标签:
SQL Server的查询优化器是基于开销的优化器、它通过确认选择性、数据的唯一性以及过滤数据(通过WHERE或JOIN子句)所使用的列来决定最佳的数据访问机制。统计与索引一同存在,但是它们也作为断言的一部分存在于没有索引的列上。
作为谓词引用的列中数据分布的最新信息帮助优化器确定所使用的查询策略。在SQL Server中,这个信息以统计的形式维护,这对于基于开销的优化器创建一个有效的查询执行计划是很重要的。通过统计,优化器能做出返回结果集或中间结果集所花费时间的精确估计,从而确定最高效的操作。只要确定数据库已经进行了默认的统计设置,优化器就能尽其所能地动态确定有效的处理策略。而且,作为性能问题诊断时的安全性度量,应该确定自动统计维护历程正在按照预想工作。如果有必要,甚至手工控制统计的创建或维护。
索引的有效性完全取决于索引列上的统计。如果没有统计,SQL Server的基于开销的查询优化器将不能选择到使用索引最有效的方式。
SQL Server默认会自动创建索引键的统计,不管它是何时创建的。
我们知道,随着数据的变化,保持查询低开销的数据检索机制也会变化。例如,如果一个表对于某个列的值的选择性相当高为0.99,那么通过该列上的非聚集索引来检索匹配行是有意义的。但是如果表中数据变化,添加了大量该列有相同值的行选择性下降,那么使用这个非聚集索引就不再有意义。
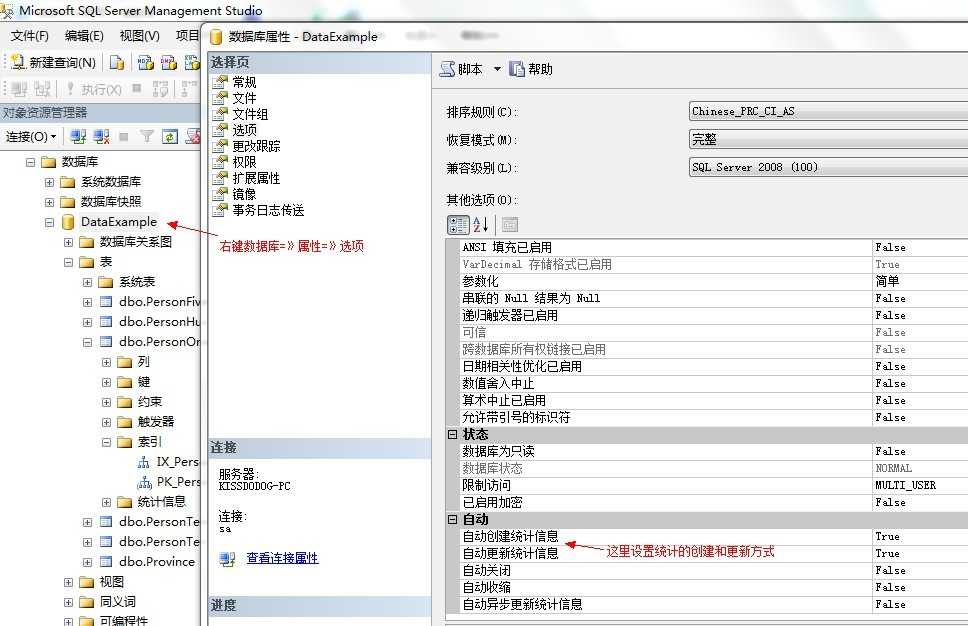
SQL Server可以使一个索引上的统计随着索引列内容变化而更新。默认情况下,这个特性被开启,而且可以通过属性=》选项=》数据库的自动更新统计设置来开启或关闭。
更新统计消耗额外的CPU周期。为了优化和更新进行,SQL Server使用如下高效的算法来确定合适的更新统计时机:
这种内建的智能使每个进程的CPU利用率保持很低。也可以异步地更新统计。这意味着当查询正常地导致统计更新时,查询使用旧的统计继续,统计被离线更新。这可以加速一些查询的响应时间,比如在数据库很大或超时间隔很短时。
可以使用ALTER DATABASE命令手工禁用(或启用)自动更新统计和异步更新统计特性,默认情况下,自动更新统计特性被启用(强烈建议保持启用)。自动异步更新统计特性默认下被禁用,只有确定它能在数据库上对超时有帮助时才开启这一特性。
1、更新统计的好处以及过时统计的缺点示例
执行自动更新的好处通常要超过其在系统资源上的开销,自动更新统计能够有效帮助SQL Server查询优化器获得最佳的数据访问途径。
