标签:
这个月初,正式开始做大数据相关工作,关于这一块,自己也是初生毛驴,不过慢慢来吧。
大数据)
大数据大数据大数据,都特么被说烂了的词语,在做这个工作之前,我对它有诸多不解,并且我相信很多没有接触的人,一定会有和我一样的底层基础问题。
例如)hadoop输入源哪儿来:hadoop也是一个被玩烂的了的词语,我这边和ibm合作,由ibm提供硬件和hadoop环境,我们负责写hadoop的job,关于hadoop是干嘛的,如何搭建各种hadoop环境,网上早已经是烂大街,各种helloworld也是遍地都是,各种大神针对hadoop的各种文章五花八门,在之前我也看了非常多的hadoop文章,但是有一个问题至始至终都没有提到:所有的hadoop的文章都是把那个统计词语个数的例子拿来翻来覆去的讲,创建一个txt文本,然后去分析它,但是没有一个人提到,这个txt怎么来的,我们生产库是mysql,oracle这些关系库,它和txt没有半毛钱的关系,里面的数据如何交给hadoop分析?就是这么简单基础的问题,也许是我领悟低,各路大神都不屑于讲它,但它在我之前,就是实实在在困扰我的问题。
elasticsearch)
一)精确搜索
因为做的是数据分析的问题,所以搜索是一个精确查找的问题,当然不能使用联想搜索法,于是很自然的干掉分词法,但是我们知道,es自带smartcn分词法,也就是说不管如何,它都会给你分词,这可不是我想要的,放眼网上一看,都是如何使用第三方分词法替代es自己的分词法,像我这样的需求还真不好找。经过到大半夜的摸索,源码在手,何惧之有?找出三个解决办法:
1)删掉文件:不同es版本文件位置不一样,直接搜索smartcn删除所有相关分词文件,当然有风险。
2)创建序列的时候声明不分词:我们在创建es索引的时候,都是startObject()的方法,于是我们在里面增加filed,声明index为
not_analyzed,则能不使用分词,当然这个也有弊端,那就是如果有一天需要分词的时候,就需要重新创建索引了。
3)修改输入:这个方法乃上上之策,也是非常非常简单,那就是在es里面,如果你的字符串是被双引号括起来,那么es就认为是一个原子,不会被分词,也就是我们需要转义引号,一起作为搜索字符串传递给es,这个简单点办法,发现之后我居然仰天长啸,你个二b es,这个神气你居然藏着掖着。
二)es的filter
es的fiter着实让我纠结,由于时间有限,我需要在实现not的搜索,也就是不包含某个结果,我们知道在es里面使用queryBuilder条件去设定过滤条件,会出现长度溢出,最好的做法当然是filter,于是很自然的创建了filter:
BoolFilterBuilder notFilter = FilterBuilders.boolFilter().mustNot(FilterBuilders.termsFilter("body", "fedde").cache(false));
