几乎每一个前端程序员都知道应该把script标签放在页面底部。关于这个经典的论述可以追溯到Nicholas的
High Performance Javasript 这本书的第一章Loading and Execution中,他之所以建议这么做是因为:
-
Put all <script> tags at the bottom of the page, just inside of the closing </body> tag. This ensures that the page can be almost completely rendered before script execution begins.
复制代码
简而言之,如果浏览器加载并执行脚本,会引起页面的渲染被暂停,甚至还会阻塞其他资源(比如图片)的加载。为了更快的给用户呈现网页内容,更好的用户体验,应该把脚本放在页面底部,使之最后加载。
为什么要在标题中使用“再”这个字?因为在工作中逐渐发现,我们经常谈论的一些页面优化技巧,比如上面所说的总是把脚本放在页面的底部,压缩合并样式或者脚本文件等,时至今日已不再是最佳的解决方案,甚至事与愿违,转化为性能的毒药。这篇文章所要聊的,便是展示某些不被人关注的浏览器特性或者技巧,来继续完成资源加载性能优化的任务。
一. Preloader 什么是Preloader
首先让我们看一看这样一类资源分布的页面:
-
<head>
-
<link rel="stylesheet" type="text/css" href="">
-
<script type="text/javascript"></script>
-
</head>
-
<body>
-
<img src="">
-
<img src="">
-
<img src="">
-
<img src="">
-
<img src="">
-
<img src="">
-
<img src="">
-
<img src="">
-
<script type="text/javascript"></script>
-
<script type="text/javascript"></script>
-
<script type="text/javascript"></script>
-
</body>
复制代码
这类页面的特点是,一个外链脚本置于页面头部,三个外链脚本置于页面的底部,并且是故意跟随在一系列img之后,在Chrome中页面加载的网络请求瀑布图如下:
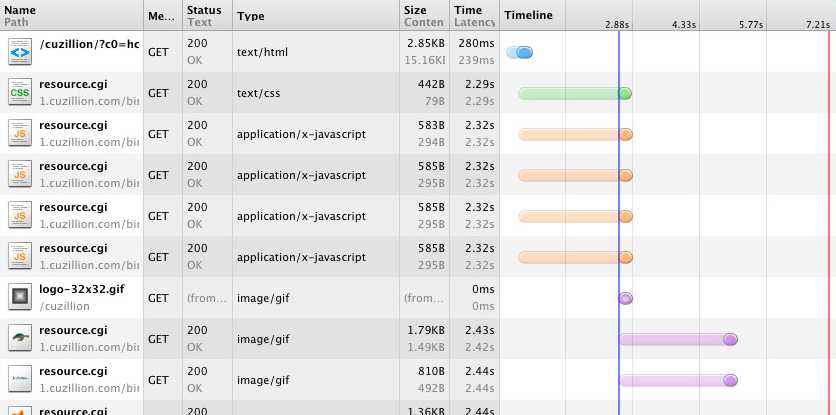
值得注意的是,虽然脚本放置在图片之后,但加载仍先于图片。为什么会出现这样的情况?为什么故意置后资源能够提前得到加载?
