标签:style class blog code java http
本文基于FPGA和CPLD器件,采用非流水线和流水线技术实现8位加法器,并对比其Quartus II仿真结果和波形时序。
器件选择:
Stratix:EP1S40F1020C5(FPGA)
MAX7000S:EPM7064SLC44-5(CPLD)
程序清单:

1 /*******************8位加法器(非流水线)***********************/ 2 module adder_nonpipe(cout, sum, ina, inb, cin, enable); 3 4 output cout; 5 output [7:0] sum; 6 input [7:0] ina, inb; 7 input cin, enable; 8 9 reg cout; 10 reg [7:0] sum; 11 reg [7:0] tempa, tempb; 12 reg tempc; 13 14 always @(posedge enable) 15 begin 16 tempa = ina; 17 tempb = inb; 18 tempc = cin; 19 end 20 21 always @(posedge enable) 22 begin 23 {cout,sum} = tempa + tempb + tempc; 24 end 25 26 endmodule
Compilation编译报告如图1所示:
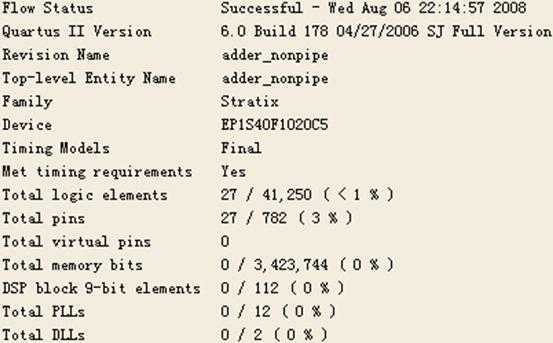