在es里面的filter有两类,not,or,and等这一类,还有一类是bool等这一类,他们的区别就是是否会使用es内部核心大数组,在性能下优先考虑bool类,因为它会使用内部数组,这个filter有个核心的坑就是仅仅只有body完全等于输入字符串的时候,才能被not,我觉得es不会没有解决这个问题,或许是我没有发现,时间有限,直接手动修改hits。。
三)es的and
我们在实现es的and功能的时候,一般也是建立filter,并且es内部提供了and操作,我们理想的and操作就是将我们的多个输入得到并结果,于是filter的建立如下:
QueryFilterBuilder queryFilterBuilder = FilterBuilders.queryFilter(QueryBuilders.multiMatchQuery(value, eachStringQueryRequest.getQueryFiled()).operator(MatchQueryBuilder.Operator.AND).minimumShouldMatch(Global.MARCHPERCENT));
但是结果却始终不正确,都是or的结果,于是我一度恼火,后来发现这个坑,妈蛋的,multiMatchQuery这个方法传递两个参数,一个是object的输入,一个是可变长的es的filed的名字,原来es的and,是and它的可变长filed,而不是我们自己的多个输入。
四)感悟
所谓数据分析挖掘,自己的感觉就是从同一个通道进去,每个人根据自己不同的角色,配置不同的工作流,从数据源里面产生自己需要的分析报告,所有人用的四同一个数据同一个通道,但是根据不同的需求,能够产生不同的结果,就是这么简单。。。
五)小东西还的玩
在还没有做大数据的时候,我就有一个想法,那就是我们从出生到死去,所有的人生记录都被记录在不同的系统,甚至我们的每一次刷卡每一次买书每一次上厕所都有登记,那么只要我们能够合并这些数据,就能够计算一个人的人生轨迹。。
这个数据有啥好处?当然我们有了这些数据,我们就可以逆向计算出一个人的成长,分析一个人的梦想。。
比如:
我输入10年后要成为科学家,那么系统能够根据足够的例子计算出,8年后要达到什么水平,5年后要成为什么,3年内要得到什么经验,从而推出今年应该考取什么证书,现在应该开始读哪本书。。。。
六)书不能不读
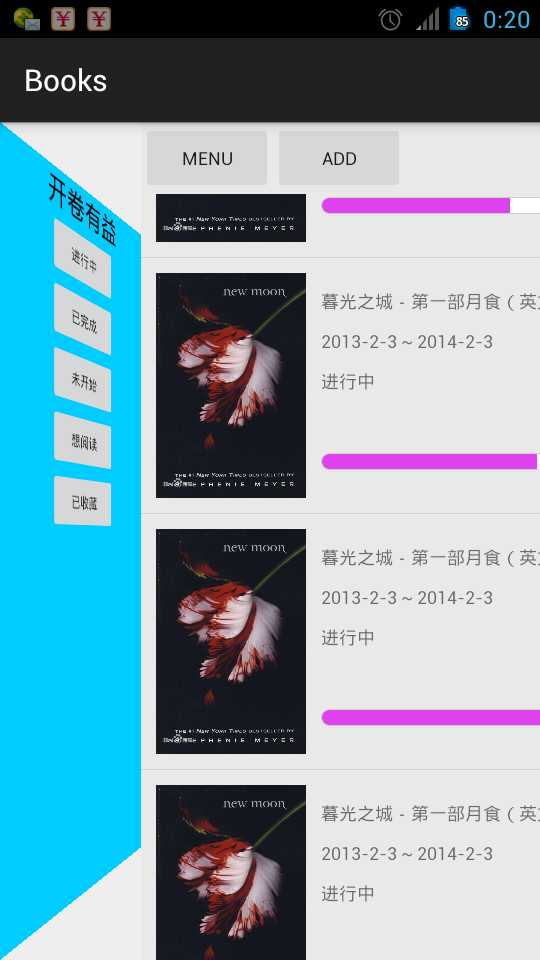
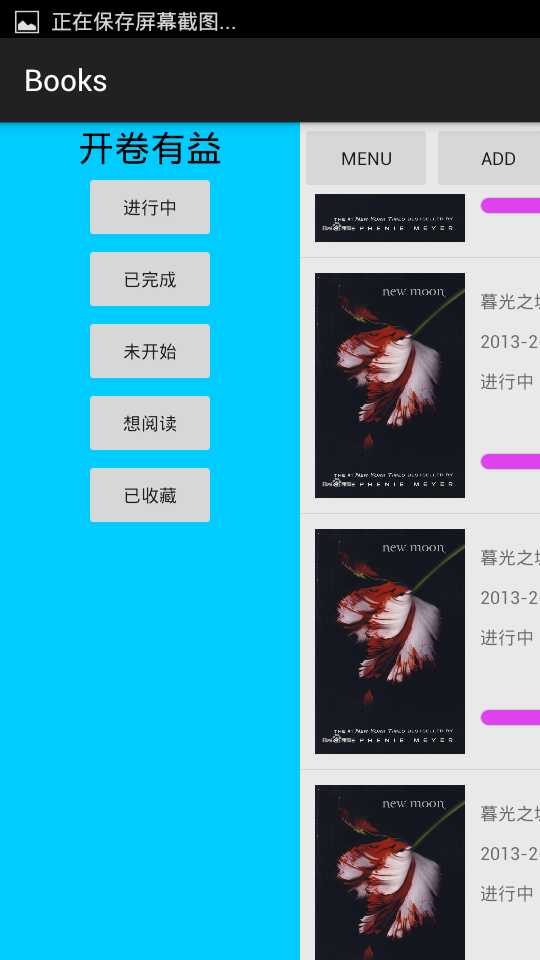
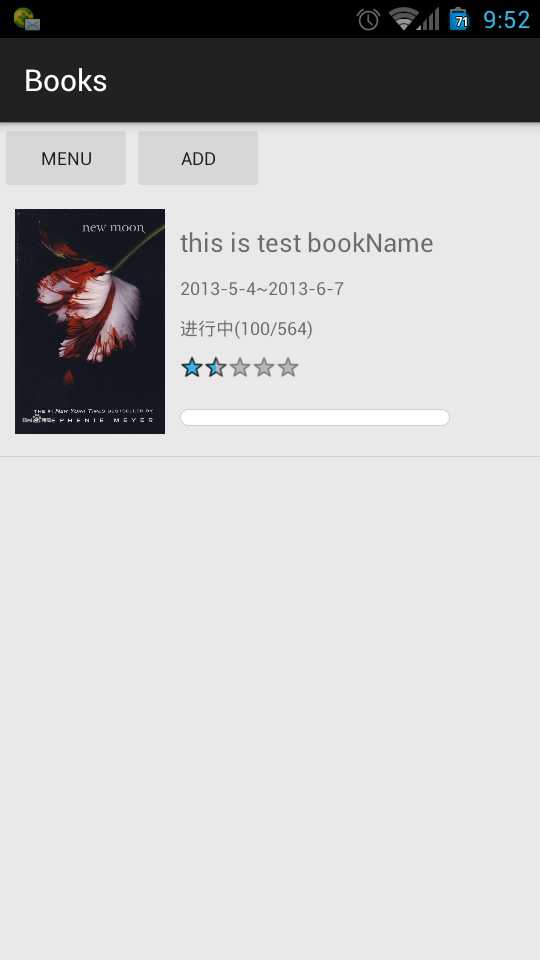
一直以来自己都想给自己量身做一款app用来定制自己的作息时间与学习轨迹,但是做了很多都不满意,都删除了,最近打算只做读书记录这一块,功能很简单,记录某本书读到那个位置,预定在哪个时间段读取哪本书,并且到点了提醒读书,没了。。
android5的控件ui很漂亮,代码丢在:点击到github代码位置。。
刚刚起步开始写,后面慢慢push代码吧,毕竟个人爱好嘛,留几张图:
(原)解决elasticsearch在大数据中应用的精确度问题
标签:
原文地址:http://www.cnblogs.com/bfchuan/p/4485864.html