虽然浏览器引擎的实现不同,但原理都十分的近似。不同浏览器的制造厂商们(vendor)非常清楚浏览器的瓶颈在哪(比如network,
javascript evaluate, reflow, repaint)。针对这些问题,浏览器也在不断的进化,所以我们才能看到更快的脚本引擎,调用GPU的渲染等一推陈出新的优化技术和方案。
同样在资源加载上,早在IE8开始,一种叫做lookahead pre-parser(在Chrome中称为preloader)的机制就已经开始在不同浏览器中兴起。IE8相对于之前IE版本的提升除了将每台host最高并行下载的资源数从2提升至6,并且能够允许并行下载脚本文件之外,最后就是这个lookahead
pre-parser机制
但我还是没有详述这是一个什么样的机制,不着急,首先看看与IE7的对比:
以上面的页面为例,我们看看IE7下的瀑布图:
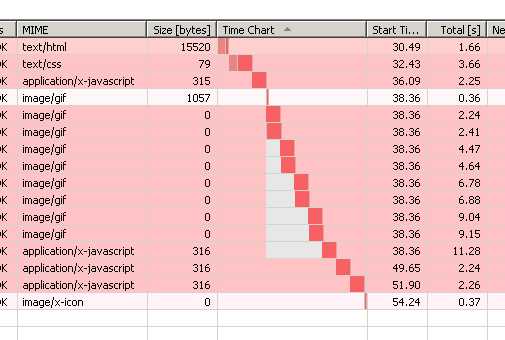
底部的脚本并没有提前被加载,并且因为由于单个域名最高并行下载数2的限制,资源总是两个两个很整齐的错开并行下载。
但在IE8下,很明显底部脚本又被提前:
并没有统一的标准规定这套机制应具备何种功能已经如何实现。但你可以大致这么理解:浏览器通常会准备两个页面解析器parser,一个(main
parser)用于正常的页面解析,而另一个(preloader)则试图去文档中搜寻更多需要加载的资源,但这里的资源通常仅限于外链的js、stylesheet、image;不包括audio、video等。并且动态插入页面的资源无效。
但细节方面却值得注意:
-
比如关于preloader的触发时机,并非与解析页面同时开始,而通常是在加载某个head中的外链脚本阻塞了main parser的情况下才启动;
-
也不是所有浏览器的preloader会把图片列为预加载的资源,可能它认为图片加载过于耗费带宽而不把它列为预加载资源之列;
-
preloader也并非最优,在某些浏览器中它会阻塞body的解析。因为有的浏览器将页面文档拆分为head和body两部分进行解析,在head没有解析完之前,body不会被解析。一旦在解析head的过程中触发了preloader,这无疑会导致head的解析时间过长。
Preloader在响应式设计中的问题
preloader的诞生本是出于一番好意,但好心也有可能办坏事。
filamentgroup有一种著名的响应式设计的图片解决方案Responsive
Design Images:
-
<html>
-
<head>
-
<title></title>
-
<script type="text/javascript" src="./responsive-images.js"></script>
-
</head>
-
<body>
-
<img src="./running.jpg?medium=_imgs/running.medium.jpg&large=_imgs/running.large.jpg">
-
</body>
-
</html>
复制代码
它的工作原理是,当responsive-images.js加载完成时,它会检测当前显示器的尺寸,并且设置一个cookie来标记当前尺寸。同时你需要在服务器端准备一个.htaccess文件,接下来当你请求图片时,.htaccess中的配置会检测随图片请求异同发送的Cookie是被设置成medium还是large,这样也就保证根据显示器的尺寸来加载对于的图片大小。
很明显这个方案成功的前提是,js执行先于发出图片请求。但在Chrome下打开,你会发现执行顺序是这样:
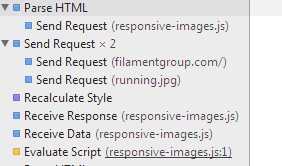
responsive-images.js和图片几乎是同一时间发出的请求。结果是第一次打开页面给出的是默认小图,如果你再次刷新页面,因为Cookie才设置成功,服务器返回的是大图。
严格意义上来说在某些浏览器中这不一定是preloader引起的问题,但preloader引起的问题类似:插入脚本的顺序和位置或许是开发者有意而为之的,但preloader的这种“聪明”却可能违背开发者的意图,造成偏差。
如果你觉得上一个例子还不够说明问题的话,最后请考虑使用picture(或者@srcset)元素的情况:
-
<picture>
-
<source src="med.jpg" media="(min-width: 40em)" />
-
<source src="sm.jpg"/>
-
<img src="fallback.jpg" alt="" />
-
</picture>
复制代码
在preloader搜寻到该元素并且试图去下载该资源时,它应该怎么办?一个正常的paser应该是在解析该元素时根据当时页面的渲染布局去下载,而当时这类工作不一定已经完成,preloader只是提前找到了该元素。退一步来说,即使不考虑页面渲染的情况,假设preloader在这种情形下会触发一种默认加载策略,那应该是"mobile
first"还是"desktop first"?默认应该加载高清还是低清照片?