图1 8位加法器(非流水线/FPGA)编译结果
RTL Viewer 提供设计的逻辑门级原理图和层次结构列表,列出整个设计网表的实例、基本单元、引脚和网络。可过滤显示在视图上的信息,浏览设计视图的不同页面来检查设计并确定应当作的更改。实验一的RTL原理图如图2所示:
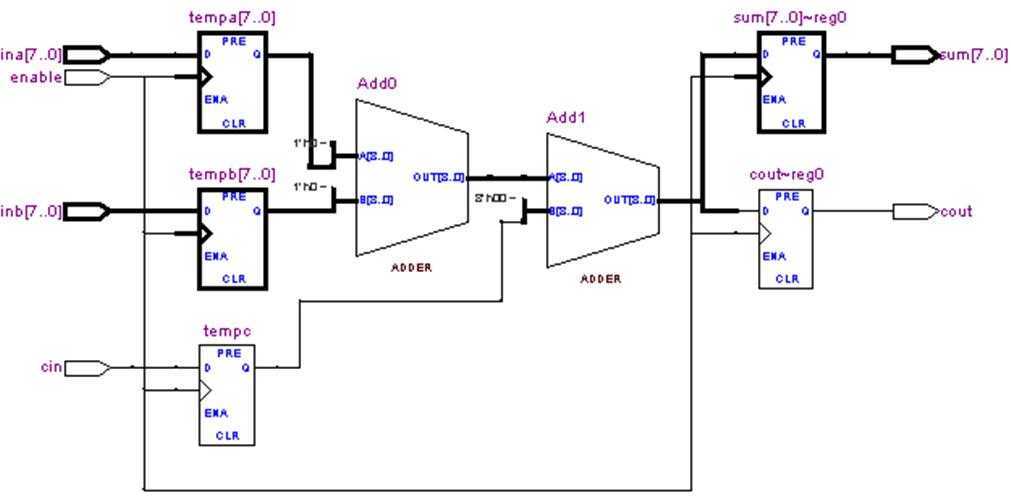
图2 8位加法器(非流水线/FPGA)RTL Viewer
Technology Map Viewer 提供设计的底层或基元级特定技术原理表征。它包括一个原理视图,以及一个层次列表,列出整个设计网表的实例、基本单元、引脚和网络。实验一的Techology Map Viewer结果如图3所示:
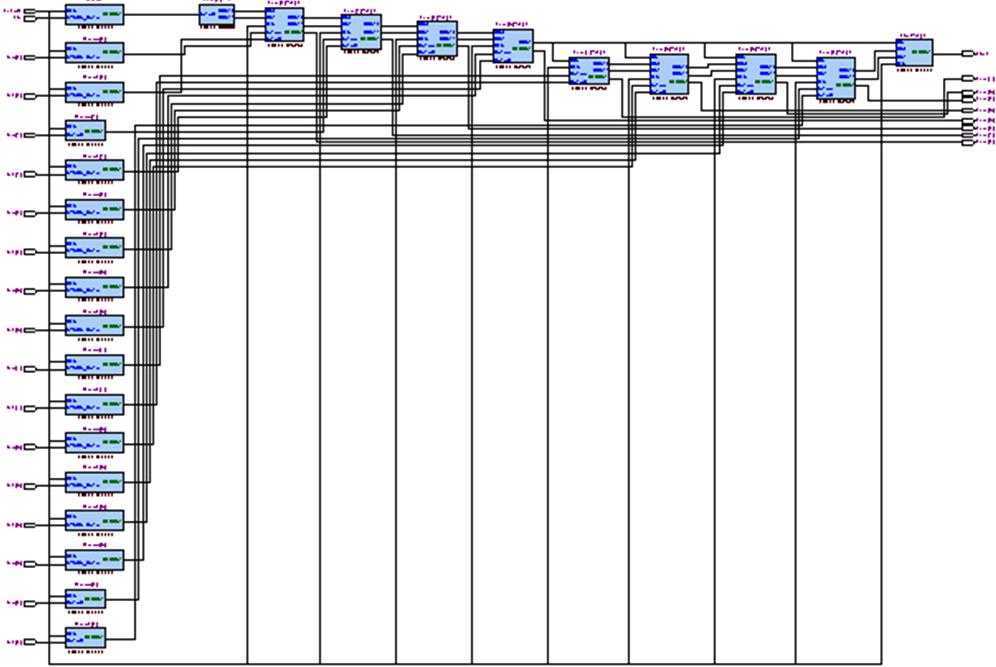
图3 8位加法器(非流水线/FPGA)Techology Map Viewer
Simulation仿真波形如图4所示:
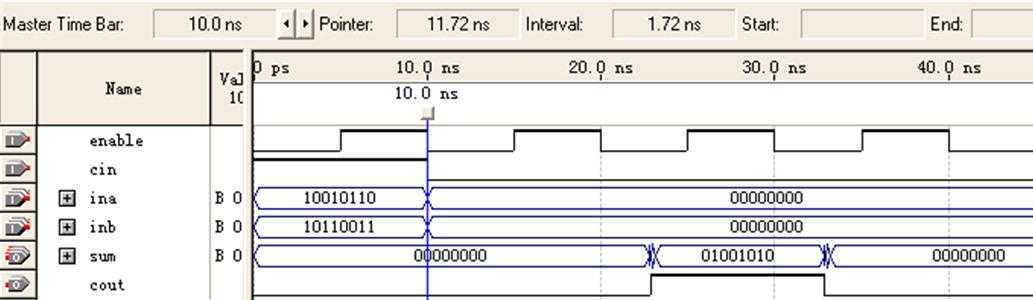
图4 8位加法器(非流水线/FPGA)仿真图
程序清单:
1 /*******************8位2级流水加法器*************************/ 2 module adder_pipeline(cout, sum, ina, inb, cin, enable); 3 4 output cout; 5 output [7:0] sum; 6 input [7:0] ina, inb; 7 input cin, enable; 8 9 reg cout; 