标签:
http://blog.csdn.net/neustar1/article/details/7478311
利用C/C++开发大型应用程序中,内存的管理与分配是一个需要认真考虑的部分。
本文描述了内存池设计原理并给出内存池的实现代码,代码支持Windows和Linux,多线程安全。
内存池设计过程中需要考虑好内存的分配与释放问题,其实也就是空间和时间的矛盾。
有的内存池设计得很巧妙,内存分配与需求相当,但是会浪费过多的时间去查找分配与释放,这就得不偿失;
实际使用中,我们更多的是关心内存分配的速度,而不是内存的使用效率。基于此,本文按照如下思想设计实现内存池。
主要包含三个结构:StiaticMemory, MemoryChunk和MemoryBlock,三者之间的关系如下图所示:
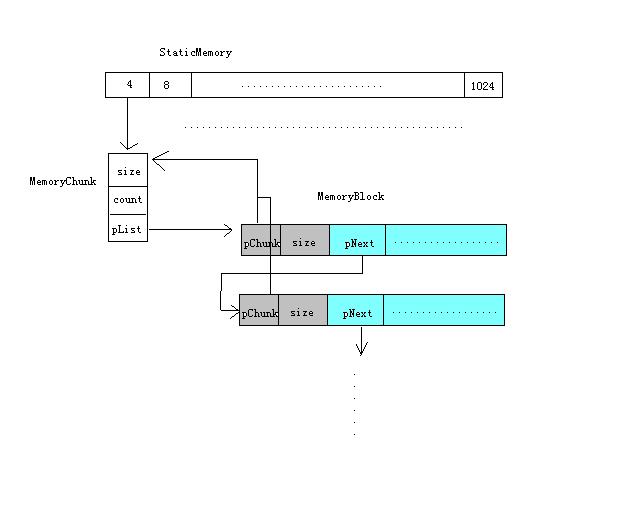
1.内存的分配:
(1)如果分配大小超过1024,直接采用malloc分配,分配的时候多分配sizeof(size_t)字节,用于保存该块的大小;
(2)否则根据分配大小,查找到容纳该大小的最小size的MemoryChunk;
(3)查找MemoryChunk的链表指针pList,找到空闲的MemoryBlock返回;
(4)如果pList为NULL,临时创建MemoryBlock返回;
(5)MemoryBlock头部包含两个成员,pChunk指向的所属的MemoryChunk对象,size表明大小,其后才是给用户使用的空间;
2.内存的释放:
(1)根据释放的指针,查找器size头部,即减去sizeof(size_t)字节,判断该块的大小;
(2)如果大小超过1024,直接free;
(3)否则交给MemoryChunk处理,而块的头部保存了该指针,因此直接利用该指针就可以收回该内存。
注意的问题:
上述设计的内存池通过冗余的头部来实现内存块的分配与释放,减少了内存池的操作时间,速度上要优于原始的malloc和free操作,同时减少了内存碎片的增加。
但是该设计中没有去验证释放的块冗余头部的正确性,因此故意释放不属于内存池中的块或者修改头部信息都会导致内存池操作失败,当然这些可以由程序员来控制。
此外,内存池中分配出去的内存块如果不主动释放,内存池没有保留信息,不会自动释放,但是在退出的时候会验证验证是否完全释放,其实这个在系统测试时候就可以检测出来,我想这个缺陷也是可以弥补的,在此提出,希望使用者注意。
下面贴上源码,如果对代码有任何建议或者发现存在的Bug,希望与我联系,共同学习交流,Tx。
MemoryChunk.h 文件,线程安全
StaticMemory.h文件,内存池对象
- #ifndef STATIC_MEMORY_H
- #define STATIC_MEMORY_H
- #include "MemoryChunk.h"
- /** @ StaticMemory.h
- * 定义实现内存池
- * 采用固定大小策略进行内存管理与分配
- * 减少因大量小内存分配导致的内存碎片增加
- */
- struct HeapHeader
- {
- size_t size;
- };
- struct MemoryHeap
- {
- HeapHeader header;
- char pBuffer;
- };
-
- class StaticMemory
- {
- public:
- typedef enum{MAX_SIZE=1024,MIN_SIZE=sizeof(MemoryChunk*)};
- StaticMemory()
- {
- chunkcount=0;
- for(size_t size=MIN_SIZE; size<=MAX_SIZE; size*=2)++chunkcount;
- //pChunkList=(MemoryChunk**)malloc(sizeof(MemoryChunk*)*chunkcount);
- pChunkList=new MemoryChunk*[chunkcount];
- int index=0;
- for(size_t size=MIN_SIZE; size<=MAX_SIZE; size*=2)
- {
- pChunkList[index++]=new MemoryChunk(size,1000);
- }
- }
- ~StaticMemory()
- {
- for(int index=0; index<chunkcount; ++index)
- {
- delete pChunkList[index];
- }
- //free(pChunkList);
- delete[] pChunkList;
- }
- void* Malloc(size_t size)
- {
- if(size>MAX_SIZE){