二. JS Loader
理想是丰满的,现实是骨感的。出于种种的原因,我们几乎从不直接在页面上插入js脚本,而是使用第三方的加载器,比如seajs或者requirejs。关于使用加载器和模块化开发的优势在这里不再赘述。但我想回到原点,讨论应该如何利用加载器,就从seajs与requirejs的不同聊起。
在开始之前我已经假设你对requirejs与seajs语法已经基本熟悉了,如果还没有,请移步这里:
BTW: 如果你还是习惯在部署上线前把所有js文件合并打包成一个文件,那么seajs和requirejs其实对你来说并无区别。
seajs与requirejs在模块的加载方面是没有差异的,无论是requirejs在定义模块时定义的依赖模块,还是seajs在factory函数中require的依赖模块,在会在加载当前模块时被载入,异步,并且顺序不可控。差异在于factory函数执行的时机。
执行差异
为了增强对比,我们在定义依赖模块的时候,故意让它们的factory函数要执行相当长的时间,比如1秒:
-
// dep_A.js定义如下,dep_B、dep_C定义同理
-
-
define(function(require, exports, module) {
-
(function(second) {
-
var start = +new Date();
-
while (start + second * 1000 > +new Date()) {}
-
})(window.EXE_TIME);
-
// window.EXE_TIME = 1;此处会连续执行1s
-
-
exports.foo = function() {
-
console.log("A");
-
}
-
})
复制代码
为了增强对比,设置了三组进行对照试验,分别是:
-
//require.js:
-
require(["dep_A", "dep_B", "dep_C"], function(A, B, C) {
-
});
-
//sea.js:
-
define(function(require, exports, module) {
-
var mod_A = require("dep_A");
-
var mod_B = require("dep_B");
-
var mod_C = require("dep_C");
-
});
-
//sea.js(定义依赖但并不require):
-
define(["dep_A", "dep_B", "dep_C"], function(require, exports, module){
-
}
复制代码
接下来我们看看代码执行的瀑布图:
1.require.js:在加载完依赖模块之后立即执行了该模块的factory函数
2.sea.js: 下面两张图应该放在一起比较。两处代码都同时加载了依赖模块,但因为没有require的关系,第三张图中没有像第二张图那样执行耗时的factory函数。可见seajs执行的原则正如CMD标准中所述Execution
must be lazy。
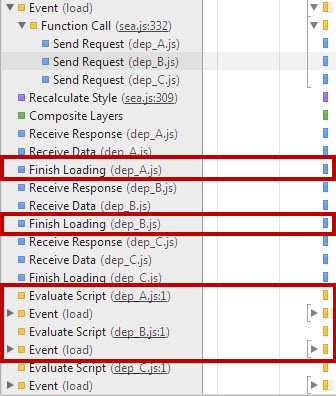
我想进一步表达的是,无论requirejs和seajs,通常来说大部分的逻辑代码都会放在模块的factory函数中,所以factory函数执行的代价是非常大的。但上图也同样告诉我们模块的define,甚至模块文件的Evaluate代价非常小,与factory函数无关。所以我们是不是应该尽可能的避免执行factory函数,或者等到我们需要的指定功能的时候才执行对应的factory函数?比如:
document.body.onclick = function () { require(some_kind_of_module);}
这是非常实际的问题,比如爱奇艺一个视频播放的页面,我们有没有必要在第一屏加载页面的时候就加载登陆注册,或者评论,或者分享功能呢?因为有非常大的可能用户只是来这里看这个视频,直至看完视频它都不会用到登陆注册功能,也不会去分享这个视频等。加载这些功能不仅仅对浏览器是一个负担,还有可能调用后台的接口,这样的性能消耗是非常可观的。
我们可以把这样称之为"懒执行"。虽然seajs并非有意实现如上所说的“懒执行”(它只是在尽可能遵循CommonJS标准靠近)。但“懒执行”确实能够有助于提升一部分性能。
但也有人会对此产生顾虑。
记得玉伯转过的一个帖子:SeaJS与RequireJS最大的区别。我们看看其中反对这么做的人的观点:
我个人感觉requirejs更科学,所有依赖的模块要先执行好。如果A模块依赖B。当执行A中的某个操doSomething()后,再去依赖执行B模块require(‘B‘);如果B模块出错了,doSomething的操作如何回滚? 很多语言中的import, include, useing都是先将导入的类或者模块执行好。如果被导入的模块都有问题,有错误,执行当前模块有何意义?
而依赖dependencies是工厂的原材料,在工厂进行生产的时候,是先把原材料一次性都在它自己的工厂里加工好,还是把原材料的工厂搬到当前的factory来什么时候需要,什么时候加工,哪个整体时间效率更高?