10 reg [7:0] sum; 11 12 reg [3:0] tempa, tempb, firsts; 13 reg firstc; 14 always @(posedge enable) 15 begin 16 {firstc,firsts} = ina[3:0] + inb[3:0] + cin; 17 tempa = ina[7:4]; //高4位输入寄存,使其与sum低4位在下级流水线同步输入。
tempb = inb[7:4]; //否则sum的高4位,与低四位分两个时钟周期输出 18 end 19 20 always @(posedge enable) 21 begin 22 {cout,sum[7:4]} = tempa + tempb + firstc; 23 sum[3:0] = firsts; //不能合并为{cout, sum} = {tempa + tempb + firstc, firsts}; 位宽不匹配 24 end 25 26 endmodule
另一个可用版本主体代码如下:
1 reg [4:0] tempa,tempb; 2 reg [3:0] firsts; 3 reg firstc; 4 5 always @(posedge enable) begin //低4 位相加; 6 { firstc, firsts} = {ina[3], ina[3:0]} + {inb[3], inb[3:0]} + cin ; 7 tempa = {ina[7], ina[7:4]}; //似乎应该高位补零即{1’b0, ina[7:4]};才对 8 tempb = {inb[7], inb[7:4]}; 9 end 10 11 always @(posedge enable) begin //高4 位相加,并连成8位 12 {cout, sum} = {tempa + tempb + firstc, firsts} ; 13 end
注:设ina为Mbit,inb为Nbit,则{cout, sum}=a+b为M+N+1位,其中cout占1位,sum为M+N位。
编译后Total Logic Element为24个。
RTL原理图如图5所示:
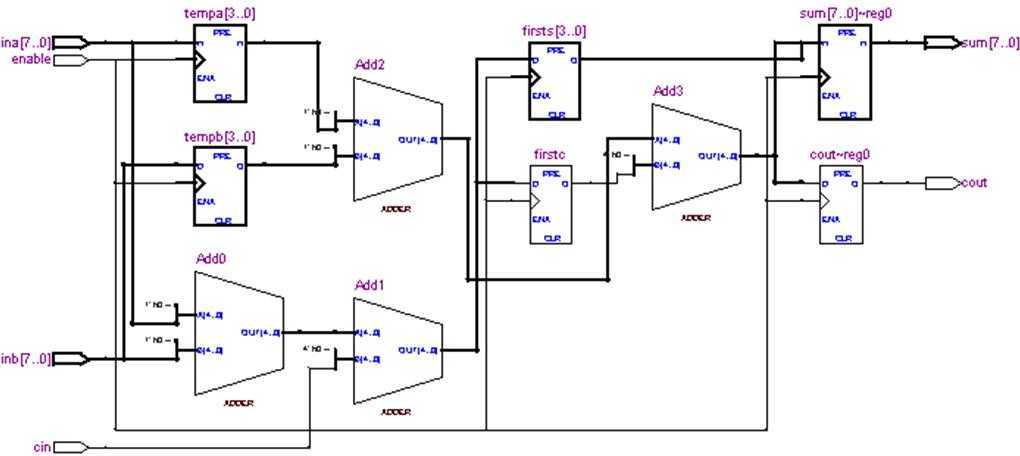
图5 8位加法器(2级流水线/FPGA)RTL Viewer
Techology Map Viewer结果如图6所示:
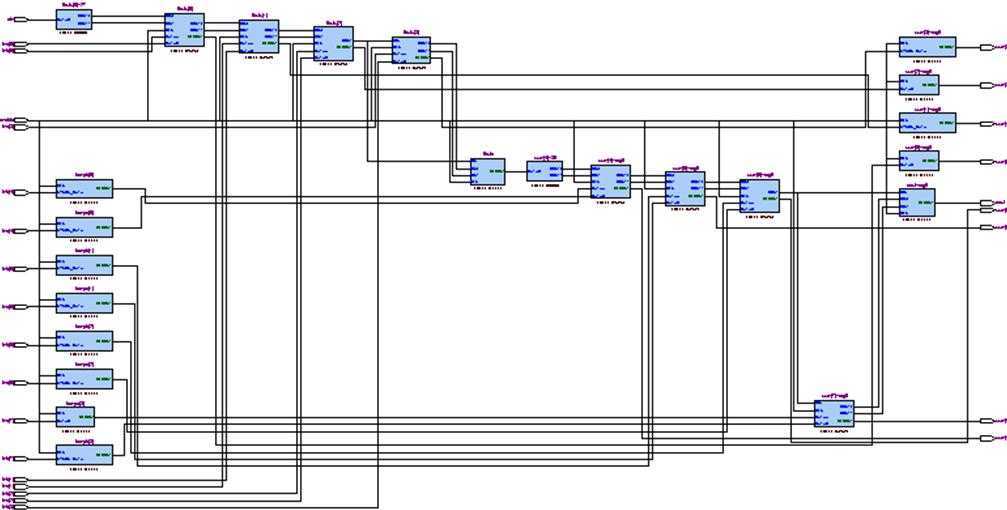
图6 8位加法器(2级流水线/FPGA)Techology Map Viewer
Simulation仿真波形如图7所示:
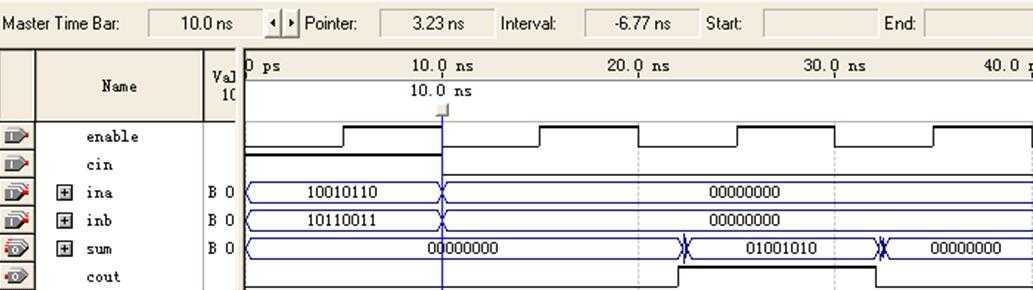
图7 8位加法器(2级流水线/FPGA)仿真图
程序清单(单always):
1 /*******************8位加法器(非流水线)***********************/ 2 module adder_nonpipe(cout, sum, ina, inb, cin, enable); 3 4 output cout; 5 output [7:0] sum; 6 input [7:0] ina, inb; 7 input cin, enable; 8 9 reg cout; 10 reg [7:0] sum; 11 12 always @(posedge enable) 13 begin 14 {cout,sum} = ina + inb + cin; 15 end 16 17 endmodule
将Device替换为CPLD器件。在Project Navigator->Hierarchy窗口器件处右键->Device,即可打开器件选择框,选择所需的器件确定即可。此处选择"MAX7000S:EPM7064SLC44-5"。
Compilation编译报告如图8所示:
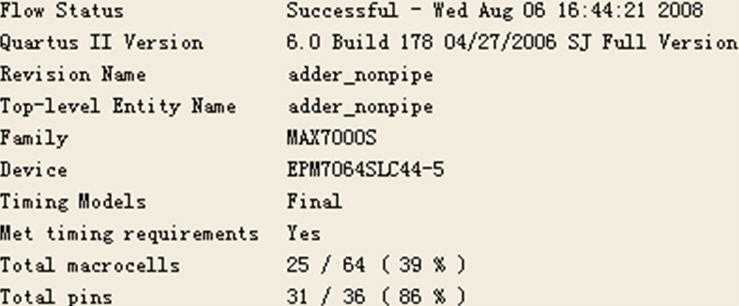
图8 8位加法器(非流水线/CPLD)编译结果
Simulation仿真波形如图9所示:
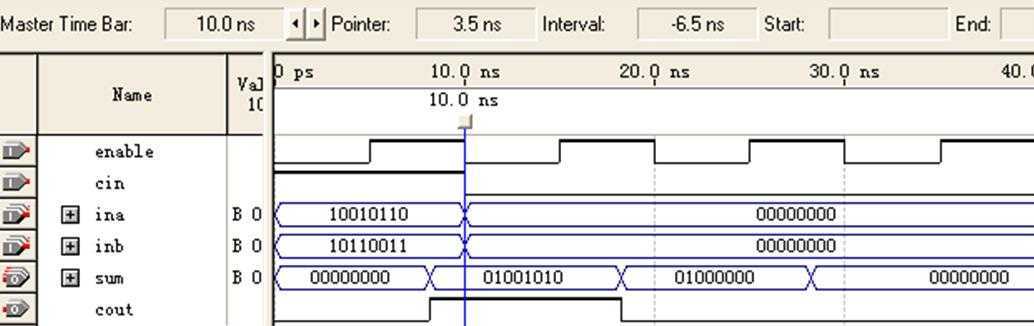
图9 8位加法器(非流水线/CPLD)仿真图-1
接着考虑双always形式的加法器(程序同实验一,仅器件不同):
Compile编译后,Total Macrocell为42个。
仍采用周期为10ns的时钟enable,仿真结果如图10所示:
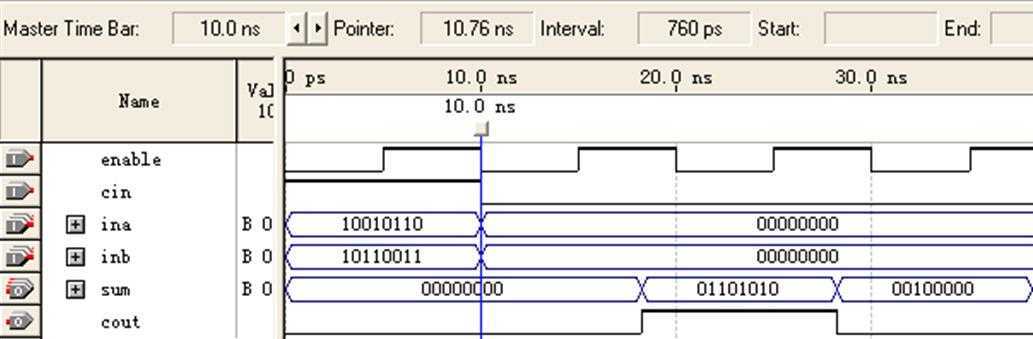
图10 8位加法器(非流水线/CPLD)仿真图-2
显然sum值不正确。
展开Compilation Report下面的Timing Analyzer,多了一项Clock Setup ‘enable’。从右侧报告窗口可观察到最长(最差时序)路径需要13.5ns,对应fmax为74.07MHz,也就是最高工作频率。
