标签:
当用户在使用Hadoop 的 MapReduce 计算模型处理问题的时候,只需要设计好Mapper 和Reducer 处理函数,还有可能包括Combiner 函数。之后,新建一个Job 对象,并对Job 的运行环境进行一些配置,最后调用Job 的waitForCompletion 或者 submit 方法来提交作业即可。代码如下:
1 //新建默认的Job 配置对象 2 Configuration conf = new Configuration(); 3 //根据配置对象和Job 的名字来创建一个Job 对象 4 Job job = new Job(conf,"作业的名字"); 5 //当在集群中运行一个作业的时候,作业需要打包成jar的形式,Hadoop通过指定的类名来找到包含该类的jar 6 job.setJarByClass(主类名.class); 7 job.setMapperClass(Mapper 实现类.class); 8 job.setCombinerClass(作为Combiner 的Reducer实现类.class); 9 job.setReducerClass(Reducer 实现类.class); 10 job.setOutputKeyClass(输出Key的数据类型.class); 11 job.setOutputValueClass(输出alue的数据类型.class); 12 FileInputFormat.addInputPath(job, new Path(设置作业的输入路径)); 13 FileOutputFormat.setOutputPath(job, new Path(设置作业的输出路径)); 14 //将作业提交给集群处理 15 job.waitForCompletion(true);
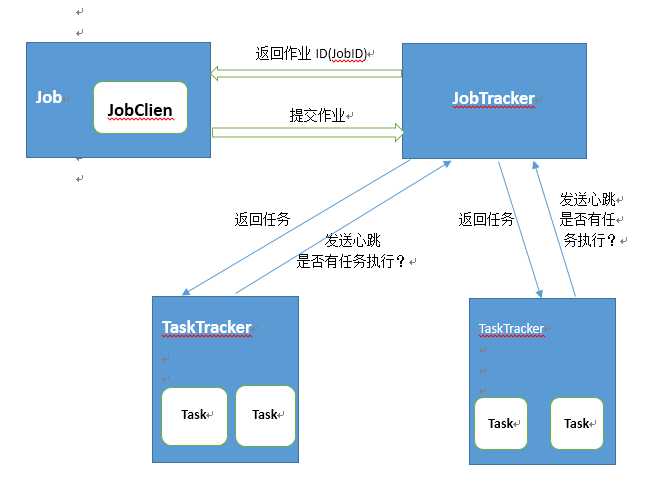
上图显示了MapReducer的作业执行过程。Job的waitForCompletion 方法内部依靠JobClient 来向JobTracker 提交作业。当JobTracker收到JobClient提交作业的请求之后,会将作业加入到作业队列中去,之后会返回给JobClient一个用于唯一标识该作业的JobID对象。JobTracker 作业队列中的作业会由TaskTracker来执行。TaskTracker 会定期想JobTracker发送心跳,查问JobTracker是否有任务需要进行执行。如果有,JobTrackler会通过心跳相应分配给TaskTracker来执行。当TaskTracker接受到任务后,会在本地创建一个Task来执行任务。
下面介绍JobClient在执行过程的几个重要的知识点:
1. JobConf MapReduce作业的配置信息
JobConf 类继承于Configuration类,它在Hadoop的Configuration基础信息的基础上,加入了一个与MapReduce作业相关的配置信息。用户就是通过该类来实现对Job作业的配置的。
2. JobSubmissionProtocol 作业提交借口
JobSubmissionProtocol 协议接口是JobClient和JobTracker 进行通信所需要的协议接口。该接口中定义了JobClient用于向JobTracker提交作业、获取作业的执行信息等方法。
3. RunningJob 正在运行的Job作业的借口
RunningJob 为用户提供了访问正在运行的MapReduce作业信息的接口。RunningJob 在JobClient中被实现了,所以我们可以通过JobClient来获得RunningJob 的一个实例,然后运用RunningJob 实例来查询正在运行的Job的相关信息。
4. JobStatus 和 JobProfile 作业状态信息和注册信息
JobStatus 对象代表的是Job的当前运行状态信息,比如组成该Job的所有Mapper任务已经完成的进度信息等,这些状态信息会随着Job的运行而不断发生变化。JobProfile对象代表的是Job添加到MapReduce框架时所携带的注册信息,这些注册信息是不会改变的。
5. JobSubmissionFiles 获得作业提交的文件
MapReduce在初始化的过程中,Hadoop框架会为用户提交的Job创建相应的目录,然后存储与该Job相关的文件,比如MapReduce需要的jar文件,或者Job的配置文件。JobSubmissionFiles类提供了访问与Job相关的文件以及与该Job所对应的分布式缓存中存放不同类型文件的目录的方法,但这个类只在Hadoop框架的内部被使用。
1. 向JobTracker请求一个新的作业的ID对象JobID
2.检查Job的输入输出。输入不能为空,而且在运行作业之前,输出不能已经存在
3.计算作业的所有的InputSplit 输入分片数即需要的Mapper 任务数量
4.启动与Job相关的分布式缓存DistributedCache
5.将作业运行时需要的资源包括Job 的jar包、配置文件等从Hadoop的分布式文件系统中复制到JobTracker的文件系统中的指定目录下
6.将作业提交到JobTracker 的作业队列中,并监控作业的运行状况
Hadoop 学习笔记三 --JobClient 的执行过程
标签:
原文地址:http://www.cnblogs.com/geekszhong/p/4482324.html