- return malloc(size);
- }
- int index=0;
- for(size_t tsize=MIN_SIZE; tsize<=MAX_SIZE; tsize*=2){
- if(tsize>=size)break;
- ++index;
- }
- return pChunkList[index]->malloc();
- }
- void Free(void* pMem)
- {
- if(!free(pMem))MemoryChunk::free(pMem);
- }
- protected:
- void* malloc(size_t size)
- {
- MemoryHeap* pHeap=(MemoryHeap*)::malloc(sizeof(HeapHeader)+size);
- if(pHeap){
- pHeap->header.size=size;
- return &pHeap->pBuffer;
- }
- return NULL;
- }
- bool free(void* pMem)
- {
- MemoryHeap* pHeap=(MemoryHeap*)((char*)pMem-sizeof(HeapHeader));
- if(pHeap->header.size>MAX_SIZE){
- ::free(pHeap);
- return true;
- }
- return false;
- }
- private:
- MemoryChunk** pChunkList;
- int chunkcount;
- };
- #endif
ObejctManager.h文件,用于实现对象的创建与管理,比较简易。
- #ifndef OBJECT_MANAGER_H
- #define OBJECT_MANAGER_H
- #include "StaticMemory.h"
- /** @class ObjectManager
- * 实现利用内存池创建对象
- * 要求对象具有缺省构造函数
- */
- template<typename T>
- class ObjectManager
- {
- public:
- typedef T ObjectType;
-
- static ObjectType* Create(StaticMemory* pool)
- {
- void* pobject=pool->Malloc(sizeof(T));
- new(pobject) ObjectType();
- return static_cast<ObjectType*>(pobject);
- }
- static void Delete(StaticMemory* pool, ObjectType* pobject)
- {
- pobject->~ObjectType();
- pool->Free(pobject);
- }
- };
- #endif
测试结果:
分单线程和多线程进行测试,重复的内存分配与释放在实际使用中是不太可能的,为了模拟实际使用,通过随机数来确定分配内存大小,同时也通过随机数来确定分配与释放操作。在测试过程中限制最大分配大小为1024,目的是为了测试小内存块的分配情况对比。
内存池单线程测试结果
| 分配与释放次数 | malloc/free | 内存池 |
|---|
| 100,000 |
0.01s |
0.01s |
| 1,000,000 |
0.15s |
0.11s |
| 10,000,000 |
1.26s |
0.60s |
| 100,000,000 |
9.21s |
5.99s |
| 1,000,000,000 |
92.70s |
61.46s |
内存池多线程测试结果
| 线程数目 |
malloc/free |
内存池 |
| 1/1,000,000 |
0.15s |
0.10s |
| 2/1,000,000 |
1.49s |
0.73s |
| 4/1,000,000 |
9.945s |
6.71s |
| 8/1,000,000 |
45.60s |
28.82s |
进行多线程测试主要是测试多线程运行下,加锁给内存分配带来的影响,因此为了排除CPU的影响,测试采用的机器为16盒,16G内存的Linux服务器。
具体配置如下:
Intel(R) Xeon(R) CPU E5630 @ 2.53GHz
stepping : 2
cpu MHz : 2527.084
cache size : 12288 KB
http://www.cppblog.com/weiym/archive/2013/04/08/199238.html
总结下常见的C++内存池,以备以后查询。
应该说没有一个内存池适合所有的情况, 根据不同的需求选择正确的内存池才是正道.
