这里,这个地方很容易出错)。因此需要先将README.md文件put到hdfs上面:

cd ~/SimpleApp
sbt package #打包过程,时间可能会比较长,最后会出现[success]XXX
PS:成功后会生成许多文件 target/scala-2.10/simple-project_2.10-1.0.jar等
spark-submit --class "SimpleApp" --master local target/scala-2.10/simple-project_2.10-1.0.jar

7.
停止spark集群
cd
~/spark-1.0.0-bin-hadoop2/sbin
./stop-all.sh
本文为原创博客,若转载请注明出处。
Ubuntu 12.04下spark1.0.0 集群搭建(原创),布布扣,bubuko.com
Ubuntu 12.04下spark1.0.0 集群搭建(原创)
标签:style class blog code java http
原文地址:http://www.cnblogs.com/tec-vegetables/p/3780046.html