标签:
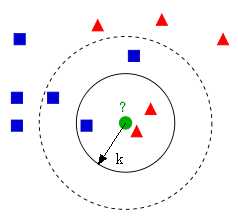
k近邻(k-NearestNeighbor)算法简称kNN。基本思想简单直接,对于一个需要分类的数据实例x,计算x与所有已知类别的样本点在特征空间中的距离。取与x距离最近的k个样本点,统计这些样本点所属占比最大的类别,作为x的分类结果。下图中与绿色点最近的3个点中,2个属于红色类别,则认为x属于红色的类。然而当k=5时,则认为绿色点属于蓝色类别。
下面的实例来自《机器学习实战》。
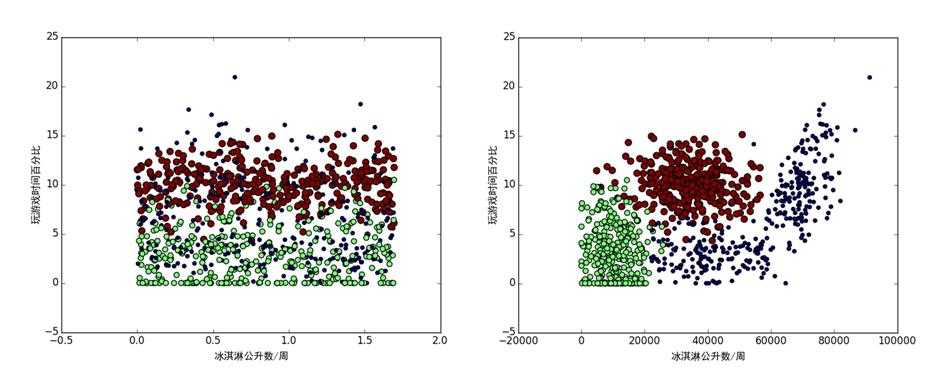
一个女性收集了约会网站中的男人的三个属性作为特征:每年飞行里程、每月打游戏时间的占比,每周消费冰淇淋公升数。她将曾经约会的男人打上标签:不喜欢、一般魅力,极具魅力。为了决定是否跟一个新的男人约会,她想在见面前判断这个男人是不是自己喜欢的类型。下面来两幅图分别是{每月打游戏时间的占比,消费冰淇淋公升数}、{每月打游戏时间的占比,每年飞行里程}的二维图形展示。可以看出使用{每月打游戏时间的占比,每年飞行里程}可以较好地将男人分成三类。
生成图形的代码:
datingDataMat, datingLabels = kNN.file2matrix("datingTestSet2.txt")
#print(datingDataMat)
#print(datingLabels[0:20])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1], 20.0*array(datingLabels), 15.0*array(datingLabels))
plt.xlabel(u"冰淇淋公升数/周", fontproperties=‘SimHei‘)
plt.ylabel(u"玩游戏时间百分比", fontproperties=‘SimHei‘)
plt.show()
kNN算法流程图:
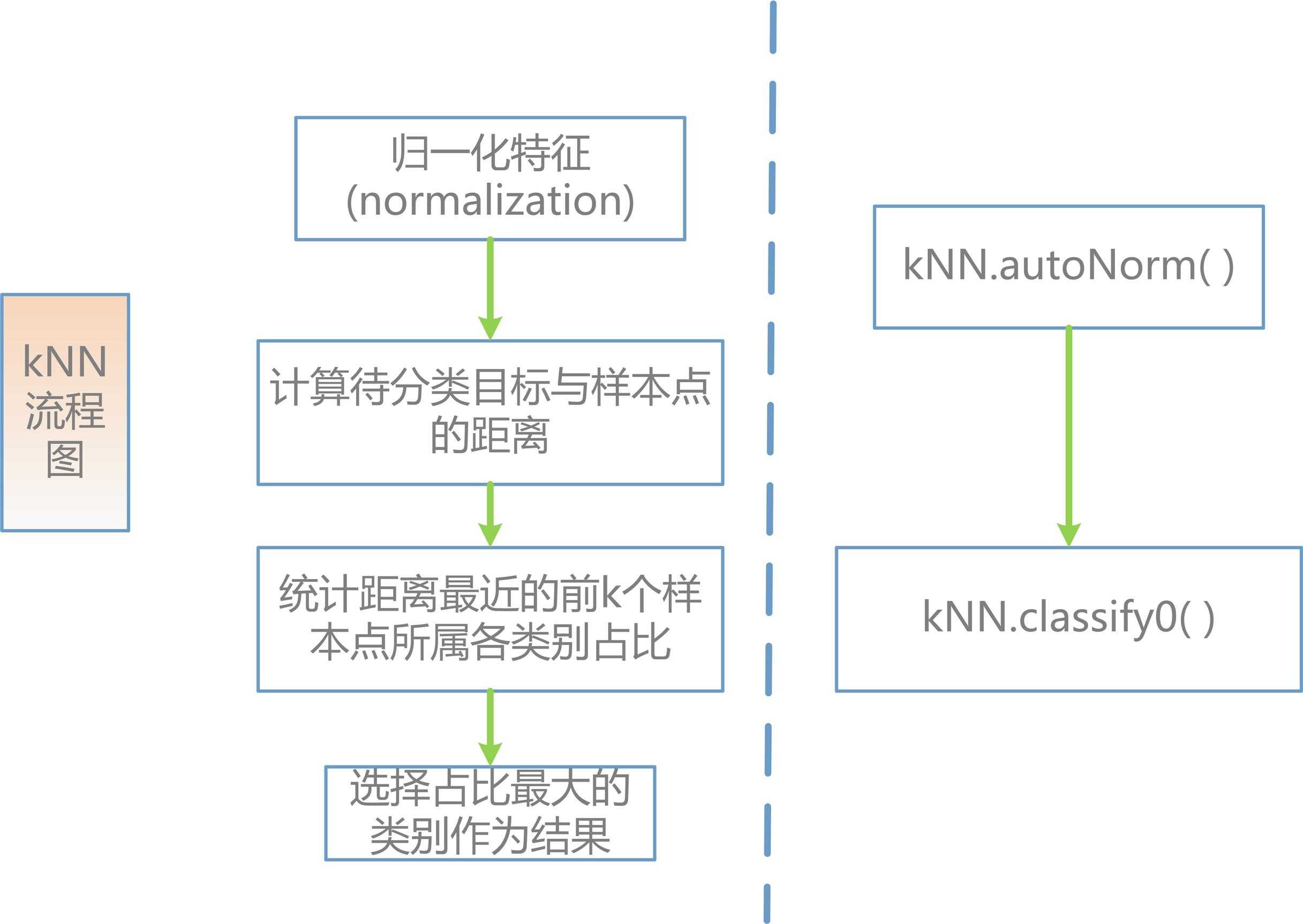