(1)最简单的固定大小缓冲池
适用于频繁分配和释放固定大小对象的情况, 关于这个内存池,我这里总结过:一个高效的内存池实现
(2)dlmalloc
应该来说相当优秀的内存池, 支持大对象和小对象,并且已被广泛使用。到这里下载:ftp://g.oswego.edu/pub/misc/malloc.c
关于dlmalloc的内部原理和使用资料可以参考:内存分配器dlmalloc 2.8.3源码浅析.doc
(3) SGI STL 中的内存分配器( allocator )
SGI STL 的 allocator 应该是目前设计最优秀的 C++ 内存分配器之一了,它的运作原理候捷老师在《 STL 源码剖析》里讲解得非常清楚。基本思路是设计一个 free_list[16] 数组,负责管理从 8 bytes 到 128 bytes 不同大小的内存块( chunk ),每一个内存块都由连续的固定大小( fixed size block )的很多 chunk 组成,并用指针链表串接起来。比如说
free_list[3]->start_notuse->next_notuse->next_notuse->...->end_notuse;
当用户要获取此大小的内存时,就在 free_list 的链表找一个最近的 free chunk 回传给用户,同时将此 chunk 从 free_list 里删除,即把此 chunk 前后 chunk 指针链结起来。用户使用完释放的时候,则把此chunk 放回到 free_list 中,应该是放到最前面的 start_free 的位置。这样经过若干次 allocator 和 deallocator 后, free_list 中的链表可能并不像初始的时候那么是 chunk 按内存分布位置依次链接的。假如free_list 中不够时, allocator 会自动再分配一块新的较大的内存区块来加入到 free_list 链表中。
可以自动管理多种不同大小内存块并可以自动增长的内存池,这是 SGI STL 分配器设计的特点。
(4) Loki 中的小对象分配器( small object allocator )
Loki 的分配器与 SGI STL 的原理类似,不同之处是它管理 free_list 不是固定大小的数组,而是用一个 vector 来实现,因此可以用户指定 fixed size block 的大小,不像 SGI STL 是固定最大 128 bytes 的。另外它管理 free chunks 的方式也不太一样, Loki 是由一列记录了 free block 位置等信息的 Chunk 类的链表来维护的, free blocks 则是分布在另外一个连续的大内存区间中。而且 free Chunks 也可以根据使用情况自动增长和减少合适的数目,避免内存分配得过多或者过少。
(5) Boost 的 object_pool
Boost 中的 object_pool 也是一个可以根据用户具体应用类的大小来分配内存块的,也是通过维护一个 free nodes 的链表来管理的。可以自动增加 nodes 块,初始是 32 个 nodes ,每次增加都以两倍数向 system heap 要内存块。 object_pool 管理的内存块需要在其对象销毁的时候才返还给 system heap 。
(6)ACE 中的 ACE_Cached_Allocator 和 ACE_Free_List
ACE 框架中也有一个可以维护固定大小的内存块的分配器,原理与上面讲的内存池都差不多。它是通过在 ACE_Cached_Allocator 中定义个 Free_list 链表来管理一个连续的大内存块的,里面包含很多小的固定大小的未使用的区块( free chunk ),同时还使用 ACE_unbounded_Set 维护一个已使用的 chuncks ,管理方式与上面讲的内存池类似。也可以指定 chunks 的数目,也可以自动增长,定义大致如下所示:
template<class T>
class ACE_Cached_Allocator : public ACE_New_Allocator<T> {
public:
// Create a cached memory pool with @a n_chunks chunks
// each with sizeof (TYPE) size.