首先回答第一个问题。
第一个问题的题设并不完全正确,“依赖”和“执行”的概念比较模糊。编程语言执行通常分为两个阶段,编译(compilation)和运行(runtime)。对于静态语言(比如C/C++)来说,在编译时如果出现错误,那可能之前的编译都视为无效,的确会出现描述中需要回滚或者重新编译的问题。但对于动态语言或者脚本语言,大部分执行都处在运行时阶段或者解释器中:假设我使用Nodejs或者Python写了一段服务器运行脚本,在持续运行了一段时间之后因为某项需求要加载某个(依赖)模块,同时也因为这个模块导致服务端挂了——我认为这时并不存在回滚的问题。在加载依赖模块之前当前的模块的大部分功能已经成功运行了。
再回答第二个问题。
对于“工厂”和“原材料”的比喻不够恰当。难道依赖模块没有加载完毕当前模块就无法工作吗?requirejs的确是这样的,从上面的截图可以看出,依赖模块总是先于当前模块加载和执行完毕。但我们考虑一下基于CommonJS标准的Nodejs的语法,使用require函数加载依赖模块可以在页面的任何位置,可以只是在需要的时候。也就是说当前模块不必在依赖模块加载完毕后才执行。
你可能会问,为什么要拿AMD标准与CommonJS标准比较,而不是CMD标准?
玉伯在CommonJS
是什么这篇文章中已经告诉了我们CMD某种程度上遵循的就是CommonJS标准:
从上面可以看出,Sea.js 的初衷是为了让 CommonJS Modules/1.1 的模块能运行在浏览器端,但由于浏览器和服务器的实质差异,实际上这个梦无法完全达成,也没有必要去达成。
更好的一种方式是,Sea.js 专注于 Web 浏览器端,CommonJS 则专注于服务器端,但两者有共通的部分。对于需要在两端都可以跑的模块,可以 有便捷的方案来快速迁移。
其实AMD标准的推出同时也是遵循CommonJS,在requirejs官方文档的COMMONJS
NOTES中说道:
-
CommonJS defines a module format. Unfortunately, it was defined without giving browsers equal footing to other JavaScript environments. Because of that, there are CommonJS spec proposals for Transport formats and an asynchronous require.
-
RequireJS tries to keep with the spirit of CommonJS, with using string names to refer to dependencies, and to avoid modules defining global objects, but still allow coding a module format that works well natively in the browser.
复制代码
CommonJS当然是一个理想的标准,但至少现阶段对浏览器来说还不够友好,所以才会出现AMD与CMD,其实他们都是在做同一件事,就是致力于前端代码更友好的模块化。所以个人认为依赖模块的加载和执行在不同标准下实现不同,可以理解为在用不同的方式在完成同一个目标,
并不是一件太值得过于纠结的事。
懒加载
其实我们可以走的更远,对于非必须模块不仅仅可以延迟它的执行,甚至可以延迟它的加载。
但问题是我们如何决定一个模块是必须还是非必须呢,最恰当莫过取决于用户使用这个模块的概率有多少。Faceboook早在09年的时候就已经注意到这个问题:Frontend
Performance Engineering in Facebook : Velocity 2009,只不过他们是以样式碎片来引出这个问题。
假设我们需要在页面上加入A、B、C三个功能,意味着我们需要引入A、B、C对应的html片段和样式碎片(暂不考虑js),并且最终把三个功能样式碎片在上线前压缩到同一个文件中。但可能过了相当长时间,我们移除了A功能,但这个时候大概不会有人记得也把关于A功能的样式从上线样式中移除。久而久之冗余的代码会变得越来越多。Facebook引入了一套静态资源管理方案(Static
Resource Management)来解决这个问题:

具体来说是将样式的“声明”(Declaration)和请求(Delivery)请求,并且是否请求一个样式由是否拥有该功能的
html片段决定。