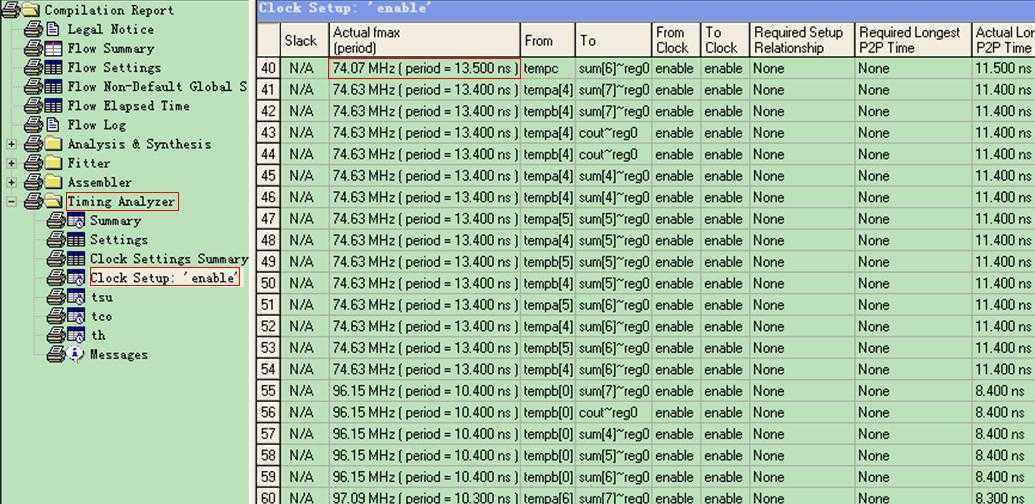
图11 8位加法器(非流水线/CPLD)时序分析结果
将时钟周期改为13.5ns,重新运行仿真,结果如图12所示:
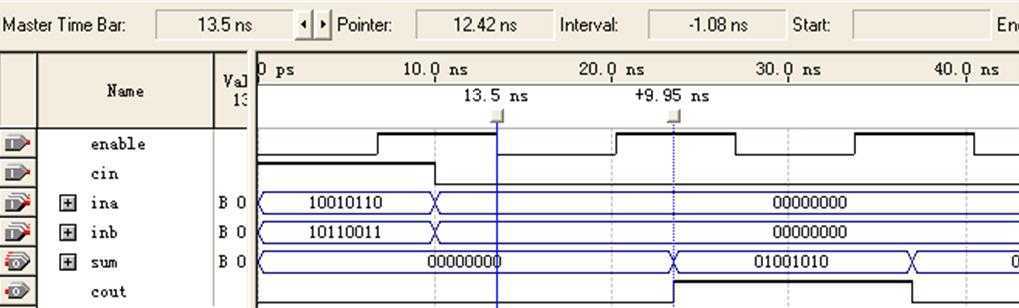
图12 8位加法器(非流水线/CPLD)仿真图-3
注意:
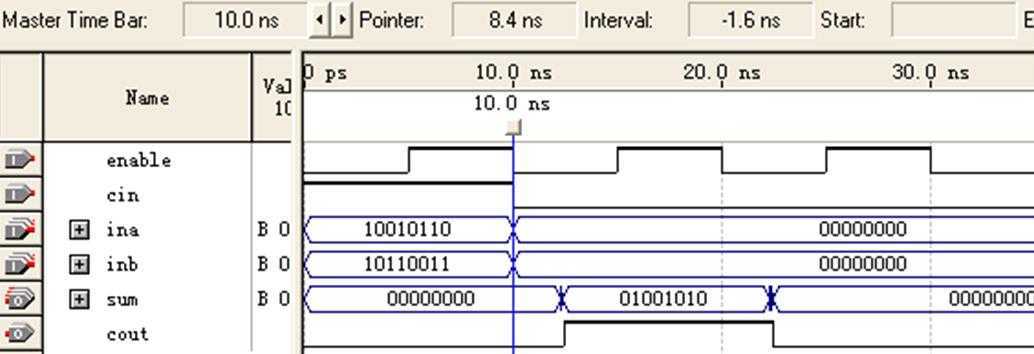
图13 8位加法器(非流水线/CPLD)仿真图-4
这也符合通常习惯,即一个时钟沿周期采样,下一个时钟沿输出。
程序同实验二,器件选择同实验三。
编译后Total Macrocell为32个。
在Timing Analyzer详细报告窗口可观察到那些影响周期恶化的最差时序路径,根据这些信息可找出关键路径并进行时序分析。图14显示Clock Period为9.700ns,Frequency为103.09MHz。
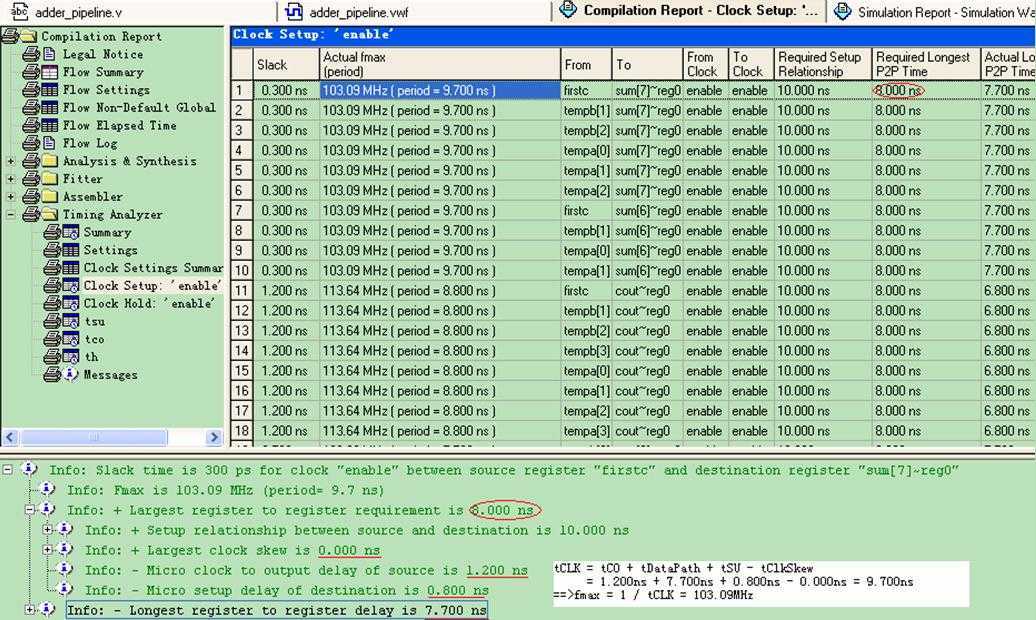
图14 8位加法器(非流水线/CPLD)时序分析结果
观察第一条路径的时序报告,如图15所示:
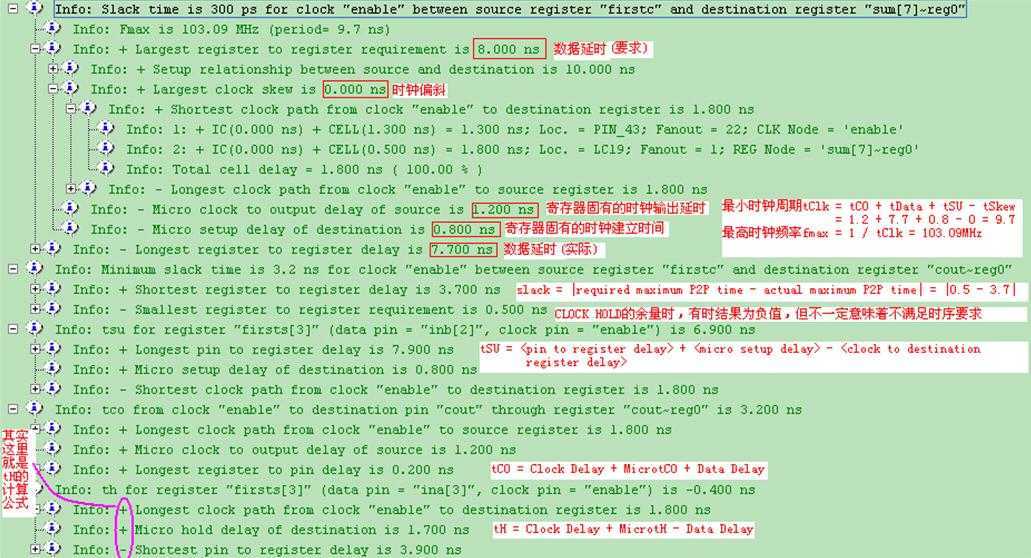
图15 8位加法器(2级流水线/CPLD)时序报告(局部)
时钟周期为10ns时,仿真波形如图16所示:
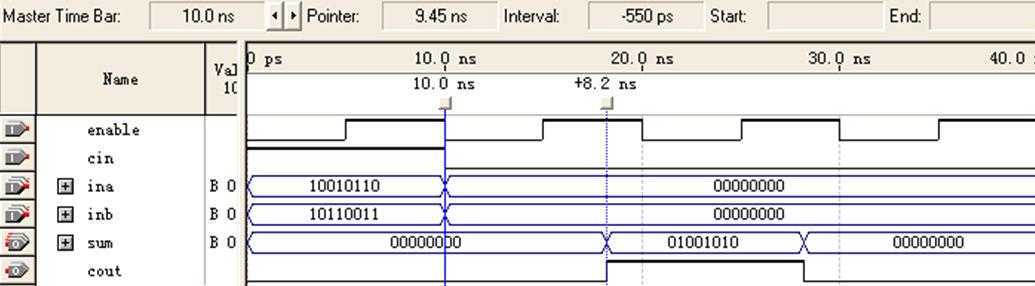
图16 8位加法器(2级流水线/CPLD)仿真图