ACE_Cached_Allocator(SIZET n_chunks = ACE_DEFAULT_INIT_CHUNKS);
T* allocate();
void deallocate(T* p);
private:
// List of memory that we have allocated.
Fast_Unbounded_Set<char *> _allocated_chunks;
// Maintain a cached memory free list.
ACE_Cached_Free_List<ACE_Cached_Mem_Pool_Node<T> > _free_list;
};
(7)TCMalloc
Google的开源项目gperftools, 主页在这里:https://code.google.com/p/gperftools/,该内存池也被大家广泛好评,并且在google的各种开源项目中被使用, 比如webkit就用到了它。
http://blog.chinaunix.net/uid-479984-id-2114952.html
http://blog.csdn.net/060/archive/2006/10/08/1326025.aspx
原文作者: DanDanger2000.
原文链接: http://www.codeproject.com/cpp/MemoryPool.asp
C++ 内存池
l 下载示例工程 – 105Kb
l 下载源代码 – 17.3Kb
目录
l 引言
l 它怎样工作
l 示例
l 使用这些代码
l 好处
l 关于代码
l ToDo
l 历史
引言
C/C++的内存分配(通过malloc或new)可能需要花费很多时。
更糟糕的是,随着时间的流逝,内存(memory)将形成碎片,所以一个应用程序的运行会越来越慢当它运行了很长时间和/或执行了很多的内存分配(释放)操作的时候。特别是,你经常申请很小的一块内存,堆(heap)会变成碎片的。
解决方案:你自己的内存池
一个(可能的)解决方法是内存池(Memory Pool)。
在启动的时候,一个”内存池”(Memory Pool)分配一块很大的内存,并将会将这个大块(block)分成较小的块(smaller chunks)。每次你从内存池申请内存空间时,它会从先前已经分配的块(chunks)中得到,而不是从操作系统。最大的优势在于:
l 非常少(几没有) 堆碎片
l 比通常的内存申请/释放(比如通过malloc, new等)的方式快
另外,你可以得到以下好处:
l 检查任何一个指针是否在内存池里
l 写一个”堆转储(Heap-Dump)”到你的硬盘(对事后的调试非常有用)
l 某种”内存泄漏检测(memory-leak detection)”:当你没有释放所有以前分配的内存时,内存池(Memory Pool)会抛出一个断言(assertion).
它怎样工作
让我们看一看内存池(Memory Pool)的UML模式图:
这个模式图只显示了类CMemoryPool的一小部分,参看由Doxygen生成的文档以得到详细的类描述。
一个关于内存块(MemoryChunks)的单词
你应该从模式图中看到,内存池(Memory Pool)管理了一个指向结构体SMemoryChunk (m_ptrFirstChunk, m_ptrLastChunk, and m_ptrCursorChunk)的指针。这些块(chunks)建立一个内存块(memory chunks)的链表。各自指向链表中的下一个块(chunk)。当从操作系统分配到一块内存时,它将完全的被SMemoryChunks管理。让我们近一点看看一个块(chunk)。
typedef struct SMemoryChunk
{
TByte *Data ; // The actual Data
std::size_t DataSize ; // Size of the "Data"-Block
std::size_t UsedSize ; // actual used Size
bool IsAllocationChunk ; // true, when this MemoryChunks
// Points to a "Data"-Block
// which can be deallocated via "free()"
SMemoryChunk *Next ; // Pointer to the Next MemoryChunk
// in the List (may be NULL)
} SmemoryChunk;
每个块(chunk)持有一个指针,指针指向:
l 一小块内存(Data),
l 从块(chunk)开始的可用内存的总大小(DataSize),
l 实际使用的大小(UsedSize),
l 以及一个指向链表中下一个块(chunk)的指针。
第一步:预申请内存(pre-allocating the memory)
当你调用CmemoryPool的构造函数,内存池(Memory Pool)将从操作系统申请它的第一块(大的)内存块(memory-chunk)
/*Constructor
******************/
CMemoryPool::CMemoryPool(const std::size_t &sInitialMemoryPoolSize,
const std::size_t &sMemoryChunkSize,
const std::size_t &sMinimalMemorySizeToAllocate,
bool bSetMemoryData)
{
m_ptrFirstChunk = NULL ;
m_ptrLastChunk = NULL ;
m_ptrCursorChunk = NULL ;
m_sTotalMemoryPoolSize = 0 ;
m_sUsedMemoryPoolSize = 0 ;
m_sFreeMemoryPoolSize = 0 ;
m_sMemoryChunkSize = sMemoryChunkSize ;
m_uiMemoryChunkCount = 0 ;
m_uiObjectCount = 0 ;
m_bSetMemoryData = bSetMemoryData ;
m_sMinimalMemorySizeToAllocate = sMinimalMemorySizeToAllocate ;
// Allocate the Initial amount of Memory from the Operating-System...