当然同时也考虑也会适当的合并样式片段,但这完全是基于使用算法对用户使用模块情况进行分析,挑选出使用频率比较高的模块进行拼合。
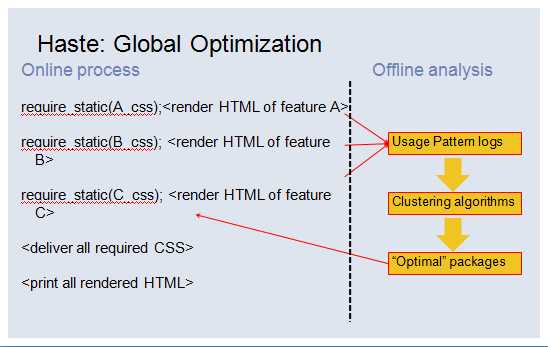
这一套系统不仅仅是对样式碎片,对js,对图片sprites的拼合同样有效。
你会不会觉得我上面说的懒加载还是离自己太远了? 但然不是,你去看看现在的人人网个人主页看看
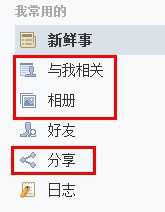
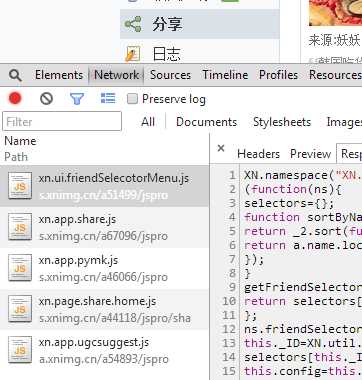
如果你在点击图中标注的“与我相关”、“相册”、“分享”按钮并观察Chrome的Timeline工具,那么都是在点击之后才加载对应的模块
三. Delay Execution 利用浏览器缓存
脚本最致命的不是加载,而是执行。因为何时加载毕竟是可控的,甚至可以是异步的,比如通过调整外链的位置,动态的创建脚本。但一旦脚本加载完成,它就会被立即执行(Evaluate
Script),页面的渲染也就随之停止,甚至导致在低端浏览器上假死。
更加充分的理由是,大部分的页面不是Single Page Application,不需要依靠脚本来初始化页面。服务器返回的页面是立即可用的,可以想象我们初始化脚本的时间都花在用户事件的绑定,页面信息的丰满(用户信息,个性推荐)。Steve
Souders发现在Alexa上排名前十的美国网站上的js代码,只有29%在window.onload事件之前被调用,其他的71%的代码与页面的渲染无关。
Steve Souders的ControlJS是我认为一直被忽视的一个加载器,它与Labjs一样能够控制的脚本的异步加载,甚至(包括行内脚本,但不完美)延迟执行。它延迟执行脚本的思路非常简单:既然只要在页面上插入脚本就会导致脚本的执行,那么在需要执行的时候才把脚本插入进页面。但这样一来脚本的加载也被延迟了?不,我们会通过其他元素来提前加载脚本,比如img或者是object标签,或者是非法的mine
type的script标签。这样当真正的脚本被插入页面时,只会从缓存中读取。而不会发出新的请求。
Stoyan
Stefanov在它的文章Preload CSS/JavaScript
without execution中详细描述了这个技巧, 如果判断浏览器是IE就是用image标签,如果是其他浏览器,则使用object元素:
-
window.onload = function () {
-
var i = 0,
-
max = 0,
-
o = null,
-
preload = [
-
// list of stuff to preload
-
],
-
isIE = navigator.appName.indexOf(‘Microsoft‘) === 0;
-
for (i = 0, max = preload.length; i < max; i += 1) {
-
if (isIE) {
-
new Image().src = preload[i];
-
continue;
-
}
-
o = document.createElement(‘object‘);
-
o.data = preload[i];
-
// IE stuff, otherwise 0x0 is OK
-
//o.width = 1;
-
//o.height = 1;
-
//o.style.visibility = "hidden";
-
//o.type = "text/plain"; // IE
-
o.width = 0;
-
o.height = 0;
-
// only FF appends to the head
-
// all others require body
-
document.body.appendChild(o);
-
}
-
};
复制代码
同时它还列举了其他的一些尝试,但并非对所有的浏览器都有效,比如:
type=prefetch
延迟执行并非仅仅作为当前页面的优化方案,还可以为用户可能打开的页面提前缓存资源,如果你对这两种类型的link元素熟悉的话:
-
<link rel="subresource" href="jquery.js">: subresource类型用于加载当前页面将使用(但还未使用)的资源(预先载入缓存中),拥有较高优先级
-
<link rel="prefetch" href="http://NextPage.html">: prefetch类型用于加载用户将会打开页面中使用到的资源,但优先级较低,也就意味着浏览器不做保证它能够加载到你指定的资源。