该波形与实验三单always程序波形最主要的差别在于,sum=01001010之后一个周期的值是否正确。
当时钟周期取10ns时,仿真波形与实验三双always程序波形相同,但最高工作频率却由74.07 MHz提高到103.09MHz。可见最高工作频率(系统工作速度)不能单纯由仿真波形判断。
1. FPGA中1个逻辑单元(Logic Element )相当于CPLD中0.78个宏单元(MacroCell).
2. Quartus II中FPGA器件编译速度比CPLD慢得多。
3. Stratix的最高工作频率大于MAX7000S的的最高工作频率。如实验一二中Timing Analysis Tool均显示Frequency为Restricted to 422.12 MHz(这时不易比较采用流水线和非流水线的最高频率)。
4. 比较实验一(非流水线)和实验二(流水线)的RTL原理图及工艺映射图,可清楚地看到,流水线技术的本质是在组合逻辑之间插入寄存器,暂存前面的运算结果或输入数据,并在下一个时钟到来时将寄存值作为后一级运算的输入。将流水线规则应用于FPGA中,只需要很少或根本不需要额外的成本。这是因为每个逻辑单元都包含两个触发器,大多数情况下这两个触发器或者没有用到,或者用于存储布线资源,那么就可利用其来实现流水线结构。若采用流水线后,加法器速度仍不能满足需要,可采用串并转换来进一步提高计算的并行度。
标签:style class blog code java http
原文地址:http://www.cnblogs.com/clover-toeic/p/3784105.html