AllocateMemory(sInitialMemoryPoolSize) ;
}
类的所有成员通用的初始化在此完成,AllocateMemory最终完成了从操作系统申请内存。
/******************
AllocateMemory
******************/
bool CMemoryPool::AllocateMemory(const std::size_t &sMemorySize)
{
std::size_t sBestMemBlockSize = CalculateBestMemoryBlockSize(sMemorySize) ;
// allocate from Operating System
TByte *ptrNewMemBlock = (TByte *) malloc (sBestMemBlockSize) ;
...
那么,是如何管理数据的呢?
第二步:已分配内存的分割(segmentation of allocated memory)
正如前面提到的,内存池(Memory Pool)使用SMemoryChunks管理所有数据。从OS申请完内存之后,我们的块(chunks)和实际的内存块(block)之间就不存在联系:
Memory Pool after initial allocation
我们需要分配一个结构体SmemoryChunk的数组来管理内存块:
// (AllocateMemory()continued) :
...
unsigned int uiNeededChunks = CalculateNeededChunks(sMemorySize) ;
// allocate Chunk-Array to Manage the Memory
SMemoryChunk *ptrNewChunks =
(SMemoryChunk *) malloc ((uiNeededChunks * sizeof(SMemoryChunk))) ;
assert(((ptrNewMemBlock) && (ptrNewChunks))
&& "Error : System ran out of Memory") ;
...
CalculateNeededChunks()负责计算为管理已经得到的内存需要的块(chunks)的数量。分配完块(chunks)之后(通过malloc),ptrNewChunks将指向一个SmemoryChunks的数组。注意,数组里的块(chunks)现在持有的是垃圾数据,因为我们还没有给chunk-members赋有用的数据。内存池的堆(Memory Pool-"Heap"):
Memory Pool after SMemoryChunk allocation
还是那句话,数据块(data block)和chunks之间没有联系。但是,AllocateMemory()会照顾它。LinkChunksToData()最后将把数据块(data block)和chunks联系起来,并将为每个chunk-member赋一个可用的值。
// (AllocateMemory()continued) :
...