那么上一节延迟执行的方案就可以作为subresource与prefeth的回滚方案。同时还有其他的类型:
-
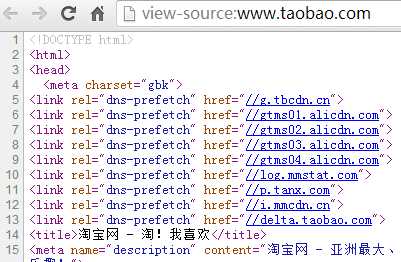
<link rel="dns-prefetch" href="//host_name_to_prefetch.com">: dns-prefetch类型用于提前dns解析和缓存域名主机信息,以确保将来再请求同域名的资源时能够节省dns查找时间,比如我们可以看到淘宝首页就使用了这个类型的标签:
-
:
-
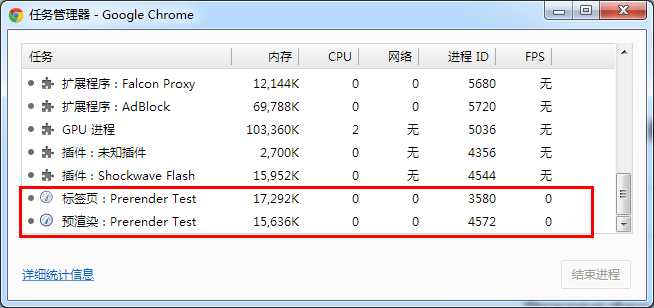
<link rel="prerender" href="http://example.org/index.html">: prerender类型就比较霸道了,它告诉浏览器打开一个新的标签页(但不可见)来渲染指定页面,比如这个页面:
这也就意味着如果用户真的访问到该页面时,就会有“秒开”的用户体验。
但现实并非那么美好,首先你如何能预测用户打开的页面呢,这个功能更适合阅读或者论坛类型的网站,因为用户有很大的概率会往下翻页;要注意提前的渲染页面的网络请求和优先级和GPU使用权限优先级都比其他页面的要低,浏览器对提前渲染页面类型也有一定的要求,具体可以参考这里
利用LocalStorage
在聊如何用它来解决我们遇到的问题之前,个人觉得首先应该聊聊它的优势和劣势。
比较性能这种事情,应该看怎么比,和谁比。
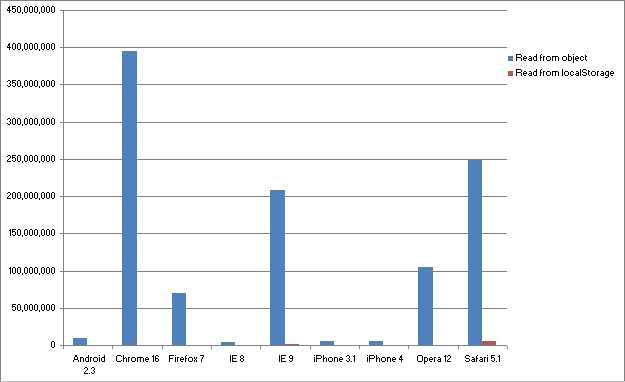
就“读”数据而言,如果你把“从LS中读一个值”和“从Object对象中读一个属性”相比,是不公平的,前者是从硬盘里读,后者是从内存里读,就好比让汽车与飞机赛跑一样,有一个benchmark各位可以参考一下:localStorage
vs. Objects:
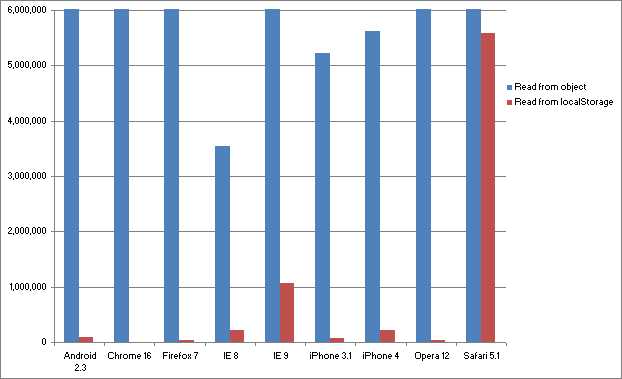
跑分的标准是OPS(operation per second),值当然是越高越好。你可能会注意到,在某个浏览器的对比列中,没有显示关于LS的红色列——这不是因为统计出错,而是因为LS的操作性能太差,跑分太低(相对从Object中读取属性而言),所以无法显示在同一张表格内,如果你真的想看的话,可以给你看一张放大的版本:
这样以来你大概就知道两者在什么级别上了。
在浏览器中与LS最相近的机制莫过于Cookie了:Cookie同样以key-value的形式进行存储,同样需要进行I/O操作,同样需要对不同的tab标签进行同步。同样有benchmark可以供我们进行参考:localStorage
vs. Cookies
从Brwoserscope中提供的结果可以看出,就Reading from cookie, Reading from localStorage getItem, Writing to cookie,Writing to localStorage property四项操作而言,在不同浏览器不同平台,读和写的效率都不太相同,有的趋于一致,有的大相径庭。
甚至就LS自己而言,不同的存储方式和不同的读取方式也会产生效率方面的问题。有两个benchmark非常值得说明问题:
在第一个测试中,Nicholas在LS中用四个key分别存储了100个字符,500个字符,1000个字符和2000个字符。测试分别读取不同长度字符的速度。结果是:读取速度与读取字符的长度无关。
第二个测试用于测试读取1000个字符的速度,不同的是对照组是一次性读取1000个字符;而实验组是从10个key中(每个key存储100个字符)分10次读取。结论: 是分10此读取的速度会比一次性读取慢90%左右。
LS也并非没有痛点。大部分的LS都是基于同一个域名共享存储数据,所以当你在多个标签打开同一个域名下的站点时,必须面临一个同步的问题,当A标签想写入LS与B标签想从LS中读同时发生时,哪一个操作应该首先发生?为了保证数据的一致性,在读或者在写时 务必会把LS锁住(甚至在操作系统安装的杀毒软件在扫描到该文件时,会暂时锁住该文件)。因为单线程的关系,在等待LS
I/O操作的同时,UI线程和Javascript也无法被执行。
但实际情况远比我们想象的复杂的多。为了提高读写的速度,某些浏览器(比如火狐)会在加载页面时就把该域名下LS数据加载入内存中,这么做的副作用是延迟了页面的加载速度。但如果不这么做而是在临时读写LS时再加载,同样有死锁浏览器的风险。并且把数据载入内存中也面临着将内存同步至硬盘的问题。
