标签:
Cifar-10是由Hinton的两个大弟子Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的数据集。Cifar是加拿大牵头投资的一个先进科学项目研究所。
说白了,就是看你穷的没钱搞研究,就施舍给你。Hinton、Bengio和他的学生在2004年拿到了Cifar投资的少量资金,建立了神经计算和自适应感知项目。
这个项目结集了不少计算机科学家、生物学家、电气工程师、神经科学家、物理学家、心理学家,加速推动了DL的进程。从这个阵容来看,DL已经和ML系的数据挖掘分的很远了。
DL强调的是自适应感知和人工智能,是计算机与神经科学交叉。DM强调的是高速、大数据、统计数学分析,是计算机和数学的交叉。
Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于
多分类(姊妹数据集Cifar-100达到100类,ILSVRC比赛则是1000类)。


可以看到,同已经成熟的人脸识别相比,普适物体识别挑战巨大,数据中含有大量特征、噪声,识别物体比例不一。而且分类庞大(SVM直接跪哭)。
因而,Cifar-10相对于传统图像识别数据集,是相当有挑战的。
Alex Krizhevsky在2012年的论文ImageNet Classification with Deep Convolutional Neural Networks 使用了一些改良CNN方法去
解决普适物体识别难题,效果惊人。尤其是开创性地使用了CUDA来加速神经网络训练,并且开放了Cuda-Convnet和绝秘CNN结构,群众反响热烈。
于是就有了今年GTC 2015老黄手捧着TitanX大喊:NVIDIA显卡伴你更好深度学习!在通用计算上,CUDA确实多方面压制OpenCL。
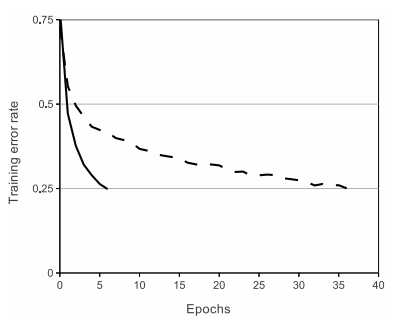
Alex的论文里可能困惑最大的就是这张奇葩的图。使用了ReLu的CNN在batchsize为100的训练中,epoch 5(5000次迭代,显卡好点只要80s)就把验证集错误率降到了25%。
而Tanh则要花上35个epoch。困惑点有两个:①居然下降那么快②我照着传统CNN模型改改,为什么只能降到30%,而且还在50+ epochs。
然后你去Cuda—Convnet(被墙了)的主页上一看,居然有人把Cifar-10的错误率降到了11%。难怪LeCun会说:已解决CIFAR-10,目标 ImageNet(ILSVRC)。
标签:
原文地址:http://www.cnblogs.com/neopenx/p/4480701.html