// Associate the allocated Memory-Block with the Linked-List of MemoryChunks
return LinkChunksToData(ptrNewChunks, uiNeededChunks, ptrNewMemBlock) ;
让我们看看LinkChunksToData():
/******************
LinkChunksToData
******************/
bool CMemoryPool::LinkChunksToData(SMemoryChunk *ptrNewChunks,
unsigned int uiChunkCount, TByte *ptrNewMemBlock)
{
SMemoryChunk *ptrNewChunk = NULL ;
unsigned int uiMemOffSet = 0 ;
bool bAllocationChunkAssigned = false ;
for(unsigned int i = 0; i < uiChunkCount; i++)
{
if(!m_ptrFirstChunk)
{
m_ptrFirstChunk = SetChunkDefaults(&(ptrNewChunks[0])) ;
m_ptrLastChunk = m_ptrFirstChunk ;
m_ptrCursorChunk = m_ptrFirstChunk ;
}
else
{
ptrNewChunk = SetChunkDefaults(&(ptrNewChunks[i])) ;
m_ptrLastChunk->Next = ptrNewChunk ;
m_ptrLastChunk = ptrNewChunk ;
}
uiMemOffSet = (i * ((unsigned int) m_sMemoryChunkSize)) ;
m_ptrLastChunk->Data = &(ptrNewMemBlock[uiMemOffSet]) ;
// The first Chunk assigned to the new Memory-Block will be
// a "AllocationChunk". This means, this Chunks stores the
// "original" Pointer to the MemBlock and is responsible for
// "free()"ing the Memory later....
if(!bAllocationChunkAssigned)
{
m_ptrLastChunk->IsAllocationChunk = true ;
bAllocationChunkAssigned = true ;
}
}
return RecalcChunkMemorySize(m_ptrFirstChunk, m_uiMemoryChunkCount) ;
}
让我们一步步地仔细看看这个重要的函数:第一行检查链表里是否已经有可用的块(chunks):
...
if(!m_ptrFirstChunk)
...
我们第一次给类的成员赋值:
...
m_ptrFirstChunk = SetChunkDefaults(&(ptrNewChunks[0])) ;
m_ptrLastChunk = m_ptrFirstChunk ;
m_ptrCursorChunk = m_ptrFirstChunk ;
...
m_ptrFirstChunk现在指向块数组(chunks-array)的第一个块,每一个块严格的管理来自内存(memory block)的m_sMemoryChunkSize个字节。一个”偏移量”(offset)——这个值是可以计算的所以每个(chunk)能够指向内存块(memory block)的特定部分。
uiMemOffSet = (i * ((unsigned int) m_sMemoryChunkSize)) ;
m_ptrLastChunk->Data = &(ptrNewMemBlock[uiMemOffSet]) ;
另外,每个新的来自数组的SmemoryChunk将被追加到链表的最后一个元素(并且它自己将成为最后一个元素):
...
m_ptrLastChunk->Next = ptrNewChunk ;
m_ptrLastChunk = ptrNewChunk ;
...
在接下来的"for loop" 中,内存池(memory pool)将连续的给数组中的所有块(chunks)赋一个可用的数据。
Memory and chunks linked together, pointing to valid data
最后,我们必须重新计算每个块(chunk)能够管理的总的内存大小。这是一个费时的,但是在新的内存追加到内存池时必须做的一件事。这个总的大小将被赋值给chunk的DataSize 成员。
/******************
RecalcChunkMemorySize
******************/
bool CMemoryPool::RecalcChunkMemorySize(SMemoryChunk *ptrChunk,
unsigned int uiChunkCount)
{
unsigned int uiMemOffSet = 0 ;
for(unsigned int i = 0; i < uiChunkCount; i++)
{
if(ptrChunk)
{
uiMemOffSet = (i * ((unsigned int) m_sMemoryChunkSize)) ;
ptrChunk->DataSize =
(((unsigned int) m_sTotalMemoryPoolSize) - uiMemOffSet) ;
ptrChunk = ptrChunk->Next ;
}
else
{
assert(false && "Error : ptrChunk == NULL") ;
return false ;
}
}
return true ;
}
RecalcChunkMemorySize之后,每个chunk都知道它指向的空闲内存的大小。所以,将很容易确定一个chunk是否能够持有一块特定大小的内存:当DataSize成员大于(或等于)已经申请的内存大小以及DataSize成员是0,于是chunk有能力持有一块内存。最后,内存分割完成了。为了不让事情太抽象,我们假定内存池(memory pool )包含600字节,每个chunk持有100字节。
Memory segmentation finished. Each chunk manages exactly 100 bytes
第三步:从内存池申请内存(requesting memory from the memory pool)
那么,如果用户从内存池申请内存会发生什么?最初,内存池里的所有数据是空闲的可用的:
All memory blocks are available
我们看看GetMemory:
/******************
GetMemory
******************/
void *CMemoryPool::GetMemory(const std::size_t &sMemorySize)
{
std::size_t sBestMemBlockSize = CalculateBestMemoryBlockSize(sMemorySize) ;
SMemoryChunk *ptrChunk = NULL ;
while(!ptrChunk)
{
// Is a Chunks available to hold the requested amount of Memory ?