上面说到的这些问题大部分归咎于内部的实现,需要依赖浏览器开发者来改进。并且并非仅仅存在于LS中,相信在IndexedDB、webSQL甚至Cookie中也有类似的问题在发生。
实战开始
考虑到移动端网络环境的不稳定,为了避免网络延迟(network latency),大部分网站的移动端站点会将体积庞大的类库存储于本地浏览器的LS中。但百度音乐将这个技术也应用到了PC端,他们将所依赖的jQuery类库存入LS中。用一段很简单的代码来保证对jQuery的正确载入。我们一起来看看这段代码。代码详解就书写在注释中了:
-
!function (globals, document) {
-
var storagePrefix = "mbox_";
-
globals.LocalJs = {
-
require: function (file, callback) {
-
/*
-
如果无法使用localstorage,则使用document.write把需要请求的脚本写在页面上
-
作为fallback,使用document.write确保已经加载了所需要的类库
-
*/
-
if (!localStorage.getItem(storagePrefix + "jq")) {
-
document.write(‘<script src="‘ + file + ‘" type="text/javascript"></script>‘);
-
var self = this;
-
/*
-
并且3s后再请求一次,但这次请求的目的是为了获取jquery源码,写入localstorage中(见下方的_loadjs函数)
-
这次“一定”走缓存,不会发出多余的请求
-
为什么会延迟3s执行?为了确保通过document.write请求jQuery已经加载完成。但很明显3s也并非一个保险的数值
-
同时使用document.write也是出于需要故意阻塞的原因,而无法为其添加回调,所以延时3s
-
*/
-
setTimeout(function () {
-
self._loadJs(file, callback)
-
}, 3e3)
-
} else {
-
// 如果可以使用localstorage,则执行注入
-
this._reject(localStorage.getItem(storagePrefix + "jq"), callback)
-
}
-
},
-
_loadJs: function (file, callback) {
-
if (!file) {
-
return false
-
}
-
var self = this;
-
var xhr = new XMLHttpRequest;
-
xhr.open("GET", file);
-
xhr.onreadystatechange = function () {
-
if (xhr.readyState === 4) {
-
if (xhr.status === 200) {
-
localStorage.setItem(storagePrefix + "jq", xhr.responseText)
-
} else {}
-
}
-
};
-
xhr.send()
-
},
-
_reject: function (data, callback) {
-
var el = document.createElement("script");
-
el.type = "text/javascript";
-
/*
-
关于如何执行LS中的源码,我们有三种方式
-
1. eval
-
2. new Function
-
3. 在一段script标签中插入源码,再将该script标签插入页码中
-
关于这三种方式的执行效率,我们内部初步测试的结果是不同的浏览器下效率各不相同
-
参考一些jsperf上的测试,执行效率甚至和具体代码有关。
-
*/
-
el.appendChild(document.createTextNode(data));
-
document.getElementsByTagName("head")[0].appendChild(el);
-
callback && callback()
-
},
-
isSupport: function () {
-
return window.localStorage
-
}
-
}
-
}(window, document);
-
!
