标签:
Hadoop中MapReduce 的执行也是采用Master/Slave 主从结构的方式。其中JobTracker 充当了Master的角色,而TaskTracker 充当了Slave 的角色。Master负责接受客户端提交的Job,然后调度Job的每一个子任务Task运行于Slave上,并监控它们。如果发现所有失败的Task就重新运行它,slave则负责直接执行每一个Task。
当Hadoop启动的时候,JobTracker 是作为单独的一个JVM来运行的。JobTracker 会一直等待JobClient通过RPC来提交作业,它调度处理JobClient提交的每一个任务,并监控它们的运行。当发现有失败的任务的时候,JobTracker会重新执行它。而且 TaskTracker 会一直向JobTracker发送心跳,询问JobTracker是否有任务需要处理。
当有作业从JobClient 提交给JobTracker 后,JobTracker 处理JobClient所提交的作业的流程如下:
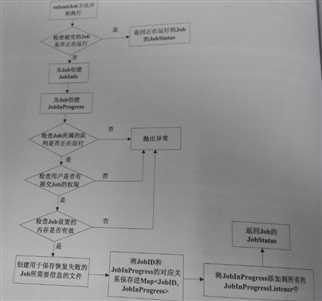
下面我将简单介绍其中几个部分:
1.创建Job的JobInProgress
JobInProgress对象详细的记录了Job的配置信息,以及它的执行情况,确切的来说应该是Job被分解的map、reduce任务。在JobInProgress对象的创建过程中,它主要干了两件事,一是把Job的job.xml、job.jar文件从Job目录copy到JobTracker的本地文件系统(job.xml->*/jobTracker/jobid.xml,job.jar->*/jobTracker/jobid.jar);二是创建JobStatus和Job的mapTask、reduceTask存队列来跟踪Job的状态信息。
2.检查客户端是否有权限提交Job
JobTracker验证客户端是否有权限提交Job实际上是交给QueueManager来处理的,关于QueueManager是如何验证客户端对Job有哪些操作,我将会写一篇博文详细的讨论这个问题。
3.检查当前mapreduce集群能够满足Job的内存需求
客户端提交作业之前,会根据实际的应用情况配置作业任务的内存需求,同时JobTracker为了提高作业的吞吐量会限制作业任务的内存需求,所以在Job的提交时,JobTracker需要检查Job的内存需求是否满足JobTracker的设置。
详细代码如下:
private void checkMemoryRequirements(JobInProgress job) throws IOException { if (!perTaskMemoryConfigurationSetOnJT()) { LOG.debug("Per-Task memory configuration is not set on JT. " + "Not checking the job for invalid memory requirements."); return; } boolean invalidJob = false; String msg = ""; long maxMemForMapTask = job.getJobConf().getMemoryForMapTask(); //获取Job的map任务内存需求 long maxMemForReduceTask = job.getJobConf().getMemoryForReduceTask();//获取Job的reduce任务内存需求 if (maxMemForMapTask == JobConf.DISABLED_MEMORY_LIMIT || maxMemForReduceTask == JobConf.DISABLED_MEMORY_LIMIT) { invalidJob = true; msg = "Invalid job requirements."; } if (maxMemForMapTask > limitMaxMemForMapTasks || maxMemForReduceTask > limitMaxMemForReduceTasks) { invalidJob = true; msg = "Exceeds the cluster‘s max-memory-limit."; } if (invalidJob) { StringBuilder jobStr = new StringBuilder().append(job.getJobID().toString()).append("(") .append(maxMemForMapTask).append(" memForMapTasks ").append( maxMemForReduceTask).append(" memForReduceTasks): "); LOG.warn(jobStr.toString() + msg); throw new IOException(jobStr.toString() + msg); } }
JobTracker的全局变量limitMaxMemForMapTasks 和limitMaxMemForReduceTasks可以通过配置文件来设置,它们分别对应配置文件中的mapred.cluster.max.map.memory.mb项和mapred.cluster.max.reduce.memory.mb项。
参考 ----http://www.linuxidc.com/Linux/2012-01/50860.htm
Hadoop 学习笔记四--JobTracker 的执行过程
标签:
原文地址:http://www.cnblogs.com/geekszhong/p/4483342.html