ptrChunk = FindChunkSuitableToHoldMemory(sBestMemBlockSize) ;
if (!ptrChunk)
{
// No chunk can be found
// => Memory-Pool is to small. We have to request
// more Memory from the Operating-System....
sBestMemBlockSize = MaxValue(sBestMemBlockSize,
CalculateBestMemoryBlockSize(m_sMinimalMemorySizeToAllocate)) ;
AllocateMemory(sBestMemBlockSize) ;
}
}
// Finally, a suitable Chunk was found.
// Adjust the Values of the internal "TotalSize"/"UsedSize" Members and
// the Values of the MemoryChunk itself.
m_sUsedMemoryPoolSize += sBestMemBlockSize ;
m_sFreeMemoryPoolSize -= sBestMemBlockSize ;
m_uiObjectCount++ ;
SetMemoryChunkValues(ptrChunk, sBestMemBlockSize) ;
// eventually, return the Pointer to the User
return ((void *) ptrChunk->Data) ;
}
当用户从内存池中申请内存是,它将从链表搜索一个能够持有被申请大小的chunk。那意味着:
l 那个chunk的DataSize必须大于或等于被申请的内存的大小;
l 那个chunk的UsedSize 必须是0。
这由 FindChunkSuitableToHoldMemory 方法完成。如果它返回NULL,那么在内存池中没有可用的内存。这将导致AllocateMemory 的调用(上面讨论过),它将从OS申请更多的内存。如果返回值不是NULL,一个可用的chunk被发现。SetMemoryChunkValues会调整chunk成员的值,并且最后Data指针被返回给用户...
/******************
SetMemoryChunkValues
******************/
void CMemoryPool::SetMemoryChunkValues(SMemoryChunk *ptrChunk,
const std::size_t &sMemBlockSize)
{
if(ptrChunk)
{
ptrChunk->UsedSize = sMemBlockSize ;
}
...
}
示例
假设,用户从内存池申请250字节:
Memory in use
如我们所见,每个内存块(chunk)管理100字节,所以在这里250字节不是很合适。发生了什么事?Well,GetMemory 从第一个chunk返回 Data指针并把它的UsedSize设为300字节,因为300字节是能够被管理的内存的最小值并大于等于250。那些剩下的(300 - 250 = 50)字节被称为内存池的"memory overhead"。这没有看起来的那么坏,因为这些内存还可以使用(它仍然在内存池里)。
当FindChunkSuitableToHoldMemory搜索可用chunk时,它仅仅从一个空的chunk跳到另一个空的chunk。那意味着,如果某个人申请另一块内存(memory-chunk),第四块(持有300字节的那个)会成为下一个可用的("valid") chunk。
Jump to next valid chunk
使用代码
使用这些代码是简单的、直截了当的:只需要在你的应用里包含"CMemoryPool.h",并添加几个相关的文件到你的IDE/Makefile:
- CMemoryPool.h
- CMemoryPool.cpp
- IMemoryBlock.h
- SMemoryChunk.h
你只要创建一个CmemoryPool类的实例,你就可以从它里面申请内存。所有的内存池的配置在CmemoryPool类的构造函数(使用可选的参数)里完成。看一看头文件("CMemoryPool.h")或Doxygen-doku。所有的文件都有详细的(Doxygen-)文档。
应用举例
MemPool::CMemoryPool *g_ptrMemPool = new MemPool::CMemoryPool() ;
char *ptrCharArray = (char *) g_ptrMemPool->GetMemory(100) ;
...