-
function () {
-
var url = _GET_HASHMAP ? _GET_HASHMAP("/player/static/js/naga/common/jquery-1.7.2.js") : "/player/static/js/naga/common/jquery-1.7.2.js";
-
url = url.replace(/^\/\/mu[0-9]*\.bdstatic\.com/g, "");
-
LocalJs.require(url, function () {})
-
}();
复制代码
因为桌面端的浏览器兼容性问题比移动端会严峻的多,所以大多数对LS利用属于“做加法”,或者“轻量级”的应用。最后一瞥不同站点在PC平台的对LS的使用情况:
-
比如百度和github用LS记录用户的搜素行为,为了提供更好的搜索建议
-
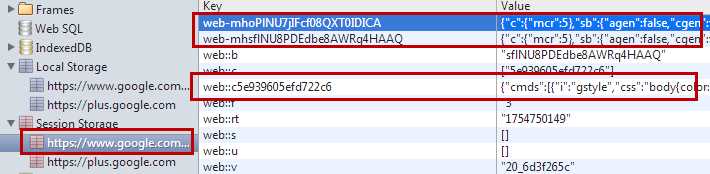
Twitter利用LS最主要的记录了与用户关联的信息(截图自我的Twitter账号,因为关注者和被关注者的不同数据会有差异):
-
userAdjacencyList表占40,158 bytes,用于记录每个字关联的用户信息
-
userHash表占36,883 bytes,用于记录用户被关注的人信息
-
Google利用LS记录了样式:
总结
No silver bullet.没有任何一项技术或者方案是万能的,虽然开源社区和浏览器厂商在提供给我们越来越丰富的资源,但并不意味着今后遇见的问题就会越来越少。相反,或许正因为多样性,和发展中技术的不完善,事情会变得更复杂,我们在选择时要权衡更多。我无意去推崇某一项解决方案,我想尽可能多的把这些方案与这些方案的厉害呈现给大家,毕竟不同人考虑问题的方面不同,业务需求不同。
还有一个问题是,本文描述的大部分技术都是针对现代浏览器而言,那么如何应对低端浏览器呢?
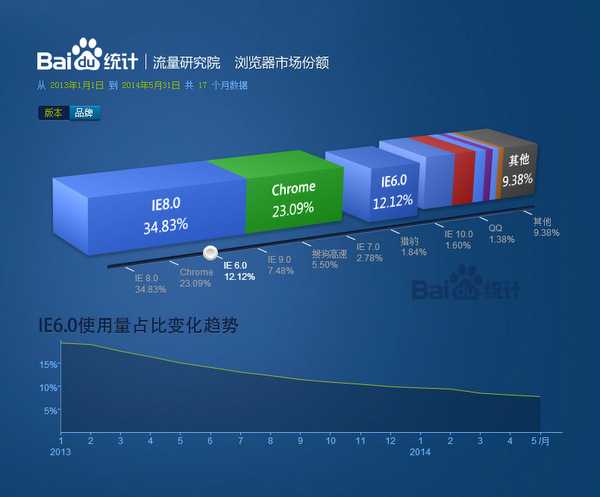
从百度统计这张17个月的浏览器市场份额图中可以看出(当然可能因为不同站点的用户特征不同会导致使用的浏览器分布与上图有出入),我们最关心的IE6的市场份额一直是呈现的是下滑的趋势,目前已经降至几乎与IE9持平;而IE9在今年的市场份额也一直稳步上升;IE7已经被遥遥甩在身后。领头的IE8与Chrome明显让我们感受到有足够的信心去尝试新的技术。还等什么,行动起来吧!
其他参考文献
|