值得注意的是在最开始的时候要将个特征值进行归一化,否则在计算样本点与待分类点的距离时将由于个各征的数值的相对大小不同而导致错误。
下面的代码选择datingTestSet2.txt中的一半作为已标记样本集合,对另外一半的样本进行分类。设置k=3,分类正确率为92%。设置k=10时,分类正确率几乎不变,观察{每月打游戏时间的占比,每年飞行里程}的散点图,我认为是处在在分类边界上的点导致了分类的正确率无法进一步提升。
normMat, ranges, minVals = kNN.autoNorm(datingDataMat)
#print(‘normMat: ‘, normMat)
#print(‘ranges: ‘, ranges)
#print(‘minVals‘, minVals)
length = normMat.shape[0]
ratio =0.8
numSample = int(ratio*length)
numtest = length - numSample
errCnt =0
for i in range(numtest):
val = kNN.classify0(normMat[i,:], normMat[numtest:length,:], datingLabels[numtest:length], 10)
if(val != datingLabels[i]):
errCnt +=1
precision = 1-errCnt/numtest
print(‘precision of prediction:‘, precision)
kNN算法分析:
kNN算法简单有效,对异常数据不敏感,无数据输入假定。且可以处理分类以及回归问题(对于回归问题,可以将最近的k个点的均值作为该点的预测值)。然而,kNN算法需要保存已知样本集,空间复杂度高;由于需要对每个待分类点计算与所有已知样本点的距离,时间复杂度高。不仅如此,k近邻算法只注重分类点在特征空间中位置信息,并没有去真正理解数据的内在含义。
标签:
原文地址:http://www.cnblogs.com/universe42/p/4484598.html