g_ptrMemPool->FreeMemory(ptrCharArray, 100) ;
delete g_ptrMemPool ;
好处
内存转储(Memory dump)
你可以在任何时候通过WriteMemoryDumpToFile(strFileName)写一个"memory dump"到你的HDD。看看一个简单的测试类的构造函数(使用内存池重载了new和delete运算符):
/******************
Constructor
******************/
MyTestClass::MyTestClass()
{
m_cMyArray[0] = ‘H‘ ;
m_cMyArray[1] = ‘e‘ ;
m_cMyArray[2] = ‘l‘ ;
m_cMyArray[3] = ‘l‘ ;
m_cMyArray[4] = ‘o‘ ;
m_cMyArray[5] = NULL ;
m_strMyString = "This is a small Test-String" ;
m_iMyInt = 12345 ;
m_fFloatValue = 23456.7890f ;
m_fDoubleValue = 6789.012345 ;
Next = this ;
}
MyTestClass *ptrTestClass = new MyTestClass ;
g_ptrMemPool->WriteMemoryDumpToFile("MemoryDump.bin") ;
看一看内存转储文件("MemoryDump.bin"):
如你所见,在内存转储里有MyTestClass类的所有成员的值。明显的,"Hello"字符串(m_cMyArray)在那里,以及整型数m_iMyInt (3930 0000 = 0x3039 = 12345 decimal)等等。这对调式很有用。
速度测试
我在Windows平台上做了几个非常简单的测试(通过timeGetTime()),但是结果说明内存池大大提高了应用程序的速度。所有的测试在Microsoft Visual Studio .NET 2003的debug模式下(测试计算机: Intel Pentium IV Processor (32 bit), 1GB RAM, MS Windows XP Professional).
//Array-test (Memory Pool):
for(unsigned int j = 0; j < TestCount; j++)
{
// ArraySize = 1000
char *ptrArray = (char *) g_ptrMemPool->GetMemory(ArraySize) ;
g_ptrMemPool->FreeMemory(ptrArray, ArraySize) ;
}
//Array-test (Heap):
for(unsigned int j = 0; j < TestCount; j++)
{
// ArraySize = 1000
char *ptrArray = (char *) malloc(ArraySize) ;
free(ptrArray) ;
}
Results for the "array-test
//Class-Test for MemoryPool and Heap (overloaded new/delete)
//Class-Test for MemoryPool and Heap (overloaded new/delete)
for(unsigned int j = 0; j < TestCount; j++)
{
MyTestClass *ptrTestClass = new MyTestClass ;
delete ptrTestClass ;
}
Results for the "classes-test" (overloaded new/delete operators)
关于代码
这些代码在Windows和Linux平台的下列编译器测试通过:
- Microsoft Visual C++ 6.0
- Microsoft Visual C++ .NET 2003
- MinGW (GCC) 3.4.4 (Windows)
- GCC 4.0.X (Debian GNU Linux)
Microsoft Visual C++ 6.0(*.dsw, *.dsp)和Microsoft Visual C++ .NET 2003 (*.sln, *.vcproj)的工程文件已经包含在下载中。内存池仅用于ANSI/ISO C++,所以它应当在任何OS上的标准的C++编译器编译。在64位处理器上应当没有问题。
注意:内存池不是线程安全的。
ToDo
这个内存池还有许多改进的地方;-) ToDo列表包括:
l 对于大量的内存,memory-"overhead"能够足够大。
l 某些CalculateNeededChunks调用能够通过从新设计某些方法而去掉
l 更多的稳定性测试(特别是对于那些长期运行的应用程序)
l 做到线程安全。
历史
l 05.09.2006: Initial release
EoF
DanDanger2000
内存池
标签:
原文地址:http://www.cnblogs.com/virusolf/p/4482315.html