为了更直接地控制数据的行为,下面来搞个示例实战下,我们有一张Person表,里面有1万条数据左右。
Id列原本是主键,但现在被撤掉了,因此选择性非常高,我们来看看如下SQL语句的执行计划与数据页读取情况:
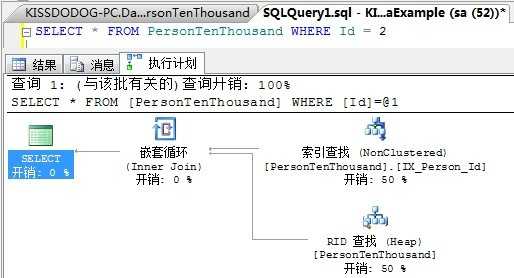
由执行计划来看,这是一个典型的书签查找,查询返回1条记录,有效地使用了索引。
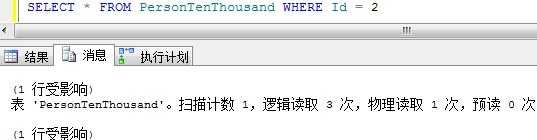
下面,我们来插入3000条Id为2的记录:

DECLARE @i int; SET @i = 0; WHILE (@i < 3000) BEGIN INSERT INTO PersonTenThousand (Id,PId,Name) VALUES(2,3,‘相同Id号‘) SET @i = @i + 1; END
注意:由于SQL Server的索引更新机制,大于500条数据的情况下,插入数量要大于20%的情况下,才会自动更新索引。
现在再来执行相同的语句以及查询计划:
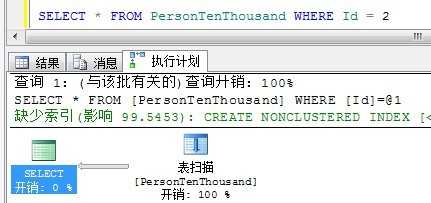
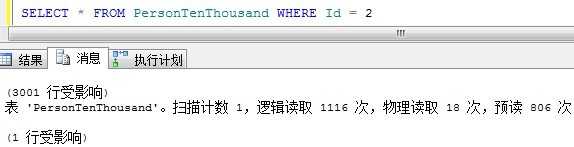
我们看到,由于索引的自动更新机制,执行计划改变了,SQL Server认为对于返回3000条记录,使用表扫描要优于执行3000次书签查找。
下面,我们来重复一次,先删除原有的3000条Id为2的记录,这次我们先关闭索引统计再插入3000条记录。
--关闭自动统计索引 ALTER DATABASE DataExample SET AUTO_UPDATE_STATISTICS OFF
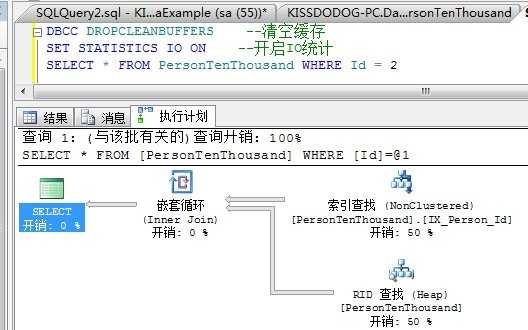
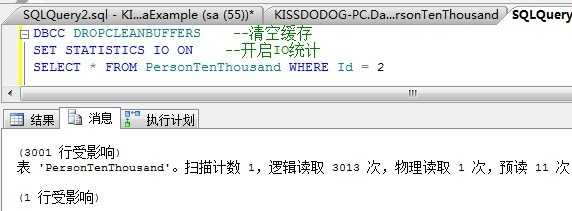
我们看到,索引统计的不更新,导致SQL Server仍然使用原来的执行计划,进行了3000多次查找,逻辑读上升。
这是为什么呢?因为统计不更新了,SQL Server并不知道Id=2多了3000条记录,还是以为Id=2的记录只有一条,因此就使用了索引进行书签查找。
小结:过时的索引统计会导致SQL Server根据旧的统计执行计划,而实际上这些执行计划在数据更新后可能并不是最优的。因此,最好保持索引的自动更新。
标签:
原文地址:http://www.cnblogs.com/mingxuantongxue